Railway no empezo como una empresa de infraestructura de IA. Fue fundada en 2020, años antes de que los agentes se convirtieran en la forma por defecto de pensar el despliegue de software. Jake Cooper, ex Bloomberg y Uber, fundo Railway con una obsesion simple: la energia de activacion para mandar algo a produccion deberia ser casi cero. Pusheas codigo, obtienes una URL, iteras. Sin Dockerfiles, sin manifiestos de Kubernetes, sin scripts de Ansible apilados sobre scripts de Ansible.
Durante años, fue un trabajo lento. Railway paso sus primeros 18 meses captando a mano a sus primeros 100 usuarios, con Cooper saludando personalmente a cada signup de Discord en un segundo monitor.
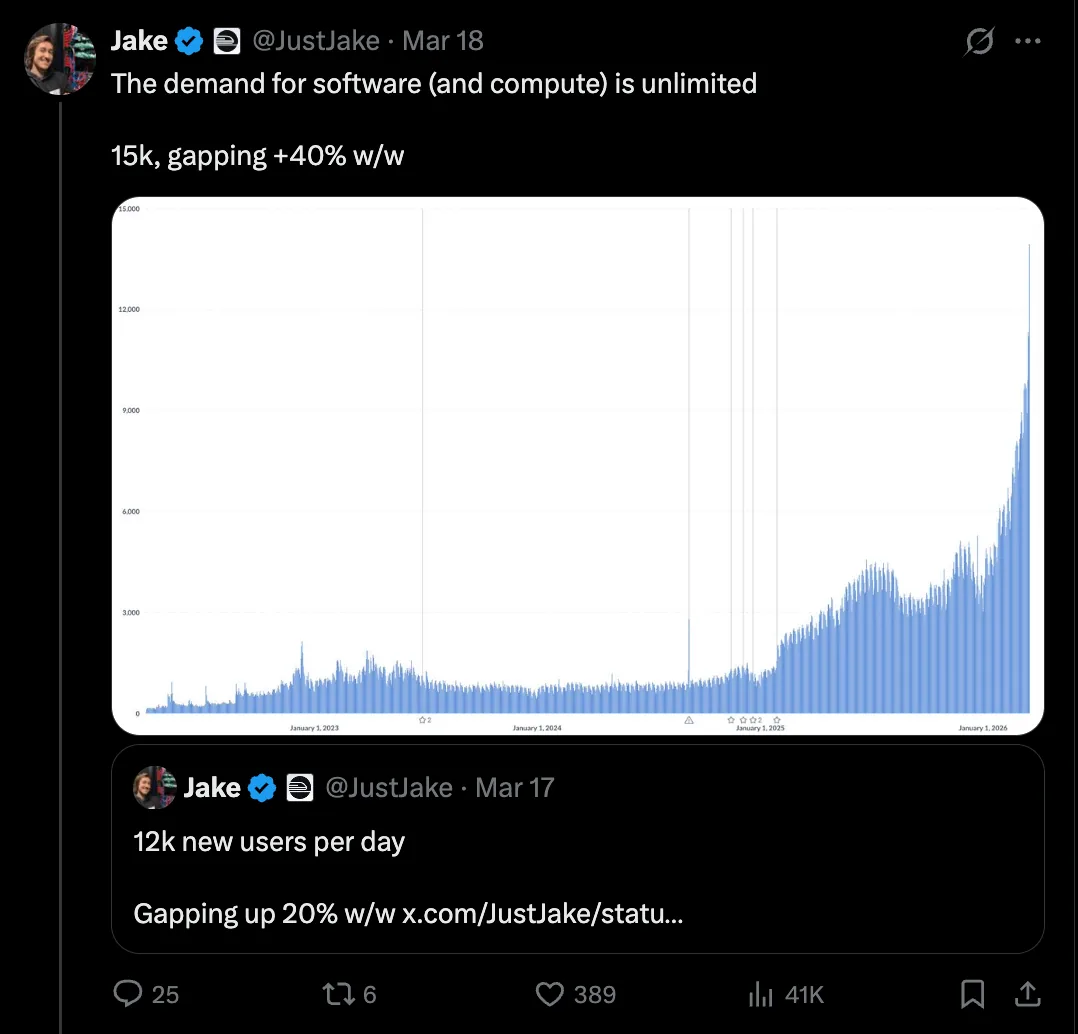
¿Cuanto creció Railway hasta hoy?

