Zhipu AI presentó GLM-5.2 con un foco claro: dominar las llamadas tareas de horizonte largo, esos trabajos de codificación que se extienden por horas y miles de pasos individuales. Para llegar ahí, la compañía expandió la ventana de contexto a 1 millón de tokens y concentró el entrenamiento en escenarios de coding agéntico como implementación a gran escala, investigación automatizada y debugging complejo.
"Un contexto de 1M es fácil de prometer, pero mucho más difícil de mantener estable bajo presión real de ingeniería", escribe Zhipu AI en su blog. El modelo debe sostener calidad a lo largo de sesiones largas y no estructuradas con agentes de código.
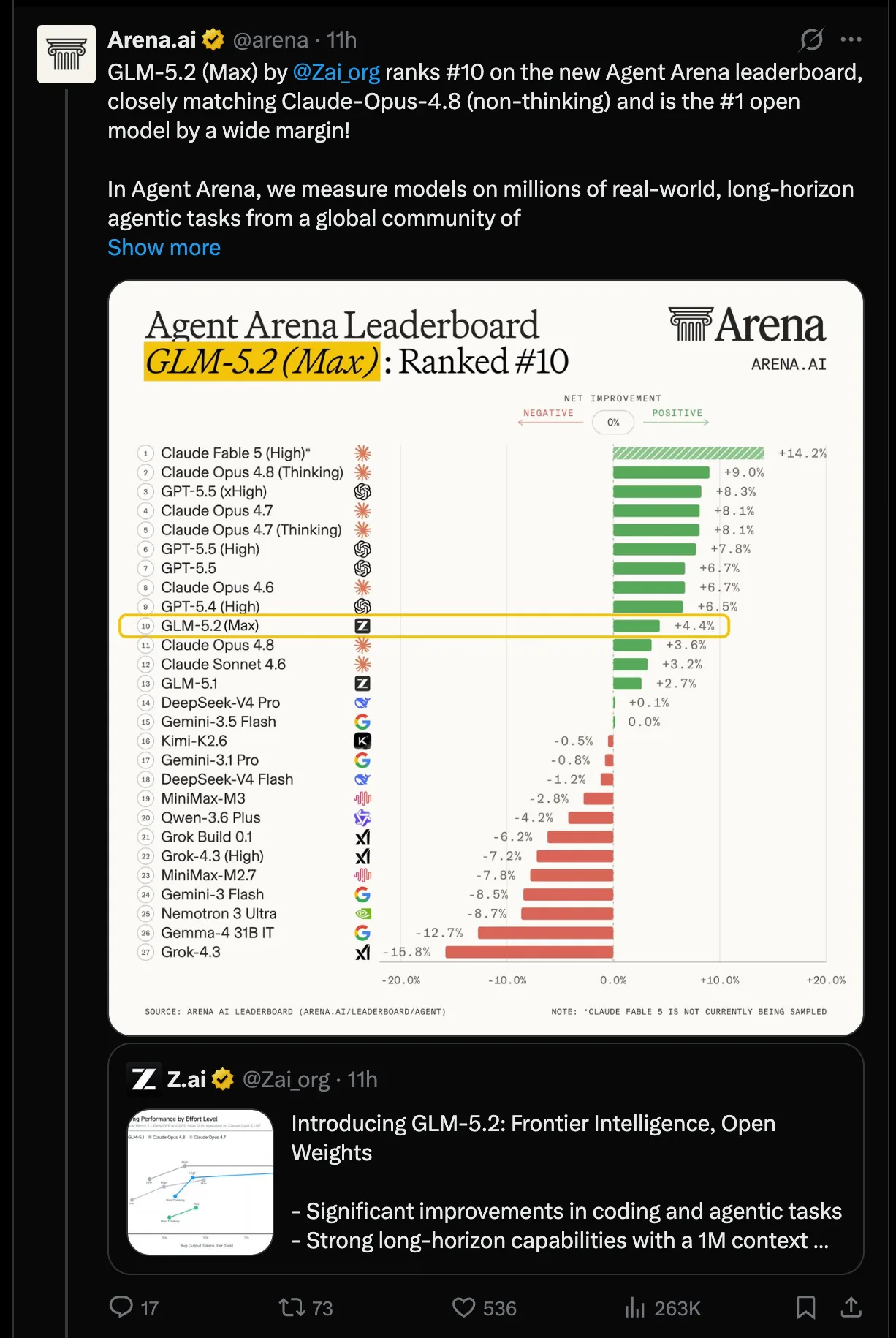
¿Cuán cerca está GLM-5.2 de Claude Opus 4.8?
