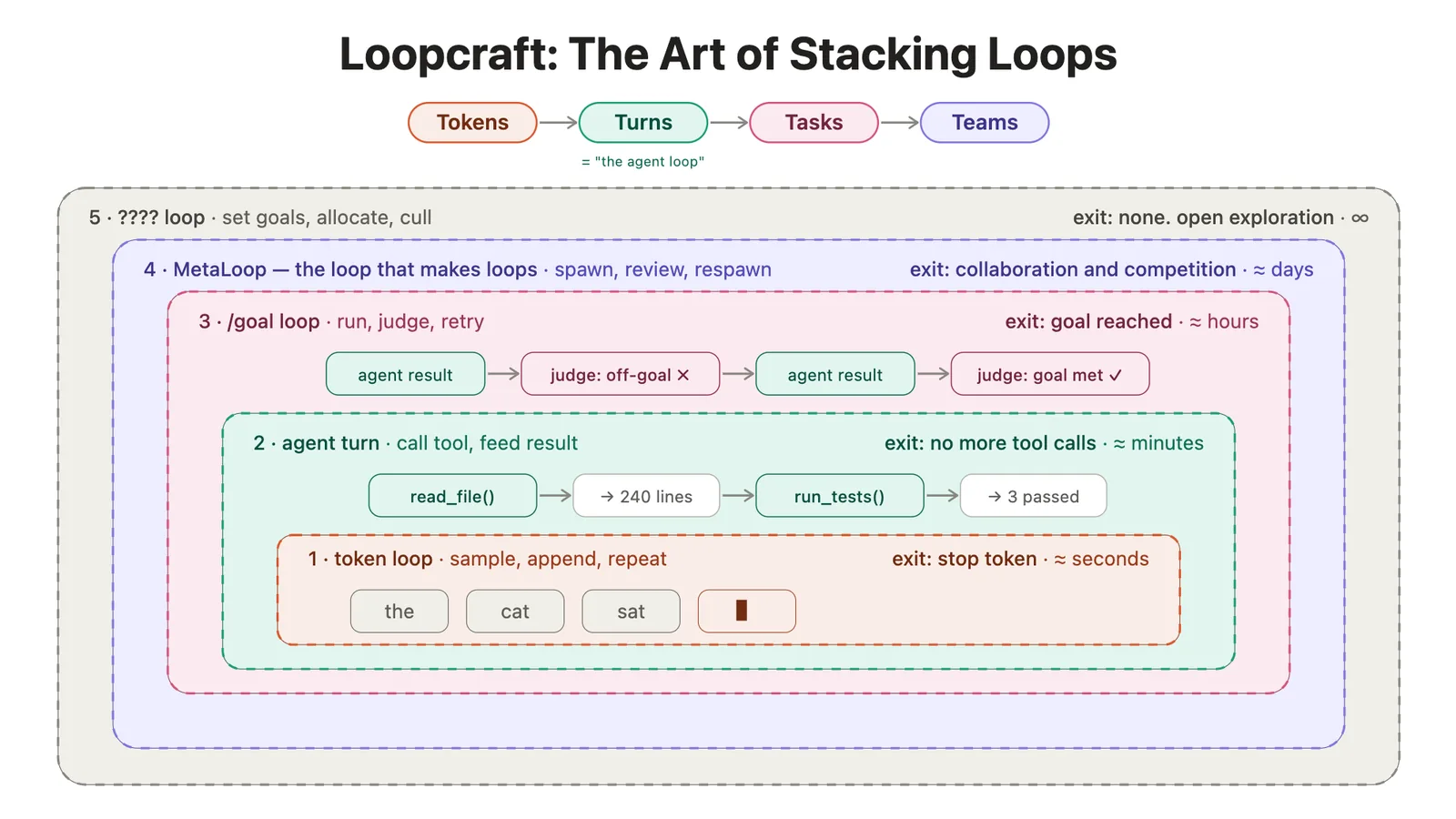
En este tutorial, MarkTechPost explora la arquitectura detrás de un agente autónomo con memoria híbrida. El sistema combina búsqueda semántica por vectores, recuperación basada en palabras clave y un loop modular de dispatch de tools para crear un agente capaz de razonar, recordar y actuar de forma autónoma. El recorrido va desde las interfaces abstractas que imponen una separación clara de responsabilidades hasta un agente vivo que administra su propia memoria de largo plazo.
¿Qué dependencias se necesitan?

El primer paso es instalar las dependencias y configurar el entorno con los imports necesarios. La API key de OpenAI se recoge con getpass para que no quede impresa en el output del terminal o el notebook. Se definen dos constantes globales que el resto del código va a usar: el modelo de embeddings y el modelo de chat.
!pip install openai numpy rank_bm25 --quiet
import os, json, math, re, time, getpass
from abc import ABC, abstractmethod
from dataclasses import dataclass, field
from typing import Any, Callable, Dict, List, Optional, Tuple
import numpy as np
from rank_bm25 import BM25Okapi
from openai import OpenAI
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY") or getpass.getpass("Enter your OpenAI API key (hidden): ")
client = OpenAI(api_key=OPENAI_API_KEY)
EMBED_MODEL = "text-embedding-3-small"
CHAT_MODEL = "gpt-4o-mini"¿Qué interfaces componen la arquitectura?
El tutorial define tres clases base abstractas que actúan como contratos: MemoryBackend, LLMProvider y Tool. Cada componente concreto debe respetar esa interfaz, lo que permite intercambiar implementaciones (por ejemplo, cambiar OpenAI por otro proveedor) sin tocar el agente.
class MemoryBackend(ABC):
@abstractmethod
def store(self, text: str, metadata: Dict[str, Any]) -> str: ...
@abstractmethod
def search(self, query: str, top_k: int = 5) -> List[Dict[str, Any]]: ...
@abstractmethod
def list_all(self) -> List[Dict[str, Any]]: ...
class LLMProvider(ABC):
@abstractmethod
def complete(self, messages: List[Dict], tools: Optional[List] = None) -> Dict: ...
class Tool(ABC):
name: str
description: str
@abstractmethod
def run(self, **kwargs) -> str: ...¿Cómo funciona la memoria híbrida?
La clase HybridMemory guarda embeddings para búsqueda vectorial y mantiene un índice BM25 vivo para búsqueda por palabras clave. Cuando llega una consulta, ambos rankings se fusionan usando Reciprocal Rank Fusion con un parámetro de constante RRF_K = 60, una elección estándar en la literatura de information retrieval.
class HybridMemory(MemoryBackend):
RRF_K = 60
def __init__(self):
self._chunks: List[MemoryChunk] = []
self._bm25: Optional[BM25Okapi] = None
self._counter = 0
def search(self, query: str, top_k: int = 5) -> List[Dict[str, Any]]:
if not self._chunks:
return []
n = len(self._chunks)
top_k = min(top_k, n)
[q_vec] = _embed([query])
cos_scores = np.array([np.dot(q_vec, c.embedding) for c in self._chunks])
vec_ranks = {self._chunks[i].id: rank + 1
for rank, i in enumerate(np.argsort(-cos_scores))}
bm25_scores = self._bm25.get_scores(_tokenise(query))
kw_ranks = {self._chunks[i].id: rank + 1
for rank, i in enumerate(np.argsort(-bm25_scores))}
rrf: Dict[str, float] = {}
for chunk in self._chunks:
cid = chunk.id
rrf[cid] = (1.0 / (self.RRF_K + vec_ranks.get(cid, n + 1)) +
1.0 / (self.RRF_K + kw_ranks.get(cid, n + 1)))
ranked_ids = sorted(rrf, key=lambda x: rrf[x], reverse=True)[:top_k]
# devuelve los chunks correspondientes con sus scores RRF, coseno y BM25Los embeddings se generan con text-embedding-3-small de OpenAI y se normalizan a vectores unitarios. El BM25 se construye sobre tokens minúsculos extraídos por regex. La búsqueda devuelve los top-k chunks con su rrf_score, su similitud coseno individual y su score BM25 individual, lo que permite diagnosticar qué señal pesó más en cada resultado.
¿Cómo se integra OpenAI sin acoplar el agente?
La clase OpenAIProvider implementa LLMProvider y normaliza la respuesta de OpenAI en un diccionario provider-agnostic que el agente puede consumir sin saber qué modelo está abajo:
class OpenAIProvider(LLMProvider):
def __init__(self, model: str = CHAT_MODEL, temperature: float = 0.2):
self.model = model
self.temperature = temperature
def complete(self, messages: List[Dict], tools: Optional[List] = None) -> Dict:
kwargs: Dict[str, Any] = dict(model=self.model, messages=messages, temperature=self.temperature)
if tools:
kwargs["tools"] = tools
kwargs["tool_choice"] = "auto"
response = client.chat.completions.create(**kwargs)
msg = response.choices[0].message
result: Dict[str, Any] = {"role": "assistant", "content": msg.content or ""}
if msg.tool_calls:
result["tool_calls"] = [
{"id": tc.id, "type": "function",
"function": {"name": tc.function.name, "arguments": tc.function.arguments}}
for tc in msg.tool_calls
]
return result¿Qué tools recibe el agente?
El tutorial implementa cuatro tools concretas, cada una respetando el contrato Tool:
- MemoryStoreTool: guarda un hecho en memoria de largo plazo con una categoría opcional (user_pref, task, fact).
- MemorySearchTool: busca en la memoria de largo plazo, devuelve los top-k matches con su score RRF.
- CalculatorTool: evalúa expresiones matemáticas seguras (ejemplo:
2 ** 10 + sqrt(144)). Restringe el entorno deevala funciones de math másabsyround. - WebSnippetTool: una herramienta de búsqueda web simulada con un mini knowledge base de ejemplo. El tutorial recomienda reemplazarla por una API real en producción.
Cada tool expone un schema JSON compatible con el formato de tool-calling de OpenAI, lo que permite al modelo decidir cuándo y con qué argumentos invocarla. La invocación se canaliza por el dispatcher del agente, que conecta el tool_calls emitido por el LLM con la clase concreta que implementa esa función.
¿Cómo se modela la personalidad del agente?
Para mantener consistencia de voz entre turnos, el tutorial define una dataclass AgentPersona que captura nombre, rol, rasgos, frases prohibidas y metas. Esta persona se inyecta como contexto sistema en cada llamada al LLM.
@dataclass
class AgentPersona:
name: str
role: str
traits: List[str]
forbidden_phrases: List[str] = field(default_factory=list)
goals: List[str] = field(default_factory=list)¿Por qué importa esta arquitectura?
El patrón ilustrado combina varios elementos que en sistemas RAG productivos suelen aparecer separados. La búsqueda híbrida vectorial + BM25 con fusión por RRF es estándar industrial en motores de búsqueda modernos. La separación por interfaces (MemoryBackend, LLMProvider, Tool) permite testear cada pieza por separado y migrar de OpenAI a un proveedor local como Ollama, Together o Anthropic con solo escribir una nueva subclase de LLMProvider.
Para integradores chilenos, el tutorial es útil como scaffolding de referencia: el costo en tokens de un proof of concept con text-embedding-3-small (USD 0,02 por millón de tokens) y gpt-4o-mini (USD 0,15 input / USD 0,60 output por millón) se mantiene bajo USD 1 para corridas de cientos de consultas, lo que vuelve viable un prototipo de agente con memoria en hardware modesto, incluso un VPS de USD 5/mes.
El tutorial completo, con el código del agente principal y ejemplos de ejecución, está disponible en MarkTechPost.