RLWRLD presentó la semana pasada RLDX-1, un nuevo foundation model dexterity-first. La compañía surcoreana construyó el modelo para resolver tareas complejas en industria real usando manos robóticas con alta cantidad de grados de libertad (DoF).
Los foundation models existentes suelen carecer de capacidades esenciales, como memorización de contexto o detección de fuerza, requeridas para despliegue real en producción, según RLWRLD. Para resolverlo, RLDX-1 abarca el ciclo completo de robótica: integra un pipeline escalable de recolección de datos, una arquitectura versátil, métodos de entrenamiento robustos y estrategias de despliegue optimizadas.
Como resultado, RLDX-1 alcanza rendimiento state-of-the-art, según RLWRLD. El modelo demuestra precisión y generalización tanto en entornos simulados como en aplicaciones industriales físicas.
RLWRLD diseñó RLDX-1 desde cero para manos robóticas diestras. Cada componente existe porque un modo de falla específico en una tarea real lo exigió. El resultado es un modelo único que puede ver, sentir, recordar y adaptarse, desplegable en configuraciones single-arm, dual-arm y humanoides con manos de alta DoF.
¿Cuáles son los cinco regímenes de destreza que identifica RLWRLD?
El último kilómetro de la automatización industrial es la destreza. Los robots actuales todavía no pueden servir café de forma confiable a medida que la cafetera se vacía, tomar un objeto en movimiento desde una cinta transportadora o girar una tuerca hexagonal con la yema de los dedos, observó la firma surcoreana con base en Seúl.
RLWRLD destiló estas necesidades recurrentes de clientes en DexBench, un benchmark que las organiza en cinco regímenes de destreza, donde cada régimen es un modo de falla específico de los robots actuales:
- Diversidad de agarres: las manos de cinco dedos son requisito previo para todos los regímenes siguientes. RLWRLD ha operado más de 10 manos in-house. Usa dos pipelines de datos para diversificar agarres: datos sintéticos de robot que aumentan un set teleoperado pequeño, y Human Data que cubre destreza in-hand de alta DoF inaccesible vía teleoperación.