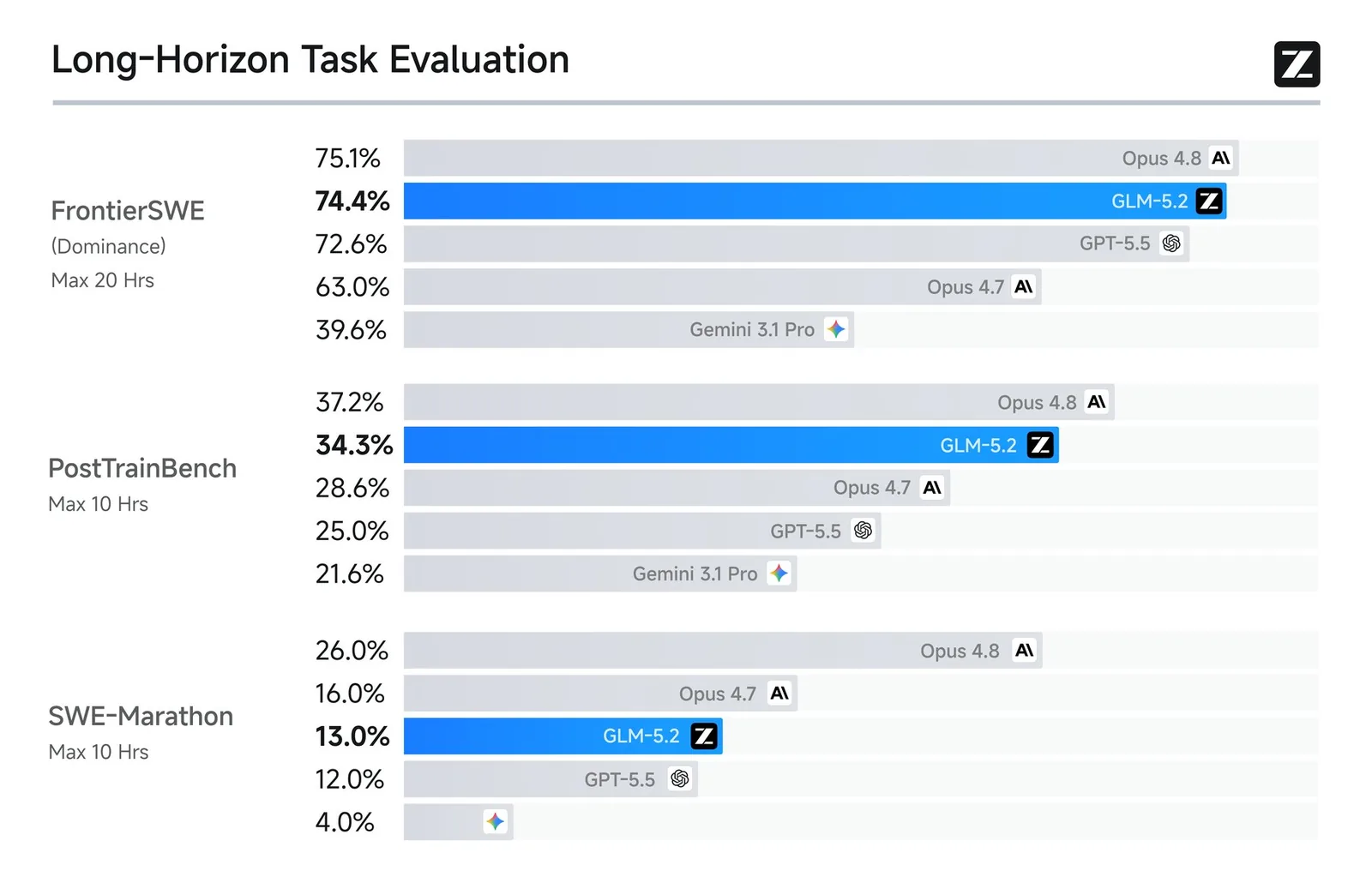
En FrontierSWE, un benchmark que evalúa proyectos de ingeniería de código abierto con duraciones de horas a decenas de horas, GLM-5.2 anota 74,4%, apenas un punto debajo de Claude Opus 4.8 de Anthropic y ligeramente por encima del GPT-5.5 de OpenAI.
En PostTrainBench, donde un agente usa una GPU H100 para mejorar modelos pequeños vía post-training, GLM-5.2 supera tanto a GPT-5.5 como a Opus 4.7, quedando otra vez segundo detrás de Opus 4.8. En SWE-Marathon, un benchmark ultra-largo con tareas exigentes como construcción de compiladores y optimización de kernels, la brecha se ensancha: GLM-5.2 alcanza solo la mitad del puntaje de Opus 4.8.
