La gran mayoría de los supercomputadores y clusters de IA líderes hoy combinan CPUs para tareas de propósito general y orquestación con GPUs de IA para las cargas de cómputo paralelo masivo que permiten alcanzar rendimientos de clase exaflop. Pero en China estamos viendo una tendencia distinta: el país ha desplegado varios supercomputadores solo-CPU para cargas de trabajo de IA y HPC, en buena medida porque los vetos estadounidenses a la exportación de GPUs le impiden conseguir suficientes para sus máquinas más grandes.
El ejemplo más reciente es el Centro Nacional de Supercomputación de China, que desplegó una máquina de clase 1,54 exaflops basada en 20.480 CPUs Armv9 en Shenzhen.
¿Qué es exactamente el LX2?
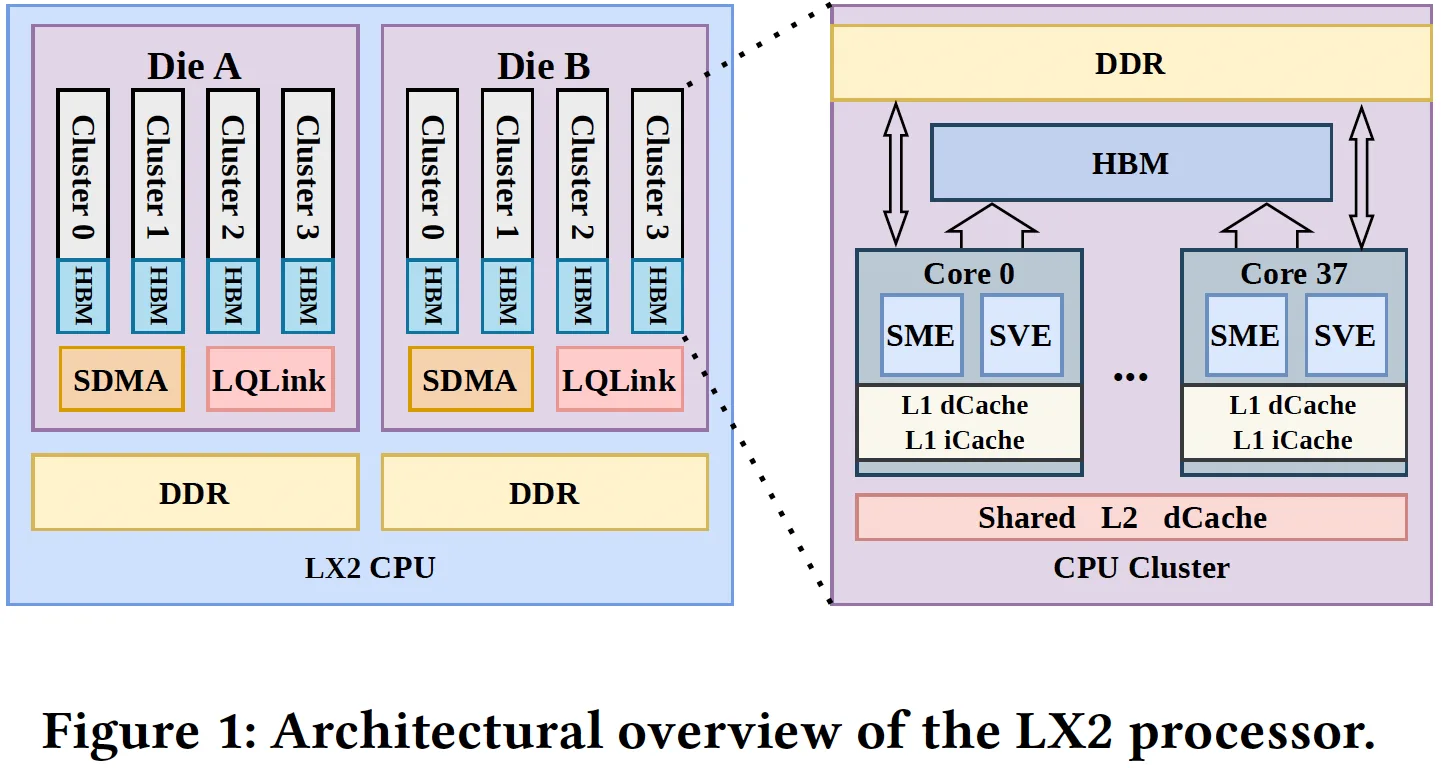
El supercomputador LineShine está construido alrededor de procesadores Armv9 LX2 custom, diseñados específicamente para cargas de IA y HPC a gran escala. El Centro Nacional de Supercomputación (NSCC) en Shenzhen no revela quién desarrolló el LX2, aunque Jon Peddie, de Jon Peddie Research, lo llama directamente el "Huawei LX2". El chip podría ser un CPU HPC custom de Huawei, un diseño conjunto NSCC con Huawei, o un proyecto independiente respaldado por el Estado chino.
Cada procesador LX2 usa dos chiplets de cómputo y tiene en total 304 núcleos CPU organizados en ocho clusters de 38 núcleos cada uno. Cada núcleo incluye unidades Arm SVE (Scalable Vector Extension) y SME (Scalable Matrix Extension), que aceleran operaciones vectoriales y matriciales típicas de entrenamiento IA y computación científica, con soporte para los formatos FP64, FP32, BF16, FP16 e INT8. Cada núcleo trae 32 kB de caché L1 de instrucciones y 32 kB de caché L1 de datos, mientras que cada cluster comparte 28,5 MB de caché L2.
El procesador usa un subsistema de memoria muy inusual que combina 32 GB de HBM on-package, con hasta 4 TB/s de ancho de banda, más hasta 256 GB de DDR5 off-package. Un esquema similar fue usado por el Armv8 A64FX de Fujitsu, que da vida al supercomputador Fugaku. El LX2 es probablemente el primer Armv9 para IA y HPC que adopta esta arquitectura de memoria.
Cada chiplet contiene cuatro dominios HBM y cuatro DDR; hay 16 dominios NUMA por procesador. El acceso HBM es muy sensible a la localidad, mientras que el DDR es más uniforme dentro de un die. Esto obligó a los desarrolladores a diseñar técnicas de placement y scheduling conscientes de la topología, ejecutadas por un motor SDMA dedicado para mover datos entre DDR y HBM.
En cuanto a rendimiento, un solo procesador LX2 entrega 60,3 TFLOPS en FP64, 240 TFLOPS en BF16/FP16 y 960 TOPS en INT8. A diferencia de los CPUs de servidor convencionales, la arquitectura aparece muy optimizada para cargas IA y matriciales densas, aun manteniendo el enfoque centrado en CPU. Sostener alta utilización de los motores SME requirió un trabajo intensivo de co-diseño entre kernels, scheduling de runtime, manejo de residencia en caché y placement tensorial a lo largo de la jerarquía HBM-DDR.
¿Qué tan grande es el sistema completo?

LineShine se compone de 20.480 nodos de cómputo. Cada nodo contiene dos procesadores LX2, y cada LX2 tiene 304 núcleos. En total, el sistema usa 40.960 procesadores LX2 con 2.451.840 núcleos CPU. La máquina está interconectada por la red de alta velocidad LingQi (LQLink) con 1,6 Tb/s por nodo.
El cluster entrega 1,54 exaflops/s de rendimiento BF16 de entrenamiento, y alcanza un pico de 2,16 exaflops/s durante el entrenamiento de un modelo generativo de compresión para observación terrestre de 6.300 millones de parámetros. Como xAI y otros operadores no publican el rendimiento pico de sus clusters basados en cientos de miles de GPU Nvidia, no se puede comparar directamente con Colossus o sistemas similares. Aun así, el rendimiento teórico pico de Colossus se estima en 497,9 exaflops, y con una utilización de FLOPS efectiva del 15% (similar a la de LineShine) entregaría unos 75 exaflops sostenidos.
En FP64 teórico, los 40.960 LX2 podrían entregar 2,47 exaflops, aunque el throughput FP64 real depende de múltiples factores.
¿Por qué importa más allá de China?
Los supercomputadores AI y HPC solo-CPU ofrecen varias ventajas sobre los sistemas heterogéneos CPU+GPU, sobre todo para tareas científicas complejas que combinan entrenamiento IA con ingestión masiva de datos, preprocesamiento, simulación y orquestación. Al correr todo sobre el mismo procesador y espacio de memoria, evitan los problemas del cómputo heterogéneo: transferencias CPU-GPU costosas y demandantes en ancho de banda, modelos de programación complejos, limitaciones de memoria GPU y stacks de software específicos del acelerador.
Además, los sistemas homogéneos CPU pueden exponer pools de memoria coherente mucho más grandes combinando HBM con DDR de gran capacidad, útiles para datasets científicos masivos, recuperación aumentada por generación y contextos largos. También son atractivos para aplicaciones AI for Science con control de flujo irregular, entrada/salida distribuida o patrones de ejecución que no se mapean eficientemente sobre GPUs.
El gran tradeoff es que los sistemas solo-CPU suelen ser menos eficientes energéticamente y entregar menor throughput de IA densa que los basados en GPU, motivo por el cual la industria global apuesta por arquitecturas heterogéneas. Para China, el cálculo es político antes que técnico: depender menos de GPUs Nvidia y del stack CUDA importa más que el costo por watt.