![[AINews] Gemma 4: Los mejores modelos abiertos multimodales pequeños, dramáticamente mejores que Gemma 3 en todos los sentidos](https://images.mechatronicstore.cl/articles/ae07414bf74b/a1475c7d6358adaf.webp)
¡Una actualización bienvenida de Google!
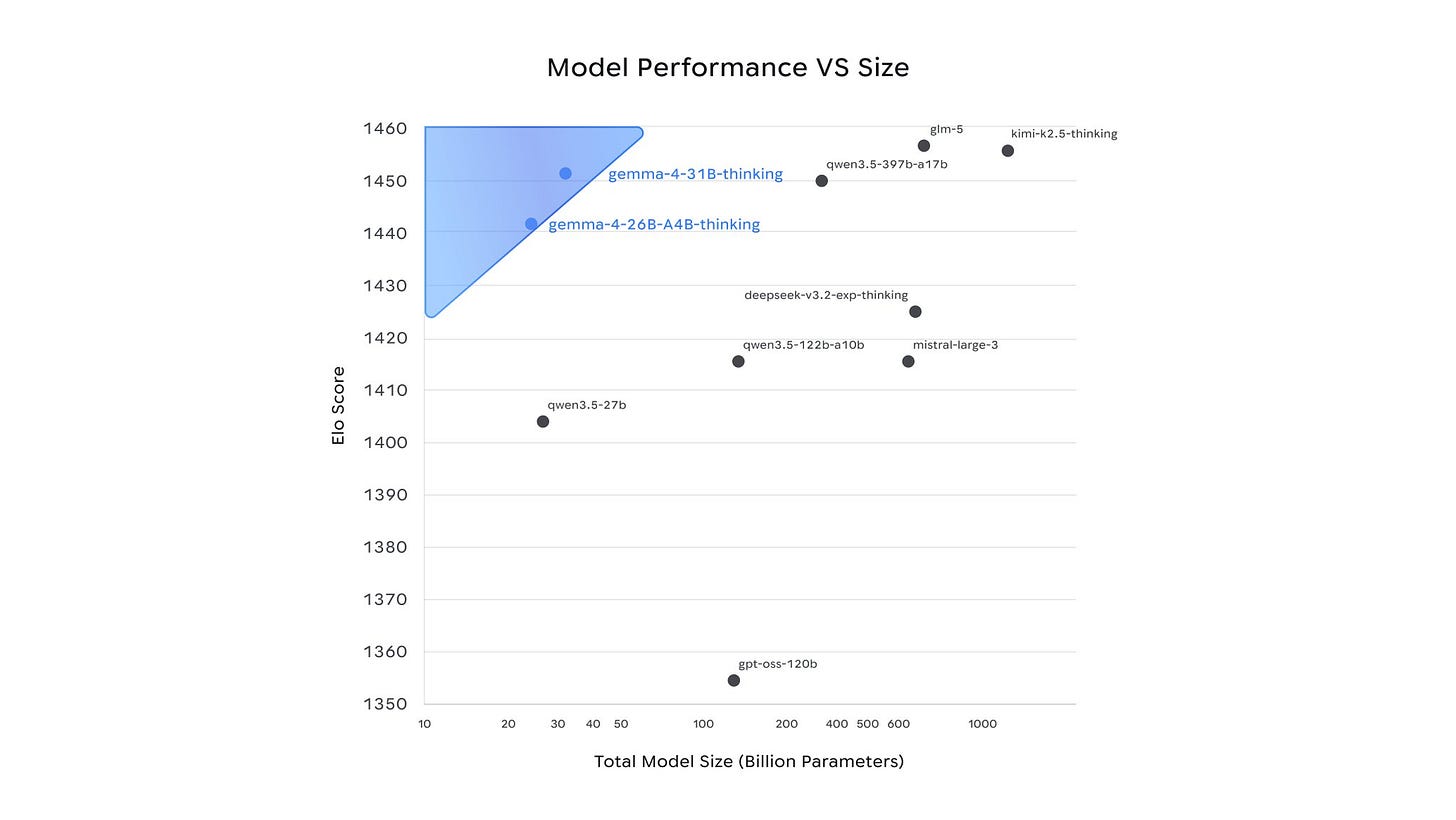
Las salidas repentinas del Instituto Allen y el estado de limbo de GPT-OSS han dejado en duda el futuro de American Open Models, por lo que mantener Google DeepMind al ritmo de Gemma 4 es una actualización muy, muy bienvenida. La variante densa 31B empata con Kimi K2.5 (744B-A40B) y Z.ai GLM-5 (1T-A32B) para los mejores modelos abiertos del mundo, pero con muchos menos parámetros totales (con otras opciones de arco interesantes, ver más abajo):
Esta imagen de Arena muestra el progreso a lo largo de los años (exagerado por la clasificación ordinal # en lugar de numérica, pero los bancos verdaderamente estándar como GPQA y AIME también mejoraron enormemente frente a Gemma 3):
La licencia también sabe mejora con una licencia Apache 2.0 adecuada, y "procesan vídeo e imágenes de forma nativa, admiten resoluciones variables y sobresalen en tareas visuales como OCR y comprensión de gráficos. Además, los modelos E2B y E4B cuentan con entrada de audio nativa para reconocimiento y comprensión de voz".
