Mistral: Voxtral TTS, Forge, Leanstral y lo que sigue para Mistral 4 — con Pavan Kumar Reddy y Guillaume Lample
Mistral ha estado en pleno apogeo: con frecuentes lanzamientos exitosos de modelos, es fácil olvidar que el año pasado crearon la ronda europea de IA más grande de la historia. Hacía tiempo que debíamos ver un episodio de Mistral y fuimos muy afortunados de trabajar con Sophia y Howard para ponernos al día con Pavan (líder de Voxtral) y Guillaume (científico jefe, cofundador) con motivo del lanzamiento de Voxtral TTS de esta semana:
Mistral no puede decirlo directamente, pero los puntos de referencia implican que sabe trata básicamente de un modelo TTS de nivel abierto de ElevenLabs (técnicamente, es un modelo de pesos abiertos TTS multilingüe de baja latencia basado en 4B Ministral que tiene una tasa de ganancia del 68,4 % frente a ElevenLabs Flash v2.5). Las contribuciones no sabe encuentran solo en las ponderaciones abiertas sino también en la investigación abierta: también dedicamos una cantidad decente del módulo a hablar sobre su arquitectura que combina la generación autorregresiva de tokens de habla semántica con la coincidencia de flujo para tokens acústicos (normalmente solo sabe aplica en el espacio de generación de imágenes, como sabe ve en el taller Flow Matching NeurIPS de los autores principales a los que hacemos referencia en el módulo).
¡Puedes ponerte al día con el periódico aquí y el episodio completo está en vive en YouTube!
Marcas de tiempo
00:00 Bienvenida e invitados 00:22 Anuncio de Voxtral TTS 01:41 Arquitectura y códec 02:53 Comprensión frente a generación 05:39 Coincidencia de flujo para audio 07:27 Agentes de voz en tiempo real 13:40 Eficiencia y estrategia de modelo 14:53 Visión de los agentes de voz 17:56 Implementación y privacidad empresarial 23:39 Ajuste fino y personalización 25:22 Empresa Personalización de voz 26:09 Modelos de voz de formato largo 26:58 Avances del codificador en tiempo real 27:45 Contexto de escala para TTS 28:53 Qué hace que los modelos sean pequeños 30:37 Fusión de modalidades y compensaciones 33:05 Misión de código abierto 35:51 Pruebas formales y ajustadas 38:40 Transferencia de razonamiento y agentes 40:25 Próximas fronteras en la capacitación 42:20 Contratación e inteligencia artificial para la ciencia 44:19 Ingeniería implementada en el futuro 46:22 Bucle de comentarios de los clientes 48:29 Resumen y agradecimiento
Swyx: Bien, bienvenido a Latent Space. Estamos aquí en el estudio con nuestro coanfitrión invitado Vibh u. Bienvenido. Gracias. Emocionado por este, así como por Guillaume y Pavan de Mistral. Bienvenido. Emocionado de estar aquí.
Guillaume: gracias.
Swyx: Pavan, diriges la investigación de audio en Mistral y Guillaume, eres el científico jefe.
Anuncio de Voxtral TTS
(00:05) Está bien. (00:05) Bienvenido a Lean Space. (00:06) Estamos aquí en el estudio con los coanfitriones fiduciarios, Vibhu. (00:09) Bienvenido.
(00:11) Muy emocionado por este.
(00:12) Además de Guillaume y Pavan de Mistral. (00:15) Bienvenido. (00:16) Emocionado de estar aquí. (00:17) Gracias por invitarnos.
(00:18) Pavan, diriges la investigación de audio en Mistral y Guillaume, eres el científico jefe. (00:23) ¿Qué anunciaremos hoy cuando coordinaremos este lanzamiento con ustedes?
(00:26) Sí, estamos lanzando Voxtral TTS. Por tanto, es nuestro primer modelo de audio que genera voz. No es nuestro primer modelo de audio. Tuvimos un par de lanzamientos antes.
