Los agentes de IA cambiaron de raíz la complejidad de las cargas de inferencia. Hasta ahora, la industria no tenía un estándar claro para medir cómo rinden los sistemas de inferencia bajo estas condiciones. Artificial Analysis AgentPerf (AA-AgentPerf) ofrece los primeros benchmarks abiertos multi-vendor con trayectorias representativas de tareas reales de coding con agentes.
Este artículo explica cómo AA-AgentPerf establece un nuevo estándar para medir rendimiento en cargas agénticas, y cómo el co-diseño extremo de NVIDIA permite entregar hasta 20 veces mejor desempeño en coding agéntico frente a generaciones anteriores.
¿Qué es AA-AgentPerf?
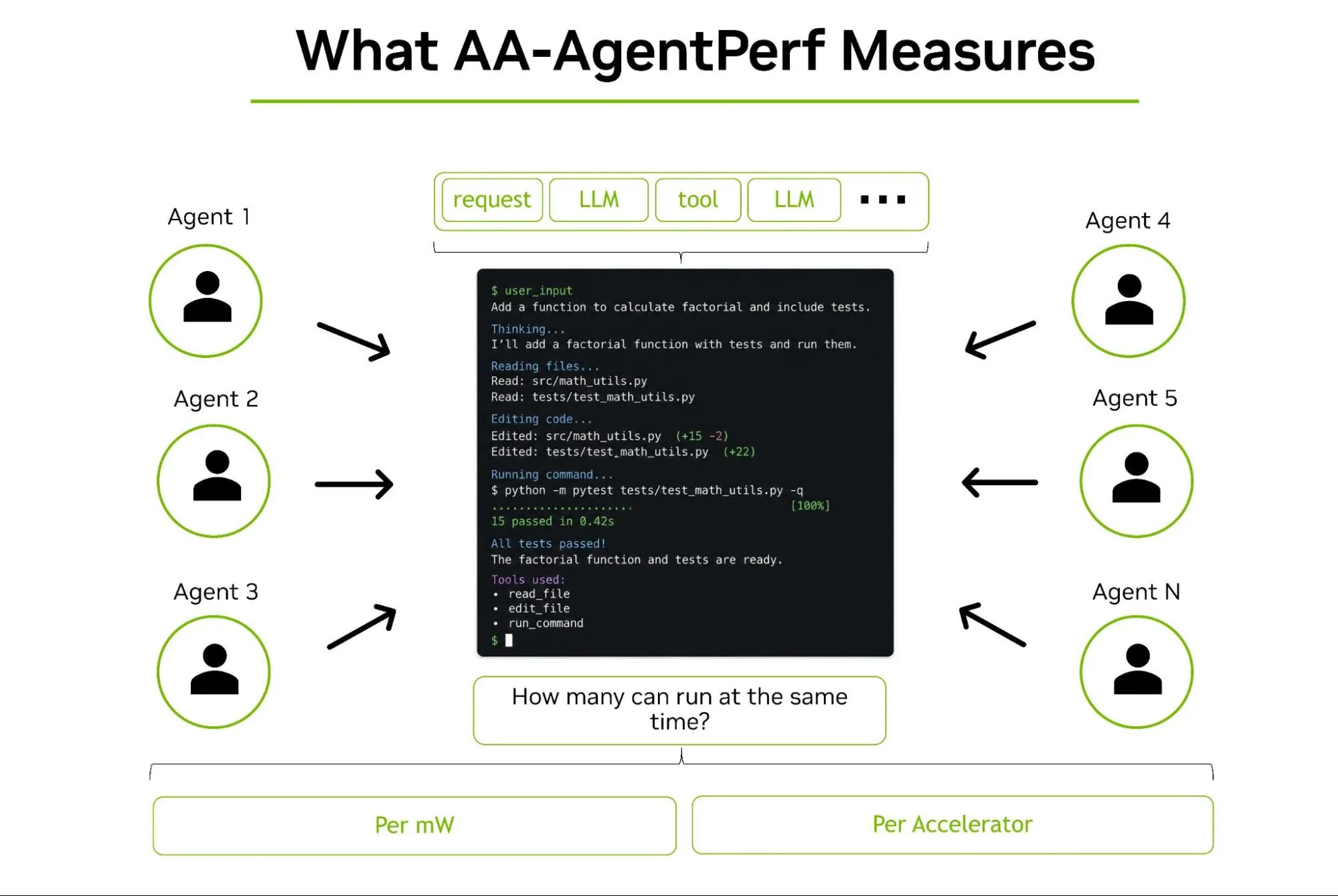
AA-AgentPerf es un benchmark de hardware creado por Artificial Analysis que mide la cantidad de agentes de IA concurrentes que un sistema de inferencia puede sostener mientras cumple objetivos de nivel de servicio (SLO) predefinidos por modelo. Un SLO se define como un umbral específico de velocidad de salida de tokens y time-to-first-token (TTFT). Los resultados se normalizan por acelerador y por megawatt para permitir comparaciones entre configuraciones de hardware distintas.
