
IA
NVIDIA Rubin: 10x más rendimiento agentico por watt
La nueva GPU de la plataforma Vera Rubin apunta a las cargas de IA agentica con 336 mil millones de transistores, 288 GB de HBM4 y 50 petaflops en formato NVFP4.
NVIDIA Developer
12 notas publicadas
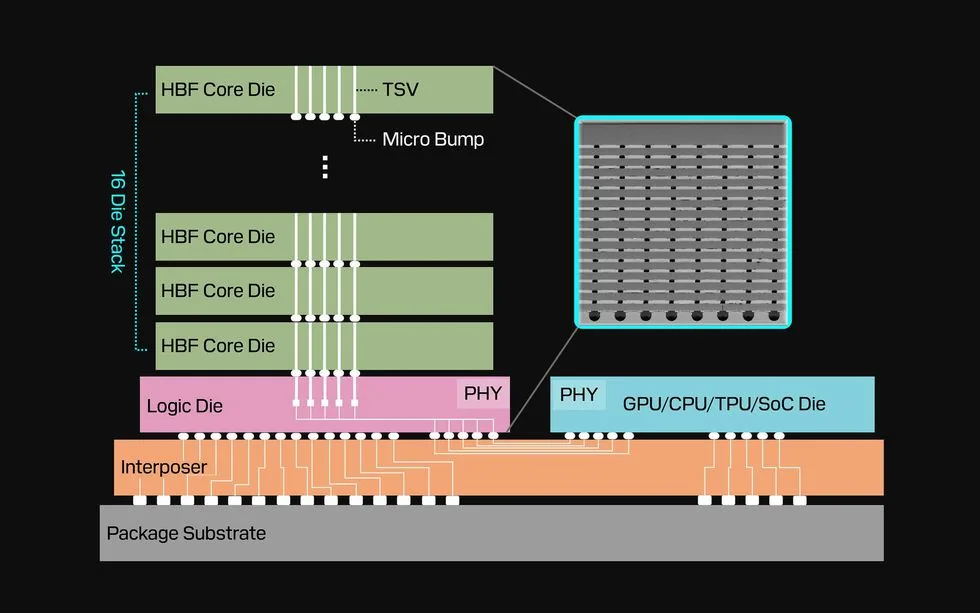
Sandisk y SK Hynix apilan chips de flash NAND para crear una capa de memoria barata y de alta capacidad, pensada para servir los pesos de modelos gigantes en tareas de inferencia.

El chip, atribuido a Jeff Dean, grabaría el plano de Gemini en el hardware para ser 6 a 10 veces más eficiente que los TPU actuales. Google lo desplegaría desde 2028 para abaratar la inferencia.

El benchmark en HGX B300 con Qwen 3.5-397B-A17B-FP8 muestra menos del 8% de overhead con Confidential Computing activado.
The Information reveló que la compañía optimizó la inferencia para visitantes sin cuenta y bajó a unos pocos cientos las GPU NVIDIA necesarias.

Dos meses después del lanzamiento, el stack abierto pasó de 2.200 a 11.200 tok/s/GPU a la misma interactividad gracias a KV Compression V2, W4A4 MegaMoE y CUDA graphs rompibles en el prefill.

El chip de unos 840 mm² (cerca del límite reticle EUV) lleva seis módulos HBM, llegó al tape-out en nueve meses y se desplegará a escala gigawatt con Microsoft desde fines de 2026.

Seis meses después de licenciar su IP de LPU a NVIDIA y perder a su fundador, la chipmaker apuesta por su negocio neocloud con 13 data centers y nuevos ejecutivos al timón.
Artificial Analysis estrenó el primer benchmark multi-vendor que mide rendimiento concurrente de agentes de IA en cargas reales de coding, con resultados normalizados por acelerador y por megawatt.

