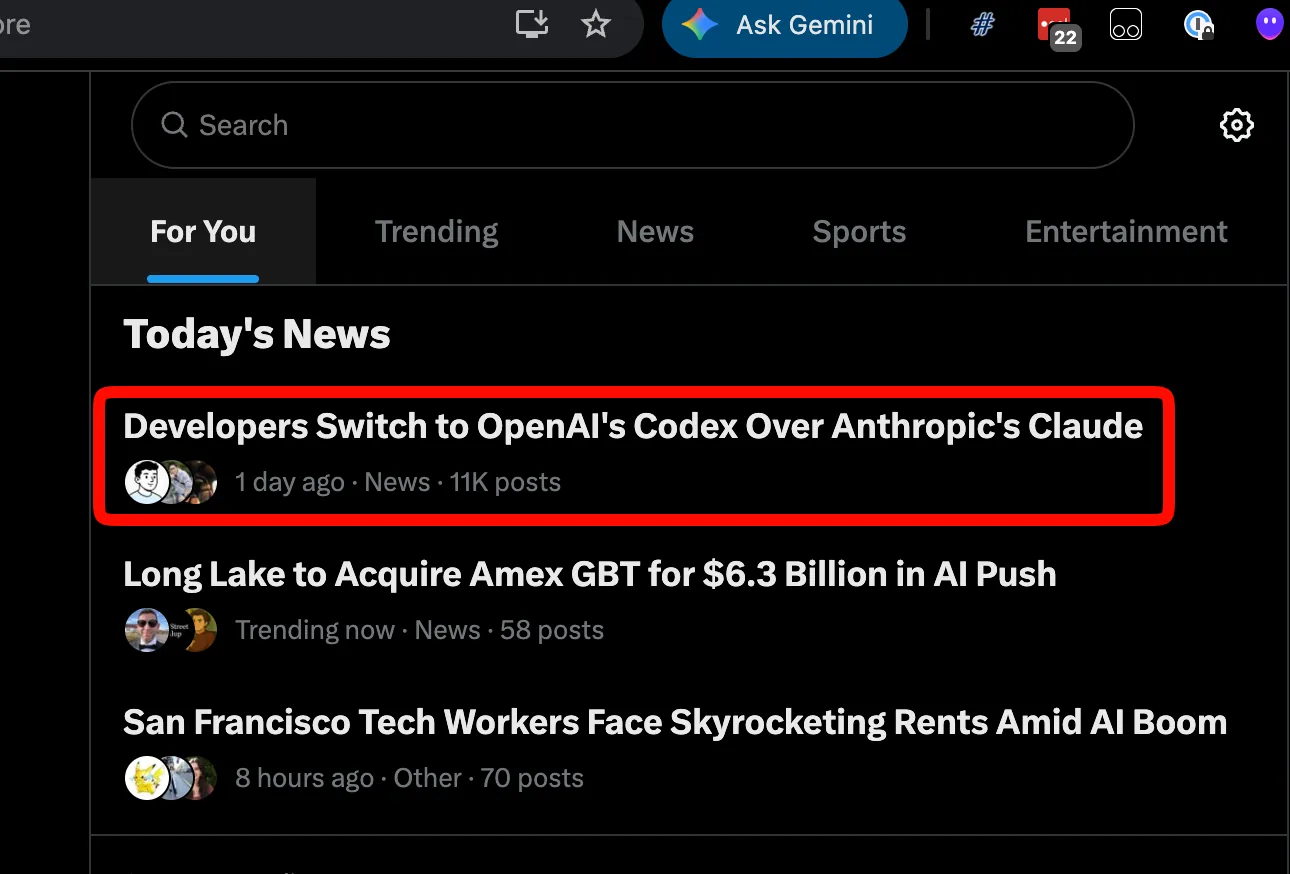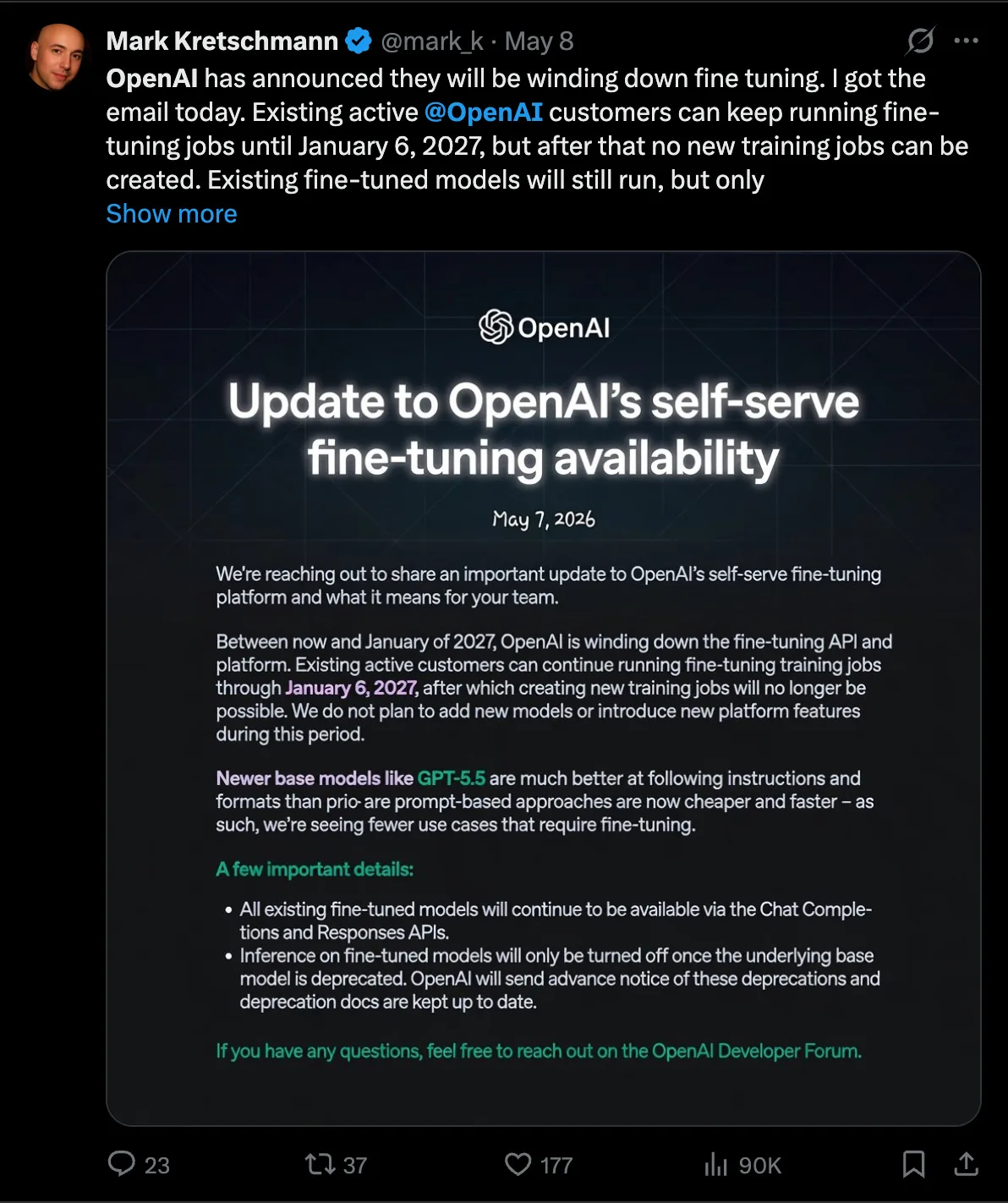
La causa inmediata del op-ed de Latent Space de esta semana es concreta: OpenAI deprecó sus APIs de finetuning. Durante años, esa herramienta era la marca distintiva del laboratorio frente al resto de los grandes, y montones de charlas, contenido y AI engineers la promocionaban como la manera de "conseguir performance de o1 a precio de 4o" y la presentaban como pieza central del toolkit.
