![[AINews] Todo es CLI](https://substackcdn.com/image/fetch/$s_!j5_Y!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fa29a5ad3-a76b-4aa4-b5eb-58bb7e229370_665x500.jpeg)
un día tranquilo nos permite reflexionar sobre la creciente tendencia de las CLI para ~todo~ agentes
Por sí solo, el lanzamiento de Projects.dev, una forma para que los agentes proporcionen servicios instantáneamente, no es digno de un título inmediato, excepto por 2 cosas: 1) proviene de STRIPE, 2) es una CLI. Ejecute proyectos de stripe, agregue posthog/analytics y creará una cuenta de PostHog, obtendrá una clave API y configurará la facturación.
Si esto te suena extraño, es porque Stripe realmente no tiene nada que ver con la configuración o el proceso de registro de PostHog. Estos socios de lanzamiento tampoco:

Stripe simplemente hace esto porque puede, y Patrick cita MenuGen de Andrej como inspiración directa de lo difícil que es para los agentes configurar servicios backend hoy en día. Seguramente verá el resto de los gráficos del panorama de proveedores de infraestructura nativos de agentes que presionan a Stripe para el sector inmobiliario:

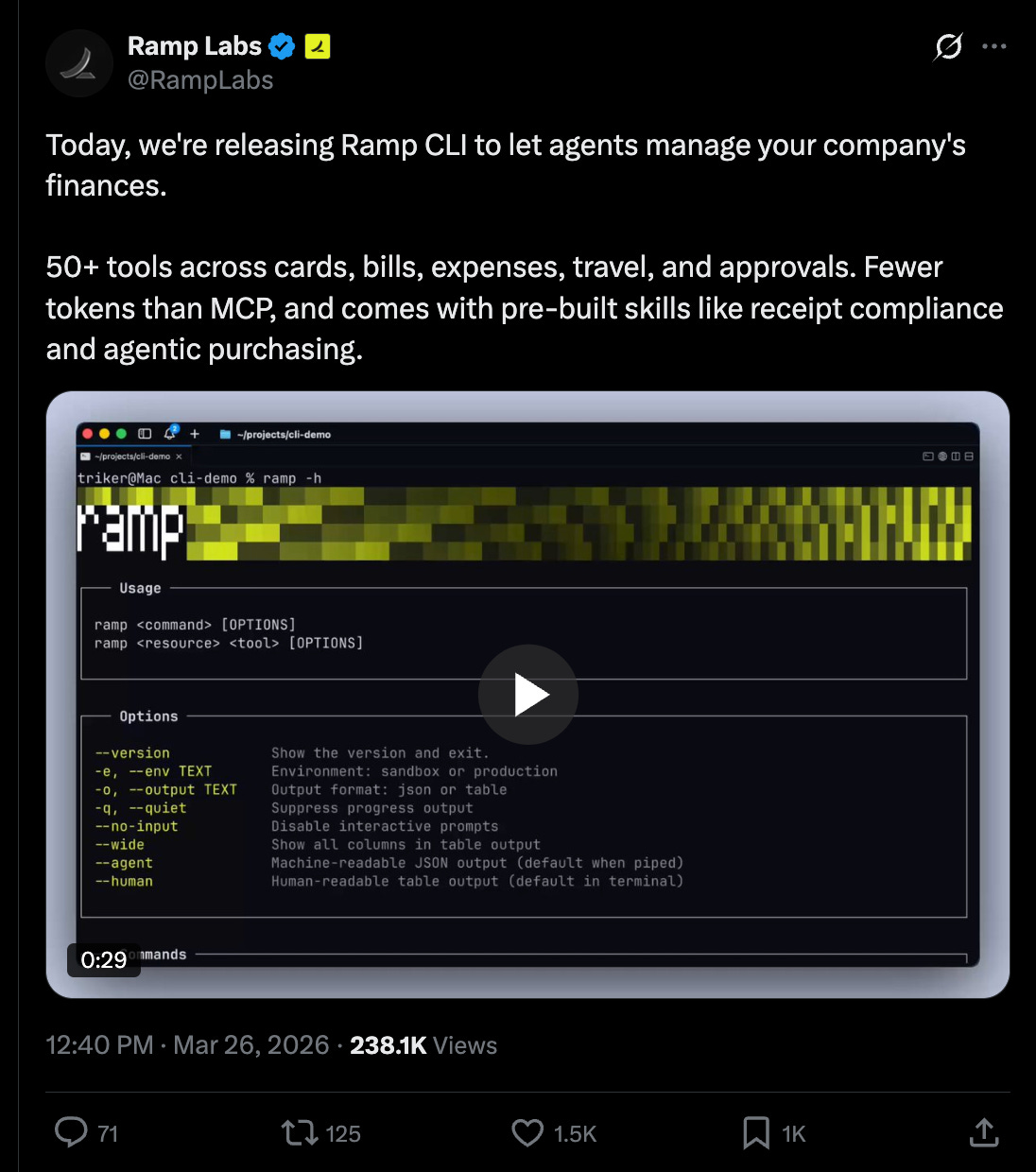
Pero no nos detengamos allí: desplácese un poco más hacia abajo en la línea de tiempo y aquí está la CLI de Ramp que también sabe lanza hoy, con algunos casos de uso útiles:
¡Ah, y mira hacia aquí! Es la CLI de Sendblue (iMessage) que siempre quisiste, ¡y también sabe lanza hoy! ¡Poniéndonos al día con Kapso CLI (WhatsApp) a partir del lunes! ¿Y te perdiste la CLI de ElevenLabs de ayer? Está bien, porque también puedes probar Visa CLI, Resend CLI o Discord CLI de steipete, la gran mamá, ¡la CLI oficial de Google Workspace!
Mucha, mucha gente ha escrito sobre por qué los CLI pueden ser más útiles que los MCP, lo cual no es necesariamente una comparación justa ni falsa, pero en este punto la tendencia es innegable y vale la pena informarla. Le damos crédito al modo de código de Cloudflare de septiembre pasado por iniciar la tendencia de "usar más computadoras para envolver MCP" y ahora, por supuesto, las CLI en sí mismas realmente no exponen ni sabe preocupan por sus protocolos de comunicación subyacentes.
