La inteligencia artificial robótica de hoy tiene una debilidad fundamental: los modelos aprenden a mapear imágenes de cámara directamente a movimientos, pero no entienden cómo cambia el mundo como resultado de sus acciones.
Un nuevo paper de revisión, firmado por investigadores de Fudan University, el Shanghai Innovation Institute y la Universidad Nacional de Singapur, es el primero en catalogar de forma sistemática una clase de modelos diseñada para cerrar esa brecha: los World Action Models (WAM).
¿Qué hacen los World Action Models?
Los modelos vision-language-action convencionales aprenden mapeos directos desde observación a acción coincidente. Los WAM van más allá: también modelan cómo cambiará probablemente el entorno y conectan esa predicción con la generación de acción.
El beneficio práctico, según los autores, es concreto. Un modelo que simula las consecuencias de un movimiento antes de ejecutarlo generaliza mejor a objetos y entornos desconocidos. Más importante aún: puede aprender de videos en los que no hay etiquetas de acciones robóticas, como videos cotidianos en primera persona. Ese tipo de datos era casi inservible para la robótica AI tradicional.
Los generadores de video puros pueden producir fotogramas futuros plausibles, pero no están ligados a señales de control. Un equipo de la Universidad de Pekín hizo recientemente exactamente esa distinción en su definición unificada de modelos del mundo. Los World Action Models cumplen las dos condiciones a la vez.
¿Cuáles son las dos arquitecturas principales?
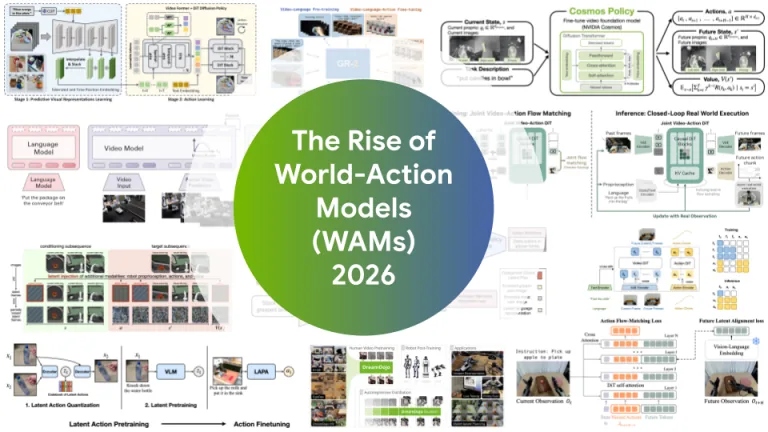
Los investigadores clasifican unos cien papers en dos líneas arquitecturales.
La primera, los WAM en cascada, trabaja en dos pasos. Un modelo del mundo genera primero una imagen o video de cómo debería verse la escena a continuación. Luego un segundo módulo extrae los comandos de control adecuados de esa salida. Trabajos como UniPi generan videos completos y derivan el movimiento mediante un modelo inverso aprendido.
Otros enfoques como AVDC o 3DFlowAction usan campos de movimiento desde los cuales se calcula geométricamente la trayectoria del robot. Otros (VPP o LAPA, por ejemplo) saltan las imágenes visibles por completo y predicen el futuro en representaciones comprimidas y abstractas. Eso ahorra el cómputo que de otro modo se necesitaría para renderizar cada píxel.
La segunda línea, los WAM conjuntos, combina ambas tareas en un único modelo. Trabajos como GR-1, GR-2 o WorldVLA tratan imágenes y acciones como una secuencia unificada de tokens. Variantes basadas en difusión como PAD, UWM o DreamZero generan el fotograma futuro y el movimiento en paralelo. La Cosmos Policy de Nvidia puede usar la misma arquitectura como controlador, simulador o modelo de evaluación.
¿De dónde salen los datos de entrenamiento?
Un capítulo completo del survey investiga el origen de los datos. Cuatro fuentes dominan el campo:
- Teleoperación: datos precisos pero caros, limitados a un puñado de entornos. Datasets como Open X-Embodiment o DROID intentan resolverlo mancomunando datos entre laboratorios.
- Demos portátiles: herramientas como la Universal Manipulation Interface permiten que humanos realicen tareas con gripper manual en entornos cotidianos. El dataset RDT2 acumula así unas 10.000 horas.
- Simulación: RoboCasa o RoboTwin 2.0 entregan trayectorias ilimitadas con datos de profundidad perfectos, pero sufren la conocida brecha sim-to-real. Nvidia apuesta fuerte acá con GR00T N1, entrenando humanoides mayoritariamente en entornos sintéticos.
- Videos egocéntricos cotidianos (Ego4D): variedad ilimitada pero sin etiquetas de acción. Acá los WAM muestran su ventaja: pueden usar esos videos para predecir fotogramas futuros aun sin datos de movimiento.
¿Qué falta todavía en evaluación?
Los autores son especialmente críticos con la evaluación actual. La calidad visual se mide con métricas estándar (PSNR, FVD), pero esas dicen poco sobre si un video es físicamente plausible.
Benchmarks especializados intentan medir distintos aspectos: VideoPhy evalúa escenarios de interacción física, Physics-IQ prueba predicciones de eventos físicos reales y WorldModelBench chequea reglas explícitas como gravedad, conservación de masa, mecánica de cuerpos rígidos e impenetrabilidad.
El hallazgo más filoso viene del benchmark Wow, Where, Val!: chequea si un video generado realmente puede traducirse en un movimiento ejecutable. Muchos modelos visualmente convincentes caen a tasas de éxito cercanas a cero en ese test.
¿Y la velocidad de inferencia?
El cómputo sigue siendo un cuello de botella. DreamZero maneja unas 7 predicciones por segundo; los controladores robóticos tradicionales corren a unos 50 Hz. La brecha de un orden de magnitud es real y limita por ahora el uso en producción.
Meta mostró hace unos meses con V-JEPA 2 que los modelos del mundo autosupervisados sobre video pueden saltarse la generación de píxeles visibles por completo y predecir solo representaciones abstractas del futuro. Los autores del survey ven esto como uno de los caminos más prometedores para bajar el costo de cómputo sin perder el anclaje físico.
La lista completa de los papers discutidos está disponible en GitHub.