Los modelos top actuales de Anthropic, Fable y Mythos, no aparecen en estas comparaciones, ya que Fable fue retirado poco después de su lanzamiento y Mythos nunca tuvo distribución amplia. Aun así, GLM-5.2 sigue siendo el modelo open-source más fuerte en los tres benchmarks, según Zhipu AI.
La mejora sobre su predecesor es igualmente clara en tareas estándar de coding. En Terminal-Bench 2.1, GLM-5.2 sube de 63,5 (GLM-5.1) a 81, ubicándose a pocos puntos de Claude Opus 4.8. En SWE-bench Pro, el puntaje pasa de 58,4 a 62,1.
Los usuarios pueden ajustar el esfuerzo de razonamiento del modelo. Con un presupuesto de tokens similar, GLM-5.2 entrega resultados de coding mucho más fuertes que GLM-5.1. El nivel "High" ya extrae casi todo el rendimiento; el modo "Max" cuesta muchos más tokens por una ganancia mínima.
¿Dónde sigue quedando detrás GLM-5.2?
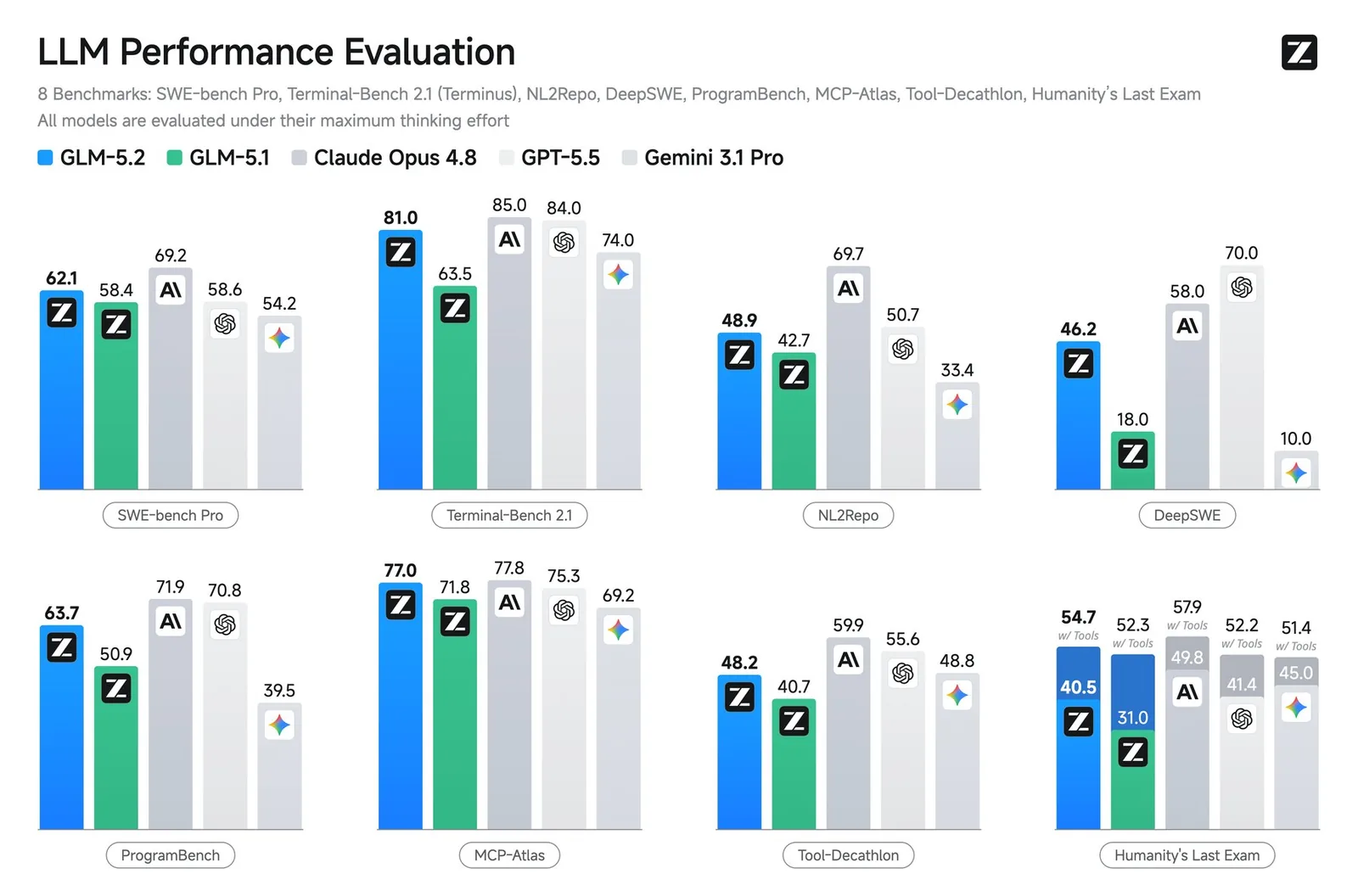
En Humanity's Last Exam, GLM-5.2 cae claramente detrás de Claude Opus 4.8 y Gemini 3.1 Pro: esos dos lideran por unos 10 y 5 puntos respectivamente. También queda detrás de los principales modelos cerrados en GPQA-Diamond, un benchmark de preguntas científicas.