Noticias de IA del 23/03/2026 al 24/03/2026. Revisamos 12 subreddits, 544 Twitters y no hay más Discords. El sitio web de AINews le permite buscar todos los números anteriores. Como recordatorio, AINews es ahora una sección de Latent Space. ¡Puedes optar por recibir o no frecuencias de correo electrónico!
Lanzamientos de modelos y productos: Gemini 3.1 Flash Live, Mistral Voxtral TTS, Cohere Transcribe y OpenAI GPT-5.4 mini/nano
- El impulso en tiempo real de Google con Gemini 3.1 Flash Live: Google lanzó Gemini 3.1 Flash Live como su nuevo modelo en tiempo real para agentes de voz y visión, enfatizando una latencia más baja, llamadas de funciones mejoradas, mayor solidez en entornos ruidosos y una memoria de conversación 2 veces más larga en Gemini Live. El lanzamiento abarca Gemini Live, Search Live, vista previa de AI Studio y superficies CX empresariales, y Google cita 70 idiomas, contexto de 128k y marcas de agua del audio generado a través de SynthID en algunos resúmenes para desarrolladores (Logan Kilpatrick, Google DeepMind, Sundar Pichai, Google). La evaluación comparativa de terceros de Artificial Analysis destaca la nueva compensación del "nivel de pensamiento": 95,9 % de Big Bench Audio con razonamiento alto con TTFA de 2,98 s, frente a 70,5 % en mínimo con TTFA de 0,96 s.
- La pila de voz sabe llena rápidamente: Mistral AI lanzó Voxtral TTS, un modelo TTS de peso abierto dirigido a agentes de voz de producción, con soporte para 9 idiomas, baja latencia y sólidas métricas de preferencia humana; varios resúmenes citan una huella de modelo de clase 3B/4B, ~90 ms de tiempo hasta el primer audio y comparaciones favorables con ElevenLabs en pruebas de preferencia (Mistral AI, Guillaume Lample, vLLM, kimmonismus). Cohere lanzó Cohere Transcribe, su primer modelo de audio, bajo Apache 2.0, ocupando el primer lugar en inglés en la clasificación de Hugging Face Open ASR con 5.42 WER y soporte para 14 idiomas (Cohere, Aidan Gomez, Jay Alammar). En particular, Cohere también contribuyó con optimizaciones de servicio de codificador-decodificador para vLLM (procesamiento por lotes de codificador de longitud variable y atención de decodificador empaquetada), lo que supuestamente produjo ganancias de rendimiento de hasta 2 veces para cargas de trabajo de voz (vLLM).