(00:35) Tuvimos uno en el verano que era Voxtral, nuestro primer modelo de audio, pero era como un modelo de transcripción, ASR. Unos meses más tarde, lanzamos una actualización además de esto, compatible con más idiomas. También muchas funciones de pila de tablas para nuestros clientes, sesgo de contexto, precisión, marca de tiempo y transcripción. También tenemos un modelo en tiempo real que puede transcribir no solo al final del nivel.
(00:56) No es necesario que completes todo el archivo de audio, pero eso también puede realizarse en tiempo real. Y aquí, esta es una extensión natural en el audio, básicamente generación de voz. Así que sí, admitimos nueve idiomas, y este es un modelo bastante pequeño, un modelo 3D, muy rápido y también de última generación. Funciona al mismo nivel que el modelo base, pero es mucho más eficiente en términos de costo, y también mucho más barato, solo una fracción del costo de nuestros competidores.
(01:22) Y también estamos publicando el trabajo que está ejecutando este modelo.
Swyx ¿Cuál es el factor de decisión?
Guillaume Es una buena pregunta.
Habrá más. Sí, Pavan, ¿algún tipo de notas de investigación para agregar?
Arquitectura y Códec
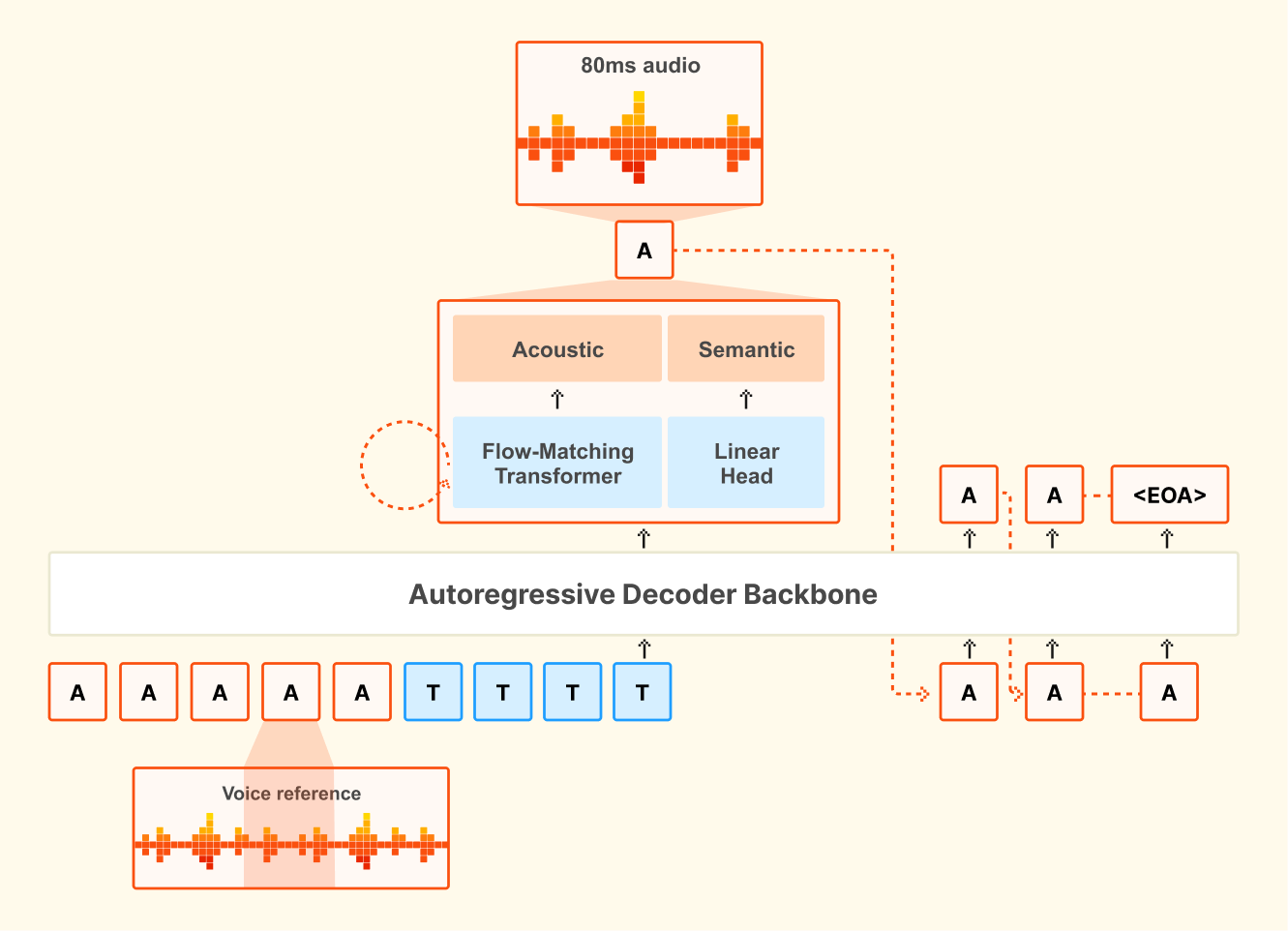
Pavan: Pero es una arquitectura novedosa que desarrollamos internamente.
