
NVIDIA publicó un benchmark que muestra que su tecnología Confidential Computing en GPU Blackwell entrega alrededor del 98% del rendimiento de una GPU sin cifrado. La cifra aparece en una prueba sobre la HGX B300 corriendo el modelo Qwen 3.5-397B-A17B-FP8, y apunta directo al argumento que frena a muchos equipos de infraestructura: encriptar durante la inferencia castiga el throughput.
¿Qué es Confidential Computing en GPU?
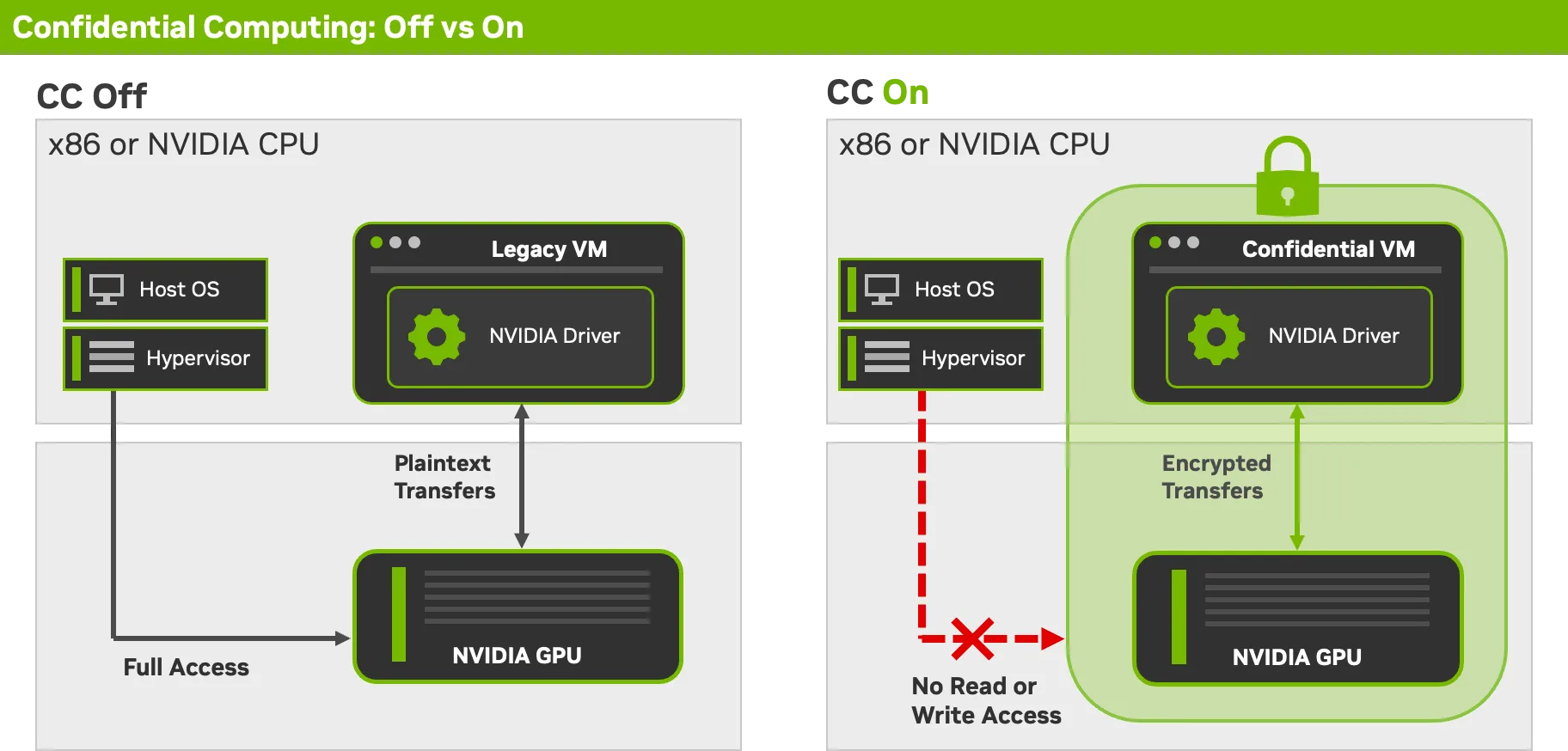
El sistema de Confidential Computing (CC) de NVIDIA integra seguridad a nivel de hardware en las GPU Blackwell (incluyendo RTX PRO 6000, HGX B200 y HGX B300). Entre las piezas técnicas relevantes:
- Claves privadas fundidas en silicio: cada GPU mantiene una clave de firma privada grabada en fábrica que nunca se expone al software, al firmware ni al host.
