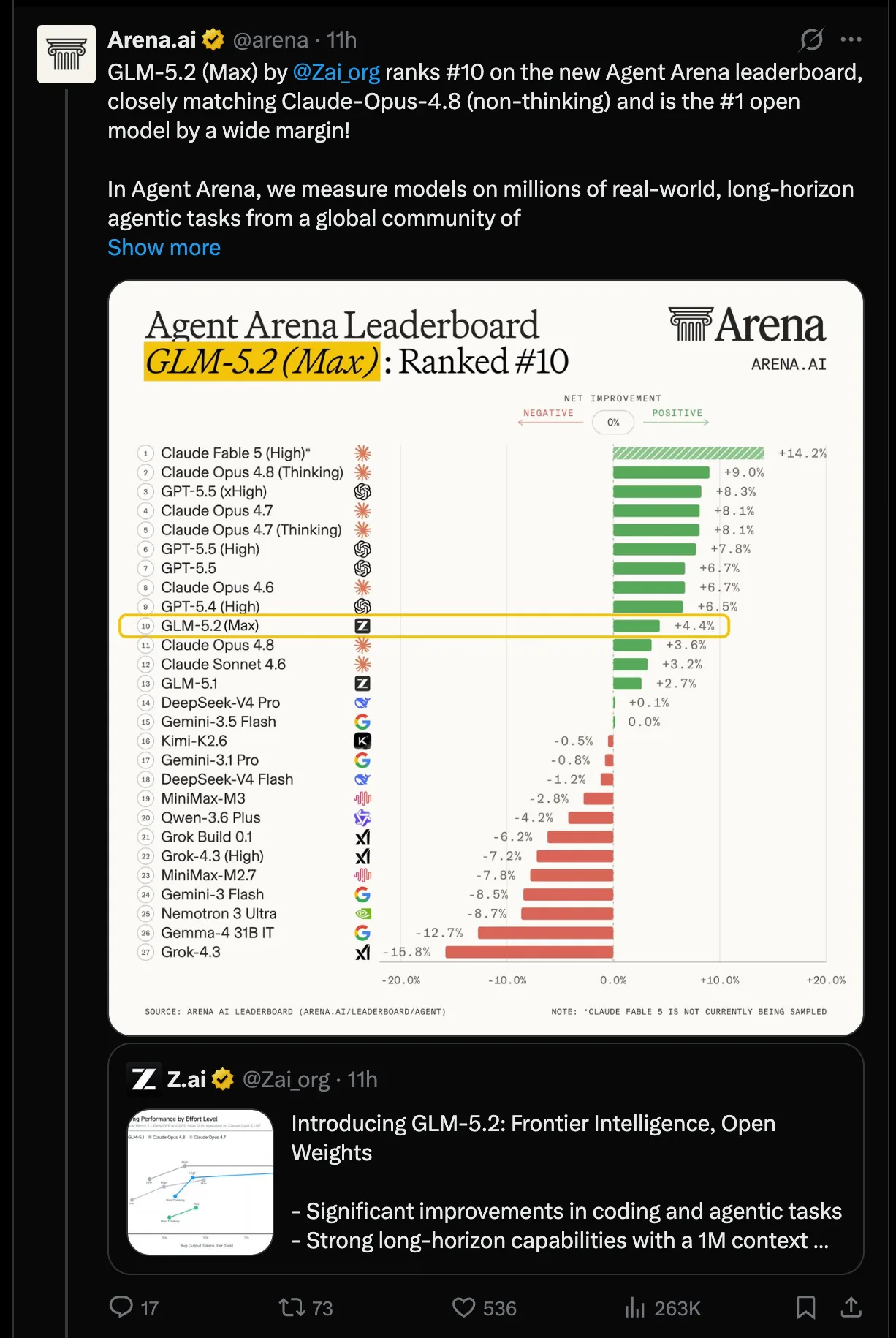
La industria reportera de IA suele desconfiar de los modelos abiertos: salen con benchmarks impecables y se desvanecen en un mes. Pero GLM-5.2 de Zhipu viene rompiendo ese patrón con varias señales independientes que convergieron esta semana.