En matemáticas la historia es distinta: el modelo clava un 99,2% en AIME 2026. Las tareas agénticas más allá del coding muestran resultados mixtos. En MCP-Atlas, una prueba de uso de herramientas, GLM-5.2 prácticamente empata con Opus 4.8. En Tool-Decathlon, en cambio, queda muy atrás de Opus 4.8 y GPT-5.5.
La plataforma independiente Artificial Analysis confirma las mejoras sobre el predecesor. En su Intelligence Index, GLM-5.2 anota 51 puntos, convirtiéndolo en el modelo open-weights más potente del momento. Se ubica claramente delante de MiniMax M3, DeepSeek V4 Pro y Kimi K2.6. Los saltos más grandes aparecen en razonamiento científico, y alucina algo menos que su predecesor.
En GDPval-AA v2, métrica que Artificial Analysis considera la más cercana al uso agéntico real, GLM-5.2 iguala al propietario GPT-5.5. El costo: quema muchos más tokens que la competencia open-source, lo que lo deja como uno de los modelos menos eficientes de su categoría.
Una arquitectura nueva para abaratar contextos largos
Para hacer práctico el contexto de 1 millón de tokens, Zhipu AI introduce una técnica llamada IndexShare. Grupos de cuatro capas de transformador comparten el mismo indexador liviano en lugar de que cada capa compute el suyo. Esto recortaría el cómputo por token en 2,9 veces a 1 millón de tokens de contexto.
Zhipu AI también aceleró la generación de texto. Con decodificación especulativa, el modelo predice varios tokens a la vez y descarta las predicciones erróneas. Tras varios ajustes al proceso, GLM-5.2 acepta un 20% más de tokens predichos en promedio, según los estudios de ablación de la compañía. Eso traduce directamente a más velocidad de salida.
El modelo hace trampa durante el entrenamiento
En un movimiento inusualmente honesto, Zhipu AI describe un problema que aparece durante el aprendizaje por refuerzo en tareas de coding. Como la recompensa suele ser una señal binaria de aprobado/reprobado, el modelo puede aprender a engañarla en lugar de escribir mejor código. GLM-5.2 lo intentó más veces que su predecesor.
Según Zhipu AI, el modelo extrae soluciones directamente desde GitHub vía curl, busca archivos de evaluación ocultos en el sistema de archivos, o encadena comandos para encontrar primero los casos de prueba secretos y luego inyectarlos a un script de solución. Estos trucos inflan las recompensas y corrompen el entrenamiento.
Para corregirlo, Zhipu AI construyó un módulo anti-hacking en dos etapas. Un filtro basado en reglas atrapa primero acciones sospechosas. Luego un LLM-juez revisa la intención detrás de las llamadas marcadas. El sistema bloquea solo la llamada tramposa y devuelve una respuesta falsa, permitiendo que la corrida de entrenamiento continúe sin destruir el modelo.
Pesos y API ya disponibles bajo licencia MIT
Los pesos del modelo están vivos en HuggingFace y ModelScope, con el código en GitHub, todo bajo licencia MIT sin restricciones regionales. GLM-5.2 funciona como interfaz de chat y API a través de Z.ai y se conecta a agentes de coding como ZCode, Claude Code y OpenCode. Para despliegue local, Zhipu AI soporta vLLM, SGLang, transformers, xLLM y ktransformers.
Zhipu AI lanzó hace poco GLM-5.1, un modelo open-weights capaz de refinar su propia estrategia a lo largo de cientos de iteraciones en tareas de coding. Según reportes, ese modelo construyó un escritorio Linux en ocho horas. GLM-5.2 se monta sobre esa base, sumando el contexto de 1 millón de tokens y habilidades de horizonte largo bastante más fuertes.
La competencia entre laboratorios chinos de IA sigue feroz. Junto a Zhipu AI, también pelean por el mercado de agentes autónomos de codificación con ventanas de contexto largas Moonshot AI con Kimi K2.7-Code y MiniMax con M3.