- Precisión espacial: la política debe capturar suficiente estructura de la escena para colocar el contacto correctamente antes de tocarlo. RLDX-1 refuerza esta capacidad con un Vision Language Model (VLM) especializado en robots, fine-tuned sobre VQA (visual question answering) específico de robots.
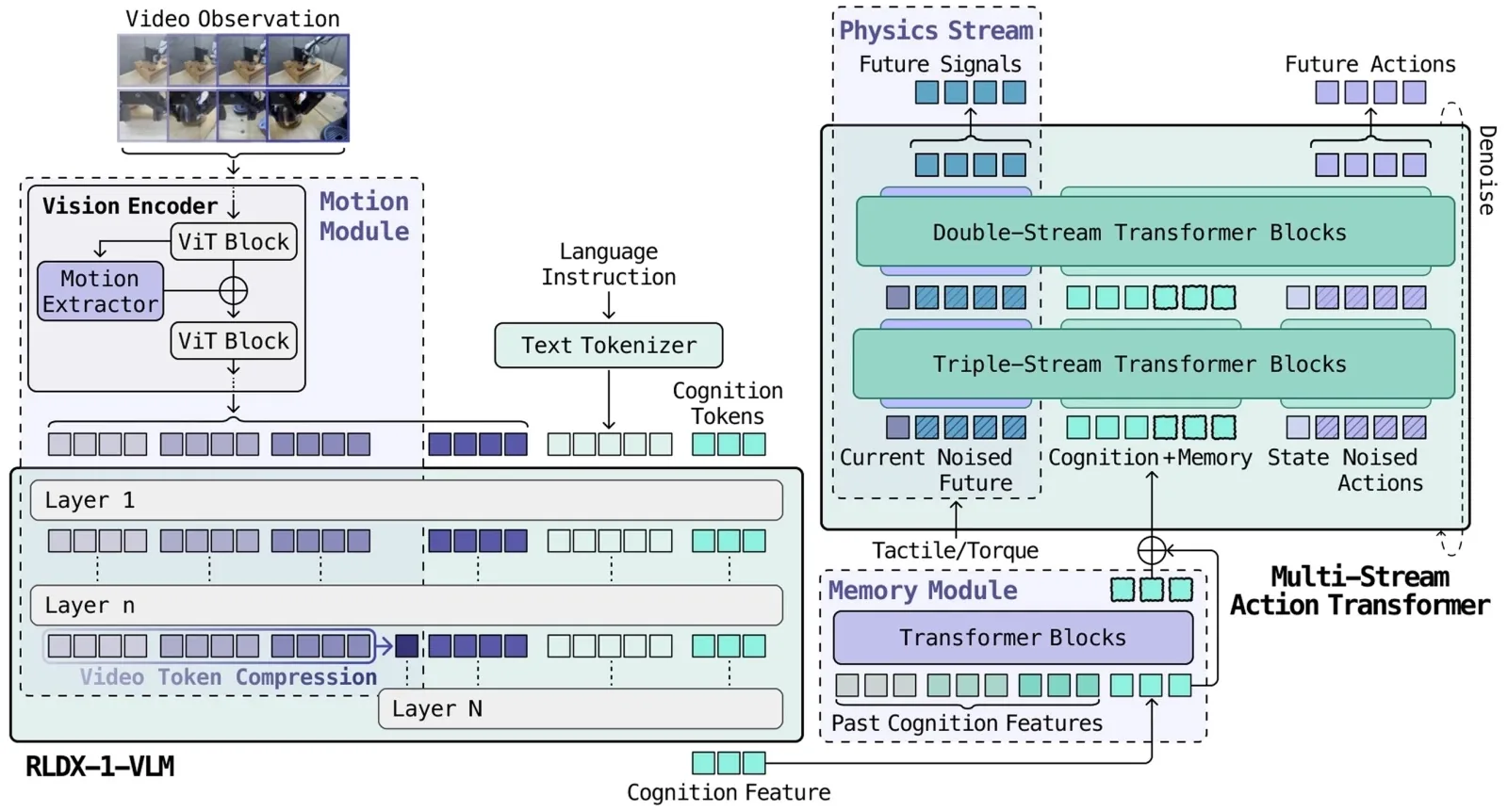
- Precisión temporal: una política basada en un único frame siempre va un paso atrás. Cuando la mano llega, el objeto en la cinta ya se movió. El Motion Module extrae features de correspondencias espacio-temporales y amortiza contexto multi-frame en una representación compacta.
- Precisión de contacto: una cafetera vaciándose es visualmente invariante; la señal está en el torque del muñeca. El Physics Module da a tacto y torque sus propios streams y predice estados futuros de contacto junto a las acciones.
- Conciencia de contexto: razonamiento de nivel-tarea que envuelve a las tres precisiones anteriores. Sin ella, hasta un movimiento perfectamente ejecutado se queda varado en el único paso para el que fue planeado, según RLWRLD.
¿Cómo funciona el Multi-Stream Action Transformer (MSAT)?

Cada régimen entra al modelo como una modalidad fundamentalmente distinta: el torque es un stream continuo de alta tasa, el video son frames dispersos de alta dimensión, y la memoria es stateful. En un transformer convencional, la modalidad que domina el gradiente absorbe toda la capacidad y el resto queda como decorativo.
La respuesta arquitectónica es el Multi-Stream Action Transformer (MSAT). Cada modalidad tiene su propio stream de procesamiento, y los cognition tokens comprimen la salida del VLM en una interfaz de tamaño fijo.
Los bloques tempranos mantienen las modalidades en streams paralelos; los bloques posteriores las fusionan para la decodificación de la acción, explicó RLWRLD. Los modelos vision-language-action (VLA) existentes fusionan modalidades dentro de un único stream de transformer, donde la modalidad que domina el gradiente absorbe toda la capacidad. MSAT da a cada modalidad un stream dedicado, y luego deja que los streams se comuniquen vía joint self-attention sin forzarlos a una representación compartida prematura.