Las excelentes capacidades del dispositivo hacen que uno sabe pregunte si estas son la base de los modelos que sabe implementarán en New Siri bajo el acuerdo con Apple….
Noticias de IA del 1/4/2026 al 2/4/2026. Revisamos 12 subreddits, 544 Twitters y no hay más Discords. El sitio web de AINews le permite buscar todos los números anteriores. Como recordatorio, AINews es ahora una sección de Latent Space. ¡Puedes optar por recibir o no frecuencias de correo electrónico!
Lanzamiento Gemma 4 de Google DeepMind: peso abierto, Apache 2.0, multimodal, de contexto largo, además de una rápida implementación del ecosistema
- Gemma 4 es el mayor salto de capacidades y licencias de peso abierto de Google en un año: Google/DeepMind lanzó Gemma 4 como una familia de modelos posicionados explícitamente para razonamiento + flujos de trabajo agentes e implementación local/edge, ahora bajo una licencia Apache 2.0 comercialmente permisiva (un cambio notable con respecto a las licencias anteriores de Gemma). Vea los hilos de lanzamiento de @GoogleDeepMind, @GoogleAI y @Google, con las estadísticas de adopción y encuadre de Jeff Dean (Gemma 3: 400 millones de descargas, 100 000 variantes) en @JeffDean.
- Línea de modelos + especificaciones clave: sabe anunciaron cuatro tamaños: 31B denso, 26B MoE (“A4B”, ~4B activo) y dos modelos de borde “efectivos” E4B y E2B destinados a dispositivos móviles/IoT con soporte multimodal nativo (texto/visión/audio llamado para borde). Los aspectos más destacados de DeepMind incluyen llamadas a funciones + JSON estructurado y contexto largo de hasta 256 KB (modelos grandes) en @GoogleDeepMind y @GoogleAI. Los resúmenes de la comunidad y las guías sobre “cómo ejecutar localmente” proliferaron rápidamente, p. @_philschmid y @UnslothAI.
- Señales de referencia tempranas (con advertencias): Arena/Texto: Arena informa que Gemma-4-31B ocupa el puesto número 3 entre los modelos abiertos (y el puesto 27 en general), con Gemma-4-26B-A4B en el puesto número 6 abierto en @arena; Más tarde, Arena lo llama el modelo abierto de EE. UU. Número uno en su tabla de clasificación abierta en @arena. Razonamiento científico: Artificial Analysis informa GPQA Diamond 85,7% para Gemma 4 31B (razonamiento) y enfatiza la eficiencia del token (~ 1,2 millones de tokens de salida) frente a sus pares en @ArtificialAnlys y @ArtificialAnlys. Varias publicaciones enfatizan la sorpresa de escala/eficiencia (por ejemplo, “supera a los modelos 20 veces su tamaño”), pero señalan que las tablas de clasificación basadas en preferencias sabe pueden jugar; La lectura más mesurada de Raschka está en @rasbt.
- El soporte del ecosistema del día 0 sabe convirtió en parte de la historia: Gemma 4 aterrizó inmediatamente en pilas de servicio + locales comunes: llama.cpp Soporte del día 0: @ggerganov Ollama (requiere 0.20+): @ollama vLLM Soporte del día 0 (GPU/TPU/etc.): @vllm_project Disponibilidad de LM Studio: @lmstudio Transformers/llama.cpp/transformers.js callout: @mervenoyann Modular/MAX inferencia de producción “en días”: @clattner_llvm
- Las anécdotas sobre el rendimiento de la inferencia local sabe volvieron inusualmente concretas: “Brew install + llama-server” sabe convirtió en la frase canónica para muchos: @julien_c. Demostración de rendimiento de llama.cpp: Gemma 4 26B A4B Q8_0 en M2 Ultra, WebUI integrada, compatibilidad con MCP, “300 t/s (vídeo en tiempo real)” en @ggerganov (con una advertencia de seguimiento sobre la recitación rápida/decodificación especulativa en @ggerganov). Rendimiento de contexto largo de RTX 4090 + detalles cuantitativos de TurboQuant KV en @basecampbernie. Ejecución local del navegador a través de la demostración WebGPU/transformers.js anotada por @xenovacom y amplificada por @ClementDelangue.