Ahora el agua bajó. Anthropic probablemente cerrará una ronda a valuación mayor que OpenAI por primera vez y el finetuning se suma a la lista de víctimas del 2026 Side Quest massacre, después de Sora. Si se asume un cuello de botella severo en GPUs, la decisión tiene sentido. Pero incluso sin la presión de cómputo, el 80% del trabajo en AI engineering ya iba en esa dirección: Jeremy Howard lo venía diciendo en el pod desde 2023.
¿Significa que el fine-tuning desaparece?

No. El "fin" de algo para la mayoría no equivale al fin del concepto. De hecho, el primer escalón (los Cursor y Cognition del mundo, esta última con una ronda de USD 25.000 millones ya en discusión pública) aumentó su uso de RLFT y fine-tuning sobre modelos abiertos, no lo redujo.
El fine-tuning sobre modelos abiertos también es central en la tesis del ASIC personalizado, donde compañías como Taalas plantean inferencia más barata cuando se entrena un modelo específico para correr en silicio propio. Y si las soluciones de inferencia con desagregación P/D siguen escalando como sugieren los benchmarks de NVIDIA GB200, quizá el camino dominante sea simplemente prompts muy largos, como la Constitution de Claude.
¿Por qué OpenAI lo apaga ahora?
Tres hipótesis están sobre la mesa entre operadores de la industria:
- Cómputo escaso. Cada GPU que OpenAI dedica a un job de fine-tuning de un cliente es una GPU que no está sirviendo tráfico de GPT-5.5. Con margen ya ajustado y la cola por capacidad creciendo, deprecar fine-tuning libera capacidad para el negocio principal.
- Demanda real más baja de lo que parecía. Los testimonios públicos sugerían que mucho cliente "decía" hacer fine-tuning pero en realidad usaba RAG y few-shot. La métrica de uso interna probablemente confirma eso.
- Quita una palanca a la competencia abierta. Si los clientes serios necesitan fine-tuning, ahora tienen que pasarse a Llama, Qwen u otro modelo open, montar su propio stack y pagar la inferencia aparte. OpenAI se queda con el caso de uso "prompt + tools", donde tiene ventaja distributiva.
¿Qué hace un AI engineer la semana que viene?
La respuesta práctica que circula en los foros de la comunidad es triple:
1. Migrar a fine-tuning sobre modelos abiertos (Llama 3.x, Qwen, Mistral) cuando hay caso de negocio real, idealmente con un proveedor de inferencia managed como Together AI o Fireworks para no pelearse con el GPU ops. 2. Apoyarse en RAG + tools para el 70-80% de los casos donde el cliente creía que necesitaba fine-tuning. Los costos por long context siguen bajando: el GB200 de NVIDIA recortó la latencia de all-reduce de 586,1 µs en H200 a 313,3 µs, según mediciones publicadas por Perplexity sobre Qwen3 235B. 3. Reservar el fine-tuning intensivo para nichos verticales donde la diferencia es de verdad significativa, como medicina, finanzas regulada o agentes especializados con tool dispatch propio.
Lo que cambia para LatAm
Para equipos de IA en Chile, México y Brasil que vienen apoyándose en OpenAI por la simplicidad de su API, la noticia obliga a una decisión. Mantener todo el stack en OpenAI implica aceptar que el ajuste fino de comportamiento queda restringido al prompt. Pasarse a modelos abiertos con fine-tuning sobre proveedor managed implica más complejidad operativa, pero también más control y costos por token menores. La transición no es urgente, pero la dirección del mercado quedó fijada: el manual del AI engineer 2026 pesa cada vez menos en finetuning de modelos cerrados y cada vez más en evals, prompts largos y datos.