¿Cómo se mide rendimiento agéntico representativo?
Las cargas agénticas son únicas porque las decisiones impulsadas por LLM suelen producir secuencias no determinísticas de requests y tool calls. La parte más difícil de medir el rendimiento de agentes es capturar con precisión esa no determinismo en una trayectoria representativa: la secuencia completa de acciones, decisiones y observaciones que hace un agente al recorrer una tarea de inicio a fin.
AA-AgentPerf captura esto midiendo el rendimiento de GPUs sobre trayectorias pregrabadas de coding agéntico con razonamiento y uso de herramientas intercalados, simulando además la latencia inter-turno con un baseline representativo de tool calls en CPU. Las trayectorias se construyen alrededor de resolver issues en repositorios de código públicos, en más de 12 lenguajes de programación y con respuestas de modelos frontera. Además de definir las trayectorias con rigor, el equipo de Artificial Analysis:
- Usó longitudes representativas de secuencias cacheadas, de entrada y de salida, con rangos entre 5.000 y 131.000 tokens y una media de aproximadamente 27.000.
- Mapeó tool calls a tareas representativas del lado de CPU en flujos de coding agéntico y los simuló con una distribución de latencia mediana de un segundo. El mismo baseline de CPU se aplicó en todos los sistemas evaluados.
- Mantiene el test set privado para evitar optimizaciones específicas para el benchmark.
Metodología de medición
El harness de AA-AgentPerf mide cuántos agentes concurrentes puede sostener un sistema de inferencia cumpliendo los requisitos del SLO. En el lanzamiento, el benchmark se enfoca en probar DeepSeek-V4-Pro en múltiples tramos de SLO derivados de datos del benchmarking de APIs serverless de Artificial Analysis. Esto asegura que los resultados reflejen niveles de calidad de servicio observados en proveedores productivos hoy.
Durante una corrida, AA-AgentPerf envía miles de requests concurrentes a las GPUs extraídos de su dataset de trayectorias. Para garantizar resultados independientes en cada corrida, se añaden prefijos dinámicos al inicio de cada fase. Se imponen umbrales estrictos de SLO durante toda la trayectoria, y el mayor nivel de concurrencia que cumple esos requisitos se registra como resultado oficial.
¿Cómo se interpretan los resultados?
La métrica central de AA-AgentPerf es runtime power por megawatt, una normalización práctica para representar rendimiento a escala de data center. En el día del lanzamiento, NVIDIA GB300 NVL72 entrega hasta 20 veces más agentes concurrentes por megawatt que la generación anterior, NVIDIA H200.
Este rendimiento muestra cómo GB300 NVL72 logra escalar cargas masivas de coding agéntico, desde el ruteo eficiente de sesiones de larga duración hasta mantener mixtures of experts (MoEs) y GPUs plenamente utilizadas en muchas sesiones de agente concurrentes.
- SGLang, TensorRT LLM, o vLLM: los runtimes de agentes aplican optimizaciones como WideEP y DeepEP para distribuir la ejecución de expertos del MoE en todo el dominio NVL72, maximizando los tamaños efectivos de batch y escalando a miles de agentes.
- DeepGEMM y Mega MoE: los kernels MXFP4/MXFP8 y el MoE fusionado solapan la comunicación NVLink con el cómputo de tensor cores para mejorar el throughput de tokens en razonamiento y generación de código.
- Dominio scale-up NVIDIA NVLink: GB300 NVL72 conecta 72 GPUs en un solo fabric NVLink de alto ancho de banda, así cada GPU puede compartir rápidamente parámetros, KV cache y resultados intermedios, algo crítico para la ejecución coordinada de sistemas de coding agéntico.
¿Qué viene con la plataforma Vera Rubin?
AA-AgentPerf establece el estándar para evaluar inferencia agéntica, y los resultados muestran cómo hardware y software fuertemente integrados pueden desbloquear ganancias por saltos en concurrencia y eficiencia. NVIDIA GB300 NVL72 demuestra hasta 20 veces más rendimiento en coding agéntico.
Se espera que la plataforma NVIDIA Vera Rubin extienda estas ganancias aprovechando 50 PFLOPs de cómputo NVFP4 y usando el CPU Vera para acelerar tool calls del LLM y mejorar el rendimiento, la economía y la eficiencia de extremo a extremo en cargas agénticas.