Notas de arquitectura de Gemma 4: atención híbrida, opciones de capas de MoE y trucos de eficiencia
Detalles inusuales del transformador
- resaltado de eliebakouch: incrustaciones por capa en variante pequeña sin escala de atención explícita (lo que sugiere que puede ser absorbida en pesos normativos) Norma QK + norma V K/V compartida para variante grande Compartir caché KV agresivo en variante pequeña tamaños de ventana deslizante 512 y 1024 sin sumideros limitación suave RoPE de dimensión parcial con theta diferente para capas locales/globales
- Grad62304977 respondió que la escala de atención faltante probablemente esté fusionada con las ponderaciones de la norma QK.
- opciones de arquitectura adicionales resumidas en baseten: mecanismos de atención alternativos RoPE proporcional Incrustaciones por capa (PLE) Uso compartido de caché KV Manejo nativo de relación de aspecto para visión Ventana de marco más pequeña para audio
- norpadon lo llamó “no es en absoluto un transformador estándar”.
- rasbt ofreció una lectura más conservadora para el 31B denso: la arquitectura parece “prácticamente sin cambios en comparación con Gemma 3”, aparte del soporte multimodal, conservando un mecanismo de atención híbrido 5:1 local/global y el GQA clásico, lo que sugiere que el mayor salto probablemente sabe debió más a la receta de entrenamiento y los datos que a un cambio radical en la arquitectura del modelo denso.
- Tomas de “No es un transformador estándar”, además de deltas específicas: un hilo marcó que Gemma 4 tiene una “arquitectura con cerebro galáctico” en @norpadon, seguido de notas más específicas sobre cómo el MoE de Gemma difiere de DeepSeek/Qwen (Gemma usa bloques MoE como capas separadas agregadas junto con los bloques MLP normales) en @norpadon.
- Se están circulando detalles concretos de bajo nivel: un resumen conciso de las peculiaridades (por ejemplo, sin escala de atención explícita, norma QK/V, uso compartido de KV, tamaños de ventanas deslizantes, RoPE parcial + theta diferente, limitación suave, incrustaciones por capa) está en @eliebakouch. La publicación de lanzamiento de Baseten también enumera "innovaciones arquitectónicas" similares (PLE, uso compartido de caché KV, RoPE proporcional, manejo de relación de aspecto para la visión, ventana de marco de audio más pequeña) en @baseten.
- Lectura de Raschka: cambio arquitectónico mínimo, gran cambio de receta/datos: Raschka sostiene que Gemma 4 31B está arquitectónicamente cerca de Gemma 3 27B, todavía usa un patrón híbrido de ventana deslizante + atención global y GQA, lo que implica que el salto probablemente sea una receta/datos de entrenamiento en lugar de una revisión de la arquitectura: @rasbt.
Agentes, ingeniería de arneses e impulso de “agentes locales” (Hermes/OpenClaw + bucles de entrenamiento de modelos/arneses)
- Los modelos abiertos como motores de agentes son ahora un posicionamiento generalizado: varias publicaciones enmarcan a Gemma 4 como el modelo local “perfecto” para pilas de agentes abiertos (OpenClaw/Hermes/Pi/opencode). Consulte @ClementDelangue, @mervenoyann y @ben_burtenshaw.
- Crecimiento de Hermes Agent + memoria conectable: Hermes Agent alcanzó un importante hito de uso y solicitó información sobre la hoja de ruta: @Teknium. Las integraciones de memoria sabe ampliaron a múltiples proveedores a través de un nuevo sistema conectable: @Teknium. Un complemento de índice semántico local (“Enzyme”) sabe presentó como una solución al problema de “demasiados archivos de espacio de trabajo” con incrustación local y consultas de 8 ms: @jphorism.
- Aprovechar la ingeniería como foso (y bucle): una sólida tesis de “modelo-bucle de entrenamiento de arnés” (modelos abiertos + trazas + ajuste de infraestructura) sabe articuló en @Vtrivedy10 y sabe hizo eco de manera más general en @Vtrivedy10. Relacionado: LangChain señala que los modelos abiertos son "lo suficientemente buenos" en el uso/recuperación/operaciones de archivos de herramientas para impulsar arneses como Deep Agents en @ hwchase17.