- Las variantes más pequeñas de GPT-5.4 de OpenAI parecen competitivas en términos de costos, con salvedades: Artificial Analysis informó sobre GPT-5.4 mini y GPT-5.4 nano, ambos multimodales con contexto de 400k y los mismos modos de razonamiento que GPT-5.4. El más destacado es GPT-5.4 nano, que sabe comparó por delante de Claude Haiku 4.5 y Gemini 3.1 Flash-Lite Preview en varias tareas de tipo agente y terminal, sin dejar de ser más económico en términos de costo efectivo. La desventaja: ambas variantes sabe describieron como muy detalladas, con un uso elevado de tokens de salida y un rendimiento débil de AA-Omniscience impulsado por altas tasas de alucinaciones. Esto coincide con las quejas anecdóticas de los desarrolladores sobre la verbosidad del códice/GPT-5.4 en la práctica (giffmana).
- Otros lanzamientos destacados: Zai puso el GLM-5-Turbo a disposición de los usuarios del GLM Coding Plan; Reka puso Reka Edge y Flash 3 en OpenRouter; Google/Gemini también comenzó a implementar el historial de chat y la importación de preferencias desde otras aplicaciones de inteligencia artificial; y varias publicaciones informaron que OpenAI ha restado prioridad a proyectos paralelos, incluido Sora y un chatbot en “modo adulto”, en favor de esfuerzos de productividad centrales (Andrew Curran, kimmonismus).
Infraestructura de agentes, arneses y UX multiagente
- Cline Kanban cristaliza una nueva UX multiagente: el lanzamiento de herramientas más claro del día fue Cline Kanban, una aplicación web local gratuita y de código abierto para orquestar múltiples agentes de codificación CLI en paralelo a través de árboles de trabajo git aislados. Es compatible con Claude Code, Codex y Cline, permite a los usuarios encadenar dependencias de tareas, revisar diferencias y administrar ramas desde un tablero (Cline, Cline). La reacción de los constructores fue fuerte, y varios llamaron a esta la probable interfaz multiagente predeterminada porque aborda los dos cuellos de botella prácticos de los flujos de trabajo actuales de los agentes de codificación: la espera ligada a la inferencia y el paralelismo intenso en conflictos de fusión (Arafat, testingcatalog, sdrzn).
- “Ingeniería de arneses” sabe está convirtiendo en una categoría: un tema recurrente en los tweets fue que la calidad del modelo ya no es toda la historia; el aprovechamiento del agente (middleware, memoria, orquestación de tareas, interfaces de herramientas, políticas de seguridad y bucles de evaluación) es cada vez más el producto real. LangChain, hwchase17 y otros enfatizaron el middleware como la capa de personalización para el comportamiento de los agentes. Voooooogel hizo la afirmación más fuerte de que los usuarios casualmente dicen "LLM" cuando lo que en realidad están usando es un sistema de lenguaje agente integrado con formato, analizadores, uso de herramientas, generación estructurada y memoria alrededor del modelo base.
- Hermes vs. OpenClaw: la memoria y la autonomía de larga duración son importantes: un gran grupo de publicaciones elogiaron el Hermes Agent de Nous Research como más utilizable que OpenClaw/pilas derivadas de OpenClaw para flujos de trabajo de agentes multiplataforma de larga duración. Los ejemplos incluyeron memoria persistente en Slack y Telegram, memoria compartida entre agentes, menores gastos generales de mantenimiento e informes de usuario de agentes funcionando sin supervisión durante horas en configuraciones locales o en la nube (IcarusHermes, jayweeldreyer, Niels Rogge). Teknium también adelantó una controvertida habilidad GODMODE para el jailbreak persistente, subrayando que la capacidad y la seguridad ahora sabe están produciendo en la capa del arnés, no solo en el modelo base.
- Expansión de herramientas en torno a los agentes: el equipo Codex de OpenAI solicitó solicitudes para integraciones ampliadas de kits de herramientas (reach_vb), mientras que Google publicó cómo desarrolló una habilidad de API Gemini para enseñar a los modelos sobre API y SDK más nuevos, mejorando Gemini 3.1 Pro a una tasa de aprobación del 95% en 117 pruebas de evaluación (Phil Schmid). OpenEnv sabe introdujo como un estándar abierto para entornos RL agentes con API asíncronas, transporte websocket, descubrimiento de herramientas nativas de MCP y empaquetado de implementación en cualquier lugar.