RLDX-1 usa un VLM especializado en robots
Los VLM de propósito general son fuertes en razonamiento visual, pero no entienden automáticamente qué importa para el control robótico, afirmó RLWRLD. Para cerrar la brecha, RLDX-1 hace fine-tuning de Qwen3-VL 8B sobre un dataset VQA de trayectorias de robot apuntando a tres habilidades relevantes para la acción: razonamiento espacial entre el end-effector y los objetos objetivo, comprensión de tarea para identificar el subtask intermedio implícito en la observación actual, y action grounding para razonar sobre la acción de bajo nivel asociada al frame actual.
El modelo resultante, RLDX-1-VLM, sirve como backbone de razonamiento visual para la generación de acciones: +3,42 puntos porcentuales sobre el VLM vanilla en RoboCasa.
Una política basada en un único frame siempre va un paso atrás respecto a la escena, advirtió RLWRLD. El Motion Module tiene dos piezas complementarias: una capa de compresión de video tokens que alimenta observaciones multi-frame a través del VLM y comprime frames pasados en motion tokens vía average pooling, y una capa de motion learning en el vision encoder que modela auto-similitudes espacio-temporales (STSS), capturando rotación, velocidad y dinámica de interacción directamente desde features visuales.
En conjunto: +37,5 puntos porcentuales sobre GR00T N1.6 y π₀.₅ en la tarea de pick-and-place sobre cinta transportadora.
¿Qué hace el Physics Module y cómo usa datos humanos?
El Physics Module integra retroalimentación de tacto y torque en RLDX como modalidades nativas. Estas señales físicas son cruciales para tareas que requieren manipulación rica en contacto y sirven a dos funciones clave: estimación de peso y detección de contacto.
Cuando un robot sirve café, el módulo captura los cambios de peso en ambas manos para informar a RLDX exactamente cuándo detenerse. Para detección de contacto, un robot necesita identificar el momento exacto de contacto para pasar de aproximarse a tomar. Mientras los ángulos articulares ofrecen información ambigua sobre el timing de contacto, las señales de torque entregan cambios distintos y nítidos en el punto de contacto.
Cuando estos sensores no están disponibles, el stream sensorial se desactiva automáticamente para una degradación elegante a solo visión, permitiendo que un único modelo soporte distintas configuraciones de hardware.
El Cognition Interface adjunta 64 cognition tokens aprendibles al input del VLM. Vía attention, comprimen la secuencia completa en una representación de tamaño fijo que carga exactamente la información que el modelo de acción necesita. La ganancia de velocidad: +35 puntos porcentuales en inferencia (de 16,3 a 22,1 Hz).
Datos sintéticos y aprendizaje desde manos humanas
La teleoperación real por sí sola no puede poblar el espacio que una mano de cinco dedos debe cubrir. El pipeline de datos sintéticos de RLWRLD amplifica un seed set pequeño de demostraciones reales usando modelos de generación de video, como Cosmos-Predict2.
Un modelo de video fine-tuned sintetiza nuevas trayectorias a escala variando factores de escena: iluminación, superficies, posiciones y fondos. Un modelo de dinámica inversa luego anota los videos generados con etiquetas de acción, seguido de un filtro de calidad y consistencia de movimiento que retiene solo datos sintéticos físicamente plausibles que cumplen las instrucciones.
Esto produce datos sintéticos video-acción consistentes, beneficiosos para entrenamiento VLA, con un aumento aproximado de 5 veces en escala de datos, llevando a un 9,2% de ganancia en la tasa de éxito promedio sobre el benchmark GR-1 Tabletop.
No hay mejor profesor para una mano robótica diestra que una mano humana, agregó RLWRLD. La teleoperación es a menudo demasiado lenta e imprecisa para manipulación de cinco dedos, ya que los controladores convencionales fallan al capturar los reflejos de alta velocidad requeridos para tareas dinámicas como atrapar o reagarrar.
RLDX toma la ruta opuesta: graba desde la mano humana desnuda y cierra la brecha cinemática y morfológica en software, con un framework de retargeting construido para destreza de cinco dedos. Este pipeline produce más de 200 demostraciones por hora y escala más con aumentaciones automáticas.
El entrenamiento se hace en tres etapas: pre-entrenamiento para manipulación general usando un MSAT compartido con encoders/decoders por embodiment; mid-training para embodiments objetivo, añadiendo Memory y Physics Modules desde cero; y post-training para despliegue, donde el imitation learning solo deja espacio de mejora.