- NVLink cifrado: la comunicación GPU-GPU va encriptada, con soporte de hasta 8 GPUs por nodo confidencial.
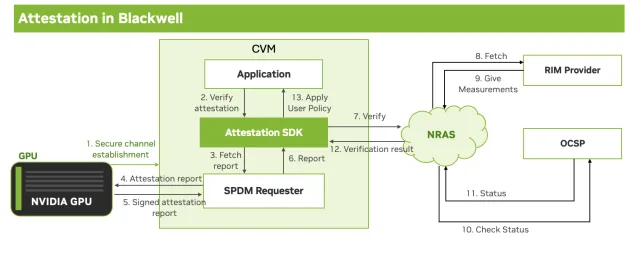
- Remote attestation: el servicio NRAS (NVIDIA Remote Attestation Service) verifica que la carga de trabajo corre sobre una GPU no modificada antes de entregar secretos como claves de descifrado de modelos.
Este enfoque combina la GPU con TEEs de CPU (AMD SEV-SNP o Intel TDX) para armar un pipeline confidencial completo desde el silicio hasta el sistema operativo del huésped. La verificación se ejecuta una sola vez al arranque de la máquina virtual confidencial (CVM); una vez validada, no se agrega latencia por request.
¿Cuánto cuesta activar Confidential Computing?
El corazón del post es el benchmark. Sobre una HGX B300 con el modelo Qwen 3.5-397B-A17B-FP8, NVIDIA midió throughput y latencia por token con distintas combinaciones de concurrencia, tamaños de batch y longitudes de secuencia. El resultado: activar CC introduce menos del 8% de overhead en la mayoría de los escenarios, manteniendo un rendimiento cercano al 98% del baseline sin cifrado.
Ese número es agresivo. Habilitar cómputo confidencial suele implicar penalizaciones de entre 10% y 30% dependiendo de la carga. NVIDIA atribuye el resultado a varias optimizaciones:
- Autotuning seguro en FlashInfer: reemplaza los event timers por el timer global del GPU, lo que permite calibrar kernels con precisión aún dentro del entorno confidencial.
- Worker asincrónico D2H: descarga la copia de datos device-to-host a un hilo aparte para no bloquear la inferencia.
- CUDA graphs por tramos en SGLang: reduce la frecuencia de secure work submission, uno de los cuellos de botella más caros del modo CC.
¿Dónde son cuellos de botella la seguridad activa?
NVIDIA identifica dos fuentes de overhead cuando se activa CC en inferencia:
1. Latencia de secure work submission: encriptar el lanzamiento de kernels agrega costo. Cuanto más chico el batch, más se nota. La contramedida es aumentar el trabajo por launch. 2. Ancho de banda CPU-GPU reducido: las transferencias host-to-device pasan por un canal cifrado más lento. Si la carga es intensiva en I/O de entrada, se puede saturar antes que el compute.
En cargas de LLM grande con batch high y contexto largo, la primera fuente pesa poco y la segunda queda amortiguada. Por eso el número del 98% se sostiene en el escenario Qwen 397B FP8.
¿Por qué importa esto para el mercado LatAm?
Sectores regulados —banca chilena, salud, gobierno— frecuentemente citan la performance perdida como razón para no usar GPU compartida para IA generativa. Un overhead inferior al 8% en Blackwell reduce ese argumento a un tercio de su tamaño previo. Para integradores locales que venden Bedrock o Azure OpenAI on Confidential VMs, la métrica es un dato comercial concreto que reemplaza la conversación difusa de "es más lento pero más seguro".
El post técnico completo, con las tablas de throughput y las configuraciones exactas, sigue disponible en el blog de NVIDIA Developer.