Negociamos con varias arquitecturas internas y terminamos con una arquitectura de coincidencia de flujo autoagresiva. Y también tiene un nuevo códec de audio neuronal interno. Lo cual convierte este audio en tokens [00:02:00] latentes de todos los puntos, tokens semánticos y acústicos. Y sí, esa es la parte nueva de este modelo y estamos muy emocionados de que haya salido con tan buena calidad y Jim lo mencionó. Sí, es un modelo tres B. Se basa en el modelo TAL que en realidad lanzamos hace unos meses e insertamos un tronco y está destinado principalmente a cosas como TTS, pero también necesitan capacidades de texto. Sí.
Swyx: Entonces hay mucho que cubrir.
Siempre le ha gustado todo lo que tenga que ver con codificaciones novedosas y todas esas cosas porque cree que eso obviamente crea mucha eficiencia, pero también puede haber errores que a veces ocurren. Anteriormente eras Géminis y trabajaste en la capacitación posterior para modelos de lenguaje, y tal vez mucha gente tendrá menos experiencia con modelos de audio en general en comparación con el lenguaje puro.
¿Qué encontraste que tienes que revisar desde cero cuando te uniste a esta prueba y comenzaste a hacer esto? Al menos
Comprensión vs Generación
Pavan: cuando sabe trata de, cree que hay dos grupos, supongo que la comprensión de audio y la generación de audio [00:03:00]. La comprensión del audio, como los modelos de recorrido que Kim mencionó y que publicamos anteriormente.
El chat de recorrido que lanzamos, cree, en julio del año pasado, y la transcripción de seguimiento únicamente, la familia de modelos que lanzamos en enero, sería un grupo, y la generación es otro grupo. Creo. También puedes tratarlos como un conjunto unificado de modelos, pero actualmente los enfoques son un poco diferentes entre estos dos.
¿A su pregunta sobre cómo sabe envía el audio al modelo? En términos de comprensión del modelo, es muy similar a los modelos de Pixar que también lanzamos.
Pavan: Fue bonito, ese fue el primer proyecto en el que trabajé después de unirme a Misra. Fue bonito, muy bonito. Y Wtu era muy similar en espíritu.
Supongo que alimentamos audio a través de un codificador de audio similar a las imágenes a través de un codificador de visión, y produce incrustaciones continuas que sabe alimentan como tokens al modelo de transformador decodificado del transformador principal. Sí. En la salida del modelo es solo texto. Entonces, en el lado de la salida, no hay nada que hacer en este tipo de modo.
Supongo que [00:04:00] supongo que la parte interesante de lo que es la generación es que la salida ahora tiene que producir audio y. El enfoque que tenemos es este códec de audio neuronal, que convierte el audio en estos tokens latentes. Existe mucho desgaste y muchos modelos que sabe basan en este tipo de enfoque.
Y tomamos un poco. Unas decisiones de diseño diferentes en torno a esto. Pero al final del día, el producto de audio neuronal convierte el audio en un conjunto de latentes de 12,5 herdz. Y cada estado latente tiene un token semántico y un conjunto de tokens acústicos. Y la idea es tomar estos tokens discretos y luego alimentarlos en el lado de entrada.
Hay varias formas de usar esto en cada cuadro, pero solo sumamos la incrustación. Entonces es como tener vocabularios clave diferentes. Combínelos todos porque todos corresponden a un cuadro de audio en el lado de entrada. El lado de salida es la parte interesante del lado de salida, no es, no sabe si es el más popular, pero sí uno.
La técnica popular es tener un transformador de profundidad [00:05:00] porque tienes K tokens en cada paso de tiempo, como con un texto, solo tienes un token en cada paso de tiempo. Entonces simplemente predices el token a partir del vocabulario con, sí, con solo obtienes probabilidad
Swyx: Este es un texto muy sencillo. Muy
Pavan: sencillo.
Pavan: Pero si tienes K tokens, entonces el nombre sería predecirlos todos en paddle. Eso no funciona. Al menos eso no funciona tan bien porque el audio tiene más entropía. Y una de las técnicas que usa la gente es este transformador de profundidad en el que casi tienes un transformador pequeño, o también puede ser L-S-T-M-R, pero la gente usa transformadores y predices los tokens K de manera autoagresiva.
Entonces tienes dos cosas de recepción automática sucediendo.
Coincidencia de flujo para audio
Pavan: Entonces, lo que hicimos diferente es que, en lugar de tener esta predicción automática de pasos K, tenemos un modelo de coincidencia de flujo. En lugar de modelar esto como un conjunto de tokens discretos, entrenamos el códec para que fuera discreto y continuo para tener esta flexibilidad.
Así que también probamos el material discreto y funciona bien, pero el material continuo funciona mejor. Entonces, sí, tomamos esta coincidencia de flujo, por lo que es un cabezal de coincidencia de flujo [00:06:00], que toma el latente del transformador principal y, como en la fusión, elimina el ruido, pero en esta coincidencia de flujo, estimación de velocidad.
Entonces vas desde este ruido hasta allí. Audio latente, que corresponde al audio de 80 milisegundos y luego, que sabe envía a través de la orden de trabajo para recuperar el cuadro de audio de 80 milisegundos.
Swyx: Sí. ¿Es esta la primera aplicación de coincidencia de flujo en audio? Porque normalmente le encuentra con esto en la imagen.
Pavan: Sí. En realidad, en cierto sentido hay modelos que coinciden con el flujo de modelos en audio, pero cree que en esta combinación específica podría estar equivocado. Podría haber algo. No. No lo he visto. No he visto mucho trabajo en esto, así que cree que es novedoso y en gran medida es simplemente una comunidad mucho más grande, por lo que cree que son pioneros en muchos de estos trabajos de coincidencia de flujo de difusión, y es interesante adoptar algunas de las ideas allí en audio y,
Pavan: Sí, personalmente, esa es la parte de pensar que sabe está probando. Uno de los puntos más meta es diferente al texto, incluso en visión, cree que esto es cierto, pero en [00:07:00] literatura de pasos de audio no lo hay.
Modelo ganador, pero no existe, está bien, así es como sabe hacen las cosas. Todavía está por pasar, cree que la gente todavía está iterando y descubriendo cuál es la mejor receta general. Supongo que la idea. Estoy bastante seguro de que hay modelos que también son completamente de extremo a extremo, como el audio NATO. Audio de la OTAN, pero todavía no ha llegado a un punto de convergencia en el que esta sea la forma correcta de pensar aquello.
Eso también hace. Un espacio bastante emocionante para explorar.
Agentes de voz en tiempo real
Vibhu: ¿Cuáles son algunas de las formas de verlo?
Vibhu: Hay formas en las que puedes hacer difusión para la generación de audio, pero si quieres generar generación en tiempo real, eso es un gran problema con el enfoque que supongo que adoptaste. Sí. Y también cómo evalúas diferentes ejes de lo que te importa, sí,
Pavan: buen punto. Creo que podemos hacer simplemente una difusión coincidente de flujo para todo el audio. Ni siquiera tomamos ese camino porque una de las aplicaciones principales son los agentes de voz y queremos transmisión en tiempo real, y ese es el caso de uso. Ese no es el único caso de uso, pero es uno de los principales casos de uso al que queremos llegar.
[...]