- Autocuración del agente + tendencias de observabilidad: @hwchase17 hace referencia a un blog sobre bucles de retroalimentación de agentes GTM de “autocuración” y lo amplía @Vtrivedy10. LangSmith informa que la participación de Azure en el tráfico de OpenAI aumentó del 8% al 29% en 10 semanas, según 6.700 millones de ejecuciones de agentes, lo que sugiere que la gobernanza y el cumplimiento empresarial están impulsando las decisiones de enrutamiento: @LangChain.
Herramientas e infraestructura: núcleos, pilas de ajuste fino, ergonomía de bases de datos vectoriales, extracción de documentos
- Nuevo kernel de atención lineal: un kernel de atención lineal CUDA está disponible en @eliebakouch (enlace al repositorio en tweet).
- Axolotl v0.16.x: el lanzamiento de Axolotl enfatiza las ganancias de velocidad/memoria MoE + LoRA (sabe afirma que es 15 veces más rápido, 40 veces menos memoria) y el entrenamiento asíncrono GRPO (58 % más rápido), además de una revisión de los documentos en @winglian y @winglian. El soporte de Gemma 4 sigue en @winglian.
- Ergonomía de Vector DB: turbopuffer agrega múltiples columnas vectoriales por documento (diferentes atenuaciones/tipos/índices) en @turbopuffer.
- Pila de automatización de documentos: LiteParse + Extract v2: analizador de documentos de código abierto LiteParse: análisis de texto espacial con cuadros delimitadores, rápido en archivos PDF grandes con muchas tablas, lo que permite realizar seguimientos de auditoría hasta el origen en @jerryjliu0. Extracto v2 (LlamaIndex/LlamaParse): niveles simplificados, configuraciones de extracto guardadas, análisis configurable antes de la extracción, período de transición para v1 en @llama_index y contexto adicional de @jerryjliu0.
Actualizaciones de la organización Frontier: interpretabilidad antrópica, distribución de productos OpenAI y “Computadora para impuestos” de Perplexity
- Antrópico: “Vectores de emociones” dentro de Claude: Antrópico informa representaciones de conceptos de emociones internas que pueden aumentarse o disminuirse y afectar de manera mensurable el comportamiento (por ejemplo, aumentar un vector “desesperado” aumenta las trampas; “calma” lo reduce). Los hilos principales son @AnthropicAI, @AnthropicAI y @AnthropicAI. El trabajo también desencadenó disputas sobre citas/precedentes en la comunidad de interp (por ejemplo, @aryaman2020, @dribnet y discusión sobre las publicaciones de vgel a través de @jeremyphoward).
- OpenAI: cambios de precios de CarPlay + Codex: Modo de voz ChatGPT en Apple CarPlay implementado para iOS 26.4+: @OpenAI. Precios basados en el uso de Codex en ChatGPT Business/Enterprise (más créditos promocionales): @OpenAIDevs. Greg Brockman refuerza “intentar en el trabajo sin un compromiso inicial”: @gdb.
- Perplexity: “Computadora para impuestos” agente: Perplexity lanzó un flujo de trabajo para ayudar a redactar/revisar las declaraciones de impuestos federales (“Navigate my taxs”) en @perplexity_ai con detalles en @perplexity_ai.
Tweets principales (por participación, filtrados por tecnología/producto/investigación)
- Lanzamiento de Gemma 4 (peso abierto, Apache 2.0): @Google, @GoogleDeepMind, @demishassabis, @GoogleAI
- Investigación interp antrópica “Conceptos/vectores de emoción”: @AnthropicAI
- Karpathy en “LLM Knowledge Bases” (obsidiana + flujo de trabajo wiki de rebajas compilado): @karpathy
- Cursor 3 (interfaz de colaboración entre agentes): @cursor_ai
- ChatGPT en CarPlay: @OpenAI
- Demostración de rendimiento local de llama.cpp + MCP/WebUI: @ggerganov
- Perplejidad “Computadora para Impuestos”: @perplexity_ai
/r/LocalLlama + /r/localLLM Resumen
1. Lanzamientos y características del modelo Gemma 4
Sigue leyendo con una prueba gratuita de 7 días
Suscríbete a Latent.Space para seguir leyendo esta publicación y obtener 7 días de acceso gratuito a los archivos completos de las publicaciones.