Hoy, Railway ha levantado USD 124 millones y crece muy rapido. Un equipo de 35 personas atiende a 3 millones de usuarios, sumando aproximadamente 100.000 signups por semana. Sus data centers en hardware propio tienen un periodo de payback de 3 meses frente a rentar en la nube, con margenes de 70% que financian el cloud bursting agresivo cuando hace falta. Los servidores que poseen incluso se apreciaron en valor a medida que los precios de RAM subieron, lo que basicamente significa que el valor de su hardware ya excede el capital que han levantado.
Desde reconstruir el overlay de red de Railway en un fin de semana hasta mover la gran mayoria de las cargas a sus propios data centers bare metal, Cooper esta construyendo un nuevo cloud para un mundo agent-native. En el ultimo episodio del podcast Latent Space, el fundador y "conductor" de Railway se sento con swyx y Alessio para desarmar por que la proxima era de la infraestructura de software no es simplemente "Heroku pero mas nuevo", que necesitan los agentes que los humanos no necesitaban, y por que el viejo loop de despliegue de Git, PRs, CI/CD y recursos cloud estaticos puede estar yendo hacia una reescritura.
Numeros clave de Railway

| Metrica | Valor |
|---|---|
| Capital levantado | USD 124 millones |
| Usuarios | 3 millones |
| Signups semanales | ~100.000 |
| Equipo | 35 personas |
| Payback data centers propios | 3 meses |
| Margenes | 70% |
| Gasto en agentes de coding | USD 200.000+ |
¿Por que los agentes necesitan otra infraestructura?
El episodio profundiza en el stack de Railway: data centers propios, payback de 3 meses sobre cloud, cloud bursting, deuda de data center, Railpack, Nixpacks, Temporal, feature flags, Central Station, filesystems content-addressable, forks de produccion seguros para agentes, y por que la CLI puede volverse mas importante que el canvas en un mundo de agentes.
Cooper tambien comparte el camino del fundador detras de Railway: como la compañia sobrevivio perdiendo USD 500.000 al mes, por que ahora atiende a millones de usuarios con solo 35 personas, y por que cree que el pull request esta muriendo.
Los puntos clave del podcast:
- Como Railway paso de un grind lento de seis años a sumar 100.000 usuarios por semana
- Como Railway piensa los agentes como la proxima especie dominante de software
- Por que los agentes necesitan control de version, observabilidad, computo, storage y orquestacion a escala 1.000x
- La economia de los data centers propios y el payback de 3 meses
- Como Railway usa cloud bursting mientras escala su infraestructura propia
- Por que la deuda de data center puede ser mejor herramienta que la venture debt para startups de infraestructura
- Central Station, el sistema interno de Railway para clusterizar feedback de clientes e incidentes
- Por que las feature flags, los rollouts progresivos y el shadow traffic son esenciales para agentes
La muerte del pull request
Una de las tesis mas fuertes de Cooper es que el pull request esta muriendo como abstraccion primaria del desarrollo de software. En un mundo donde los agentes generan codigo a velocidad de maquina y donde Railway reporta gastos de mas de USD 200.000 al mes en agentes de coding internos, el ciclo Git PR CI/CD humano se vuelve cuello de botella.
La alternativa que Railway propone son forks de produccion seguros, ambientes clonables a demanda con datos reales, feature flags para rollouts progresivos, y content-addressable filesystems que permiten que mil agentes corran experimentos en paralelo sin reproducir toda la infraestructura.
Datos centrales en el espacio
En uno de los segmentos mas inesperados del episodio (timestamp 00:23:31), Cooper menciona que esta evaluando data centers en orbita. La logica: el costo marginal de enfriamiento en orbita baja es cero (radiacion al vacio espacial), la energia solar es continua, y los costos de lanzamiento de SpaceX bajaron al punto en que el TCO de un rack orbital empieza a competir con un rack terrestre cuando se considera el costo total de electricidad y refrigeracion de un data center hyperscaler.
Es una idea especulativa pero indica hasta donde Cooper esta dispuesto a "nadar al fondo de la piscina" para conseguir la experiencia que quiere.