DynoSim corre el stack de servicio de LLM como simulación discreta en Rust y mapea la frontera de Pareto del workload antes de pagar GPUs reales.
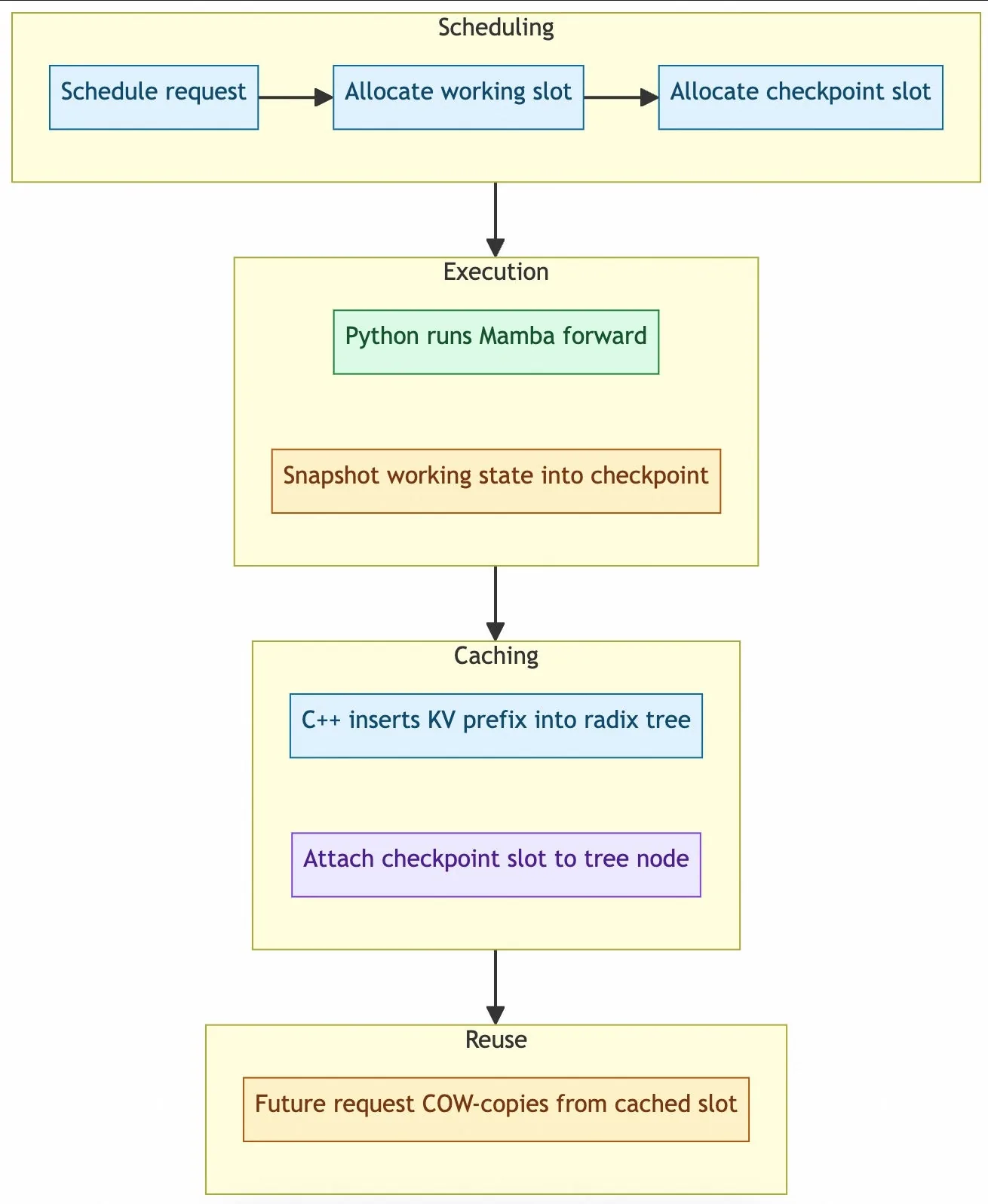
El motor open source de LightSeek, escrito desde cero en SPMD con compilacion estatica, ataca workloads agenticos con prefix cache hibrido y disaggregacion prefill-decode para Mamba.

El sistema con CRIU mas cuda-checkpoint baja el cold-start de un gpt-oss-120b al limite fisico de memoria, evitando que GPUs facturadas queden ociosas durante el scale-up.
Otros temas que aparecen junto a #inferencia en nuestra cobertura editorial.