
Los AI scientists están emergiendo como nueva interfaz para la computación científica. Estos agentes leen papers, escriben código, generan hipótesis, llaman APIs, inspeccionan archivos y iteran sobre los resultados. Pero la ciencia no es ingeniería de software: no hay suite de tests que se ponga verde cuando una hipótesis es correcta. El descubrimiento es iterativo, incierto y anclado al mundo físico.
NVIDIA acaba de empaquetar su stack acelerado de biología digital en un toolkit pensado para agentes: BioNeMo Agent Toolkit, una capa de Skills que documenta propósito, inputs requeridos, parámetros opcionales, artifacts esperados y modos de falla de cada modelo biomolecular. La idea: que un agente como Claude o Codex elija el modelo correcto, prepare un request válido y lea el resultado sin que un humano lo guíe paso a paso.
¿Qué incluye el BioNeMo Agent Toolkit?
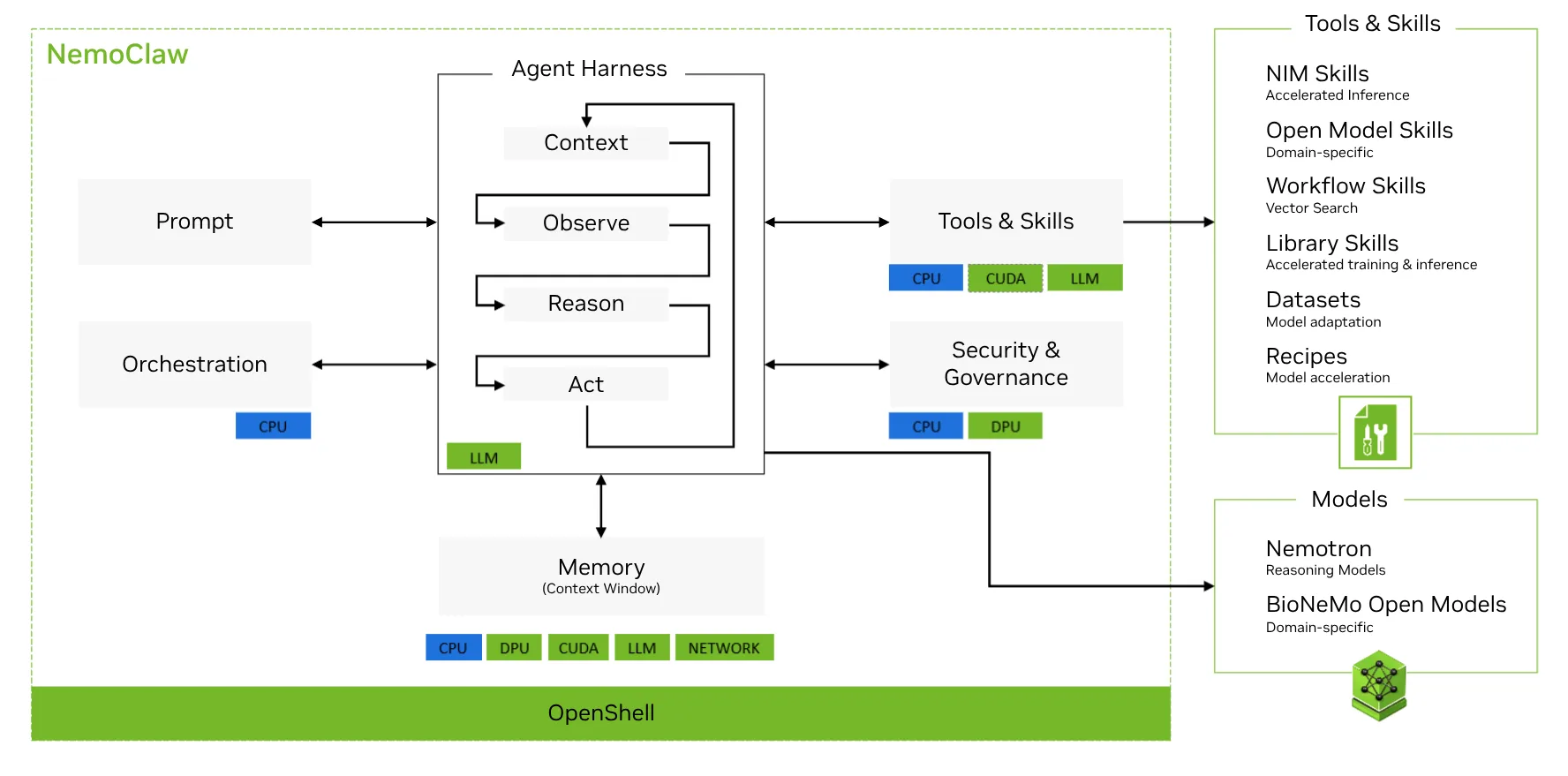
Las Skills son wrappers documentados sobre modelos publicados como NIM (NVIDIA Inference Microservices) o sobre modelos open que aún no fueron empaquetados como NIM (en ese caso vía servidores MCP, Model Context Protocol). El catálogo inicial cubre las tareas centrales de descubrimiento biomolecular:
- Plegamiento de proteínas: OpenFold3 y Boltz-2
- Docking molecular: DiffDock
- Generación de moléculas: GenMol
- Diseño de secuencias: ProteinMPNN, RFdiffusion
- Búsqueda y alineamiento: MMseqs2 (vía MSA Search)
- Genómica: Evo 2 y la suite Parabricks
- Aceleración: bibliotecas cuEquivariance (estructura) y Parabricks (genómica)