Jeremy Howard, fundador de fast.ai y poco dado al hype, elogió el modelo y lo describió como "al menos tan bueno como Opus 4.8 y GPT-5.5" para su uso diario, con la salvedad de que aún no soporta visión. Mat Velloso dijo que es el primer modelo abierto que pasa su barra de "daily driver". Y la comunidad de r/LocalLLaMA ratificó la lectura desde el frente local.
¿Qué cambia en GLM-5.2 a nivel arquitectura?
Sobre las capas MLA y DSA heredadas de DeepSeek y modelos GLM previos, Zhipu agregó IndexShare, una técnica que reutiliza índices top-k de atención esparsa entre grupos de capas para reducir el costo de inferencia en contextos de 1 millón de tokens. El gap interno reportado por Zixuan Li al pasar de GLM-5.1 a GLM-5.2 en tareas de desarrollo de aplicaciones es brutal: de 21 sobre 70 a 48 sobre 70, según las pruebas internas del equipo.
La distribución también es agresiva: acceso gratuito por una ventana limitada vía Hugging Face Inference Providers, builds GGUF locales por llama.cpp y Unsloth, y aparición rápida en OpenRouter. Zhipu está empujando para que la prueba sea inmediata y barata, no para que el modelo viva detrás de una API propia.
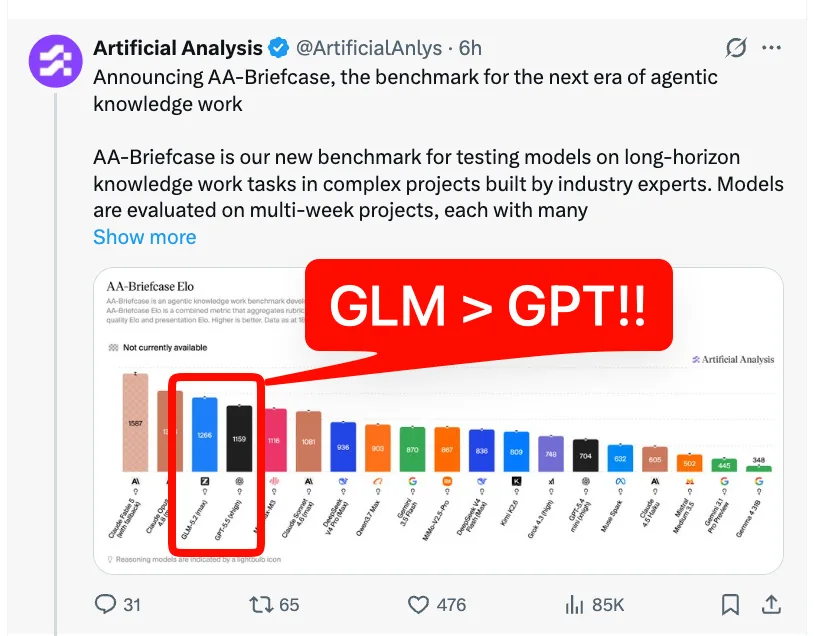
El benchmark que ordena la jerarquía: AA-Briefcase
Artificial Analysis lanzó esta semana AA-Briefcase, un benchmark que apunta a medir trabajo de conocimiento agentico de varias semanas: proyectos largos, miles de inputs fragmentados, corpus de Slack, email y documentos, y entregables tipo modelos financieros y board decks. Los resultados:
- Claude Fable 5: 1587 Elo, USD 31 por tarea
- Opus 4.8: 1356 Elo, USD 10,40 por tarea
- GPT-5.5 xhigh: USD 3,68 por tarea
- GLM-5.2: 1266 Elo, USD 2,40 por tarea
GLM-5.2 aparece como el modelo abierto más fuerte del cuadro, con un costo cerca de 13 veces menor que Fable 5 y aproximadamente la mitad que GPT-5.5 xhigh. La advertencia metodológica del propio benchmark también vale: el modelo top satisfizo todos los criterios del rubric en apenas 3% de las tareas. El trabajo de conocimiento de horizonte largo, en otras palabras, sigue siendo duro para todo el mercado.
¿Cuándo vendrá un Fable-class abierto?
La proyección que más mueve la aguja la hizo Z.ai, con un calendario explícito apuntando a diciembre de 2026 para tener un modelo abierto a nivel Fable. La empresa estuvo notablemente ausente de la lista de laboratorios chinos acusados por Anthropic en su reporte de febrero sobre destilación a escala industrial, lo que refuerza la lectura de que llegan con entrenamiento propio.