Sistemas de investigación e infraestructura de capacitación: científico de inteligencia artificial, agente ProRL y RL en tiempo real
- El científico de IA de Sakana AI obtiene un hito en Nature y una afirmación de ley de escala: la actualización más sustancial del sistema de investigación provino de Sakana AI, que destacó un artículo de Nature sobre la automatización de extremo a extremo de la investigación de IA y un resultado empírico notable: utilizando un revisor automatizado para calificar los artículos generados, observaron una ley de escala para la ciencia de IA, donde modelos de base más sólidos producen artículos científicos más sólidos, y argumentaron que esto debería mejorar con mejores modelos base y más computación de tiempo de inferencia ( Sakana AI, seguimiento de papel/código). Chris Lu agregó que AI Scientist V1 es anterior a los modelos de razonamiento de estilo de vista previa de o1, lo que implica un margen de maniobra sustancial respecto de los modelos más potentes de la actualidad (Chris Lu).
- Los cuellos de botella de la infraestructura, no los cuellos de botella del modelo, pueden estar limitando la RL del agente: uno de los hilos más importantes de los sistemas argumentó que los marcos de RL de la agencia sabe han diseñado incorrectamente al combinar la implementación y la optimización en el mismo proceso. La publicación que resume el agente ProRL de NVIDIA afirma que la implementación de desacoplamiento total en un servicio independiente casi duplicó Qwen 8B en SWE-Bench Verified del 9,6% al 18,0%, con ganancias similares para las variantes 4B y 14B, junto con una utilización de GPU mucho mayor (rryssf_). Si es exacto, esto es un fuerte recordatorio de que los puntos de referencia de capacitación de agentes pueden ser infralimitados, no puramente limitados por capacidad.
- La “RL en tiempo real” de Cursor es un patrón de entrenamiento de producción notable: Cursor dijo que puede enviar puntos de control mejorados de Composer 2 cada cinco horas, presentándolo como un ciclo de retroalimentación de RL productizado en lugar de una cadencia estática de lanzamiento de modelos. Varios ingenieros leyeron esto como una señal temprana de aprendizaje continuo en producción, especialmente para aplicaciones integradas verticalmente con datos de interacción de alta frecuencia (eliebakouch, code_star).
Arquitectura, recuperación y eficiencia de inferencia
- La profundidad del transformador sabe está volviendo “consultable”: Kimi/Moonshot describió los Residuales de Atención (AttnRes) como algo que convierte la profundidad en un problema de atención, permitiendo que las capas sabe recuperen selectivamente de las salidas de las capas anteriores en lugar de acumular residuales pasivamente (Kimi). Un fuerte explicador secundario de The Turing Post enmarcó esto como una tendencia más amplia: los transformadores profundos pasan de la adición residual fija a la recuperación adaptativa en profundidad.
- El trabajo de compresión y eficiencia de la memoria sigue siendo fundamental: TurboQuant llamó la atención como una ruta práctica hacia una compresión similar a la de 3 bits con una pérdida de precisión cercana a cero, combinando PolarQuant y la corrección de errores de 1 bit (QJL) para acelerar la atención y la búsqueda de vectores, reducir la memoria caché de KV y evitar el reentrenamiento (The Turing Post). Por otra parte, una sutil pero impactante corrección de errores de producción aterrizó en el kernel Mamba-1 CUDA de vLLM después de que AI21 rastreara un desbordamiento silencioso de uint32_t que causó discrepancias en logprob en el entrenamiento de GRPO; la solución fue cambiar efectivamente uint32_t a size_t (vLLM, AI21).
- La recuperación es una tendencia multimodal y especializada: varias publicaciones señalaron un alejamiento de las recetas genéricas de RAG. Victoria Slocum destacó IRPAPERS, mostrando que la recuperación de texto/OCR y la recuperación de páginas de imágenes fallan en diferentes consultas, y que la fusión multimodal supera a ambas por sí solas en archivos PDF científicos. Chroma Context-1 de código abierto, un modelo centrado en la búsqueda entrenado con SFT+RL en más de 8000 tareas sintéticas, que afirma una búsqueda mejor, más rápida y más barata que los modelos fronterizos de propