Un equipo de investigadores de China liberó AntAngelMed, un modelo médico de lenguaje grande y open source que el equipo describe como el más grande y capaz de su tipo actualmente disponible.
¿Qué es exactamente AntAngelMed?
AntAngelMed es un modelo de lenguaje de dominio médico con 103.000 millones de parámetros totales, pero no activa todos esos parámetros durante la inferencia. En cambio, usa una arquitectura Mixture-of-Experts (MoE) con un ratio de activación de 1/32, lo que significa que solo 6.100 millones de parámetros están activos en cualquier momento al procesar una consulta.
Ayuda entender cómo funcionan las arquitecturas MoE. En un modelo denso estándar, cada parámetro participa en el procesamiento de cada token. En un modelo MoE, la red se divide en muchos subnetwork "expertos", y un mecanismo de enrutamiento selecciona solo un pequeño subconjunto de ellos para manejar cada entrada. Esto permite tener un conteo total de parámetros muy grande, que típicamente correlaciona con una fuerte capacidad de conocimiento, mientras mantiene el costo real de cómputo de la inferencia proporcional al número menor de parámetros activos.
AntAngelMed hereda este diseño de Ling-flash-2.0, un modelo base desarrollado por inclusionAI y guiado por lo que el equipo llama Ling Scaling Laws. Las optimizaciones específicas aplicadas encima incluyen: granularidad refinada de expertos, ratio de expertos compartidos ajustado, mecanismos de balance de atención, enrutamiento sigmoideo sin pérdida auxiliar, una capa MTP (Multi-Token Prediction), QK-Norm y Partial-RoPE (Rotary Position Embedding aplicado a un subconjunto de cabezas de atención en lugar de a todas). Según el equipo de investigación, estas decisiones de diseño en conjunto permiten que modelos MoE de activación pequeña entreguen hasta 7 veces la eficiencia comparado con arquitecturas densas de tamaño similar. Con solo 6.100 millones de parámetros activados, AntAngelMed puede igualar aproximadamente el rendimiento de un modelo denso de 40.000 millones.
¿Cómo se entrenó el modelo?
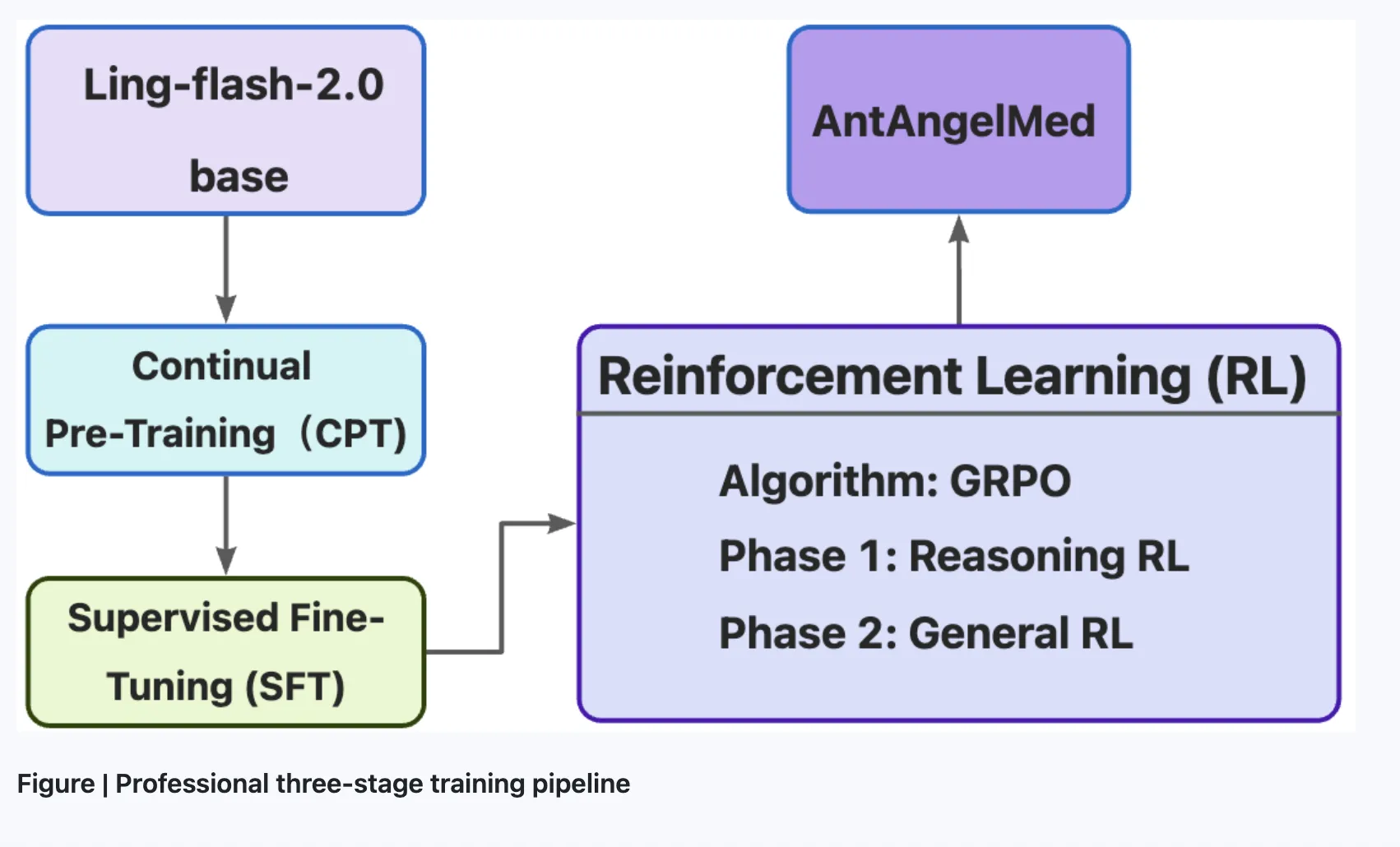
AntAngelMed usa un pipeline de entrenamiento en tres etapas diseñado para superponer comprensión general del lenguaje sobre una profunda adaptación al dominio médico.
La primera etapa es preentrenamiento continuo sobre corpus médicos a gran escala, incluyendo enciclopedias, texto web y publicaciones académicas. Esta fase se construye sobre el checkpoint de Ling-flash-2.0, dando al modelo una base sólida de razonamiento general antes de comenzar la especialización médica.
La segunda etapa es Supervised Fine-Tuning (SFT), donde el modelo se entrena con un dataset de instrucciones de múltiples fuentes. Este dataset mezcla tareas de razonamiento general (matemáticas, programación, lógica) para preservar capacidades de chain-of-thought, junto con escenarios médicos como Q&A doctor-paciente, razonamiento diagnóstico y casos de seguridad y ética.
La tercera etapa es Reinforcement Learning usando el algoritmo GRPO (Group Relative Policy Optimization), combinado con modelos de recompensa específicos por tarea. GRPO, introducido originalmente en el paper de DeepSeekMath, es una variante de PPO que estima los baselines a partir de puntajes de grupo en lugar de un modelo crítico separado, haciéndolo computacionalmente más liviano. Las señales de recompensa están diseñadas para moldear el comportamiento del modelo hacia empatía, respuestas clínicas estructuradas, límites de seguridad y razonamiento basado en evidencia, todo con el objetivo de reducir alucinaciones en preguntas médicas.
¿Cómo rinde en inferencia y benchmarks?
En hardware H20, AntAngelMed supera los 200 tokens por segundo, lo que según el equipo de investigación es aproximadamente 3 veces más rápido que un modelo denso de 36 mil millones de parámetros. Con extrapolación YaRN soporta una longitud de contexto de 128K, suficiente para manejar documentos clínicos completos, historiales extensos de pacientes o diálogos médicos multi-turno.
El equipo también liberó una versión cuantizada FP8 del modelo. Cuando esta cuantización se combina con la optimización de speculative decoding EAGLE3, el throughput de inferencia con concurrencia de 32 mejora significativamente sobre FP8 solo: 71% en HumanEval, 45% en GSM8K y 94% en Math-500.
En HealthBench, el benchmark open source de evaluación médica de OpenAI que usa diálogos médicos simulados multi-turno para medir desempeño clínico del mundo real, AntAngelMed se ubica en primer lugar entre todos los modelos open source y supera a varios modelos propietarios top, con una ventaja particularmente significativa en el subconjunto HealthBench-Hard.
En MedBench, un benchmark para LLMs de salud en chino que cubre 36 datasets curados independientemente y aproximadamente 700.000 muestras a través de cinco dimensiones (Q&A de conocimiento médico, comprensión, generación, razonamiento complejo y seguridad/ética), AntAngelMed ocupa el primer lugar general.
¿Dónde está disponible y bajo qué licencia?
Los pesos del modelo están disponibles bajo Apache 2.0 y el repositorio de código bajo MIT. Una variante cuantizada FP8 está disponible por separado. El modelo puede descargarse desde Hugging Face, ModelScope y GitHub.
Soporta inferencia con Hugging Face Transformers (requiere trust_remote_code=True para el código de enrutamiento MoE), vLLM v0.11.0 con paralelismo tensorial en 4 GPUs, SGLang con FlashAttention-3 y vLLM-Ascend para NPUs Huawei Ascend 910B.
Para integradores de salud en Chile y América Latina, un modelo médico open source con licencia Apache 2.0 que iguala a un denso de 40B activando solo 6.1B parámetros abre la puerta a hospitales y clínicas privadas que necesitan inferencia local por privacidad de datos: un servidor con dos GPUs H100 o cuatro H20 alcanzaría para servir asistente clínico en HIS hospitalarios. La barrera real sigue siendo regulatoria (validación FDA equivalente vía ISP) más que técnica o económica. AntAngelMed fue desarrollado por el Health Information Center de la provincia de Zhejiang, Ant Healthcare y Zhejiang Anzhen'er Medical AI Technology.