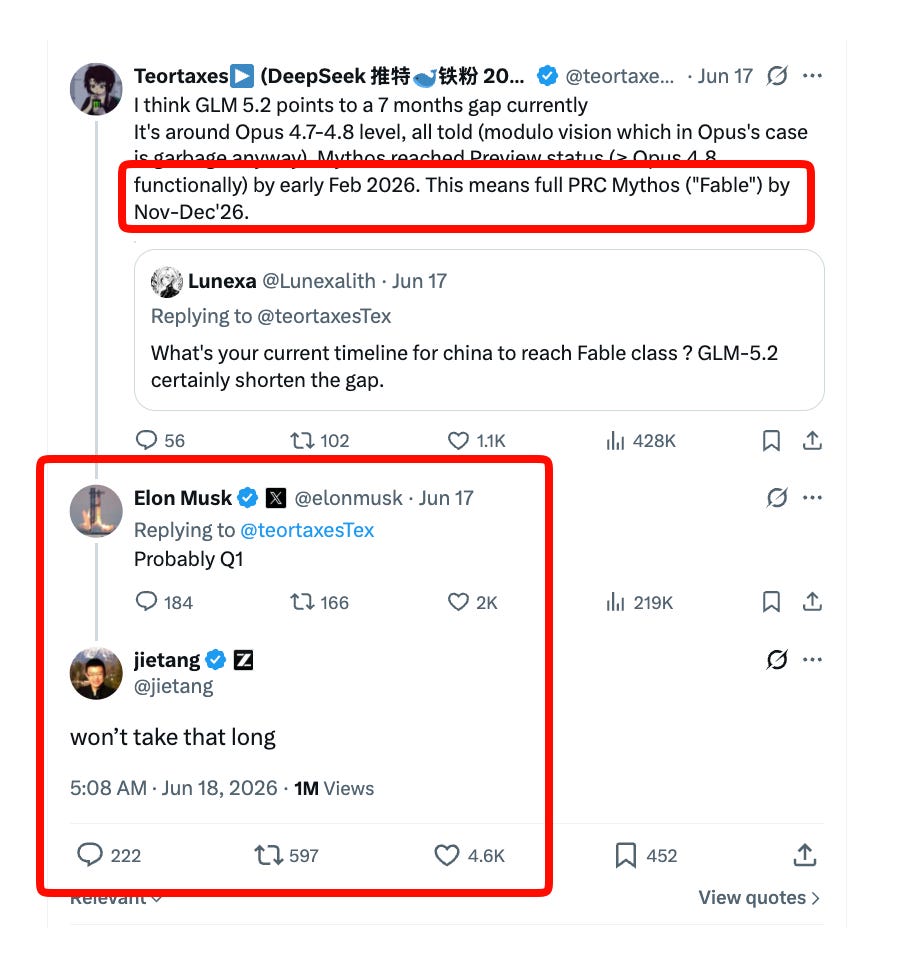
La pregunta espejo, según Latent Space, es si alguno de los cuatro laboratorios top va a poder liberar otro modelo Fable-class en los próximos seis meses, o si la prohibición en curso sobre Mythos congeló la cadencia. La salida del Open Fable de Z.ai, si llega en plazo, sería el cierre del arco "modelos chinos abiertos al nivel frontera occidental" que GLM-5 abrió hace meses.
Otros lanzamientos abiertos relevantes
En la misma ventana, Poolside liberó Laguna M.1 bajo licencia Apache 2.0 con contexto de 256K. La descripción técnica del vLLM project lo define como un sparse MoE de 70 capas, 225B totales y 23B activos, 256 expertos y top-k=16, optimizado para tareas agenticas con razonamiento intercalado y uso de herramientas. Una build a 3-bit MLX corrió sobre un M3 Max de 128 GB de RAM a unos 26 tokens por segundo, con cerca de 100 GB de uso pico de memoria.
En el extremo opuesto, Cohere bajó la barrera para North Mini Code con cuantización a 4 bits, soporte Ollama y acceso gratuito vía OpenRouter. La movida confirma que las dos puntas del open-weight (modelos enormes y modelos chicos pero accesibles) están empujando en paralelo, no en zigzag.