El repositorio público vive en github.com/NVIDIA-BioNeMo/bionemo-agent-toolkit y los endpoints hosted están en build.nvidia.com.
¿Cuánto mejora un agente con BioNeMo Skills?
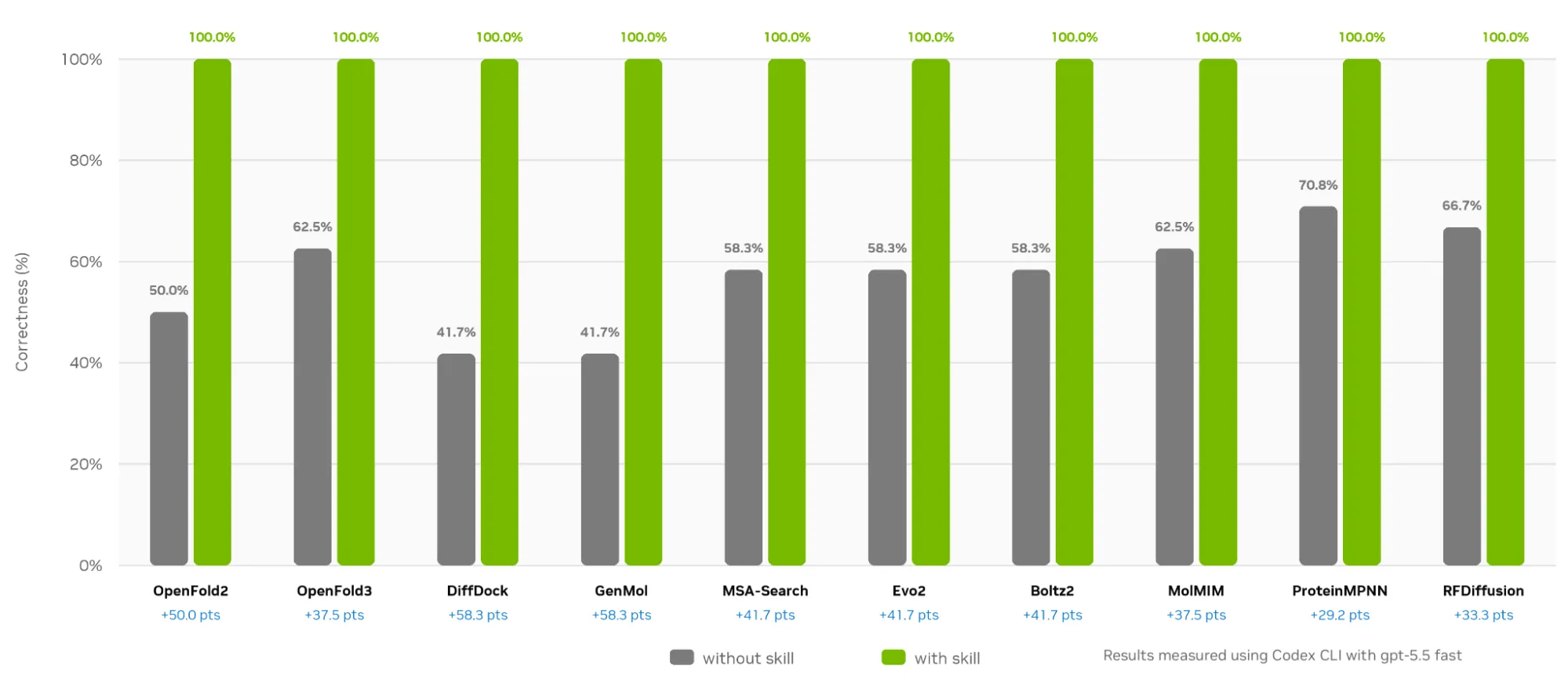
NVIDIA midió la diferencia con un benchmark interno usando Codex CLI y GPT-5.5 fast como agente. Sin skills, la tasa de completion sobre tareas biomoleculares quedó en 57,1%. Con skills, subió al 100%. La eficiencia de tokens (assertions pasadas por token consumido) se duplicó en promedio.
| Métrica | Sin Skills | Con Skills |
|---|---|---|
| Task completion rate | 57,1% | 100% |
| Eficiencia por token | 1× (baseline) | 2× promedio |
| Iteraciones por tarea | mayor | menor |
El salto se explica porque las Skills le evitan al agente "adivinar" cómo invocar cada modelo: cada wrapper trae el contrato de uso explícito.
¿Hosted o local? Cuándo conviene cada modo
NVIDIA ofrece dos rutas de deployment para las NIMs:
- Hosted en build.nvidia.com: ideal para acceso rápido, evaluación o llamadas ocasionales. Sin gestión de GPU, sin contenedores que mantener. Recomendado para workflows que dependen de servicios infra-intensivos como MSA Search.
- Local en GPU propia: pensado para loops iterativos que llaman al mismo modelo muchas veces. Reduce la latencia warm por llamada y permite mantener datos sensibles in-house.
La regla práctica que sugieren: empezar hosted para tener acceso amplio y escalable, luego mover modelos puntuales a local cuando latencia, throughput, seguridad o iteración repetida justifiquen el control operativo extra. Los endpoints públicos en build.nvidia.com son para development y testing, no para inferencia en producción.
Una skill en acción: OpenFold3
El patrón de prompt es el mismo para cualquier Skill. Para plegar la secuencia MKTVRQERLKSIVR contra un endpoint OpenFold3 hosted:
Use the OpenFold3 BioNeMo Skill to fold MKTVRQERLKSIVR with the NVIDIA API
endpoint at https://build.nvidia.com/openfold3Para deployment local:
Use the OpenFold3 BioNeMo Skill to fold MKTVRQERLKSIVR with the local NIM
endpoint at http://localhost:8000El agente recibe el contrato del modelo (qué hace, qué input necesita, qué artifact devuelve, qué errores puede tirar) y se encarga del resto.
¿Y qué pasa con investigadores en Chile y LatAm?
Para grupos de investigación universitarios chilenos (UC, USACH, UCN, Universidad de Concepción) y argentinos que vienen trabajando en biología computacional, el toolkit baja considerablemente la barrera de entrada. Acceder a OpenFold3 o DiffDock sin tener que pelearse con CUDA, contenedores Docker y dependencias Python rotas es una mejora real. Para quien no tenga GPU H100 a mano, los endpoints hosted en build.nvidia.com ofrecen un camino sin costo inicial (con créditos free) suficiente para prototipar antes de escalar.
NVIDIA también menciona que el patrón se extiende más allá de un solo tool: el broader stack incluye NVIDIA Nemotron (modelos abiertos) y el NeMo Agent Toolkit para orquestación y memoria, manteniendo el mismo enfoque de Skills documentadas para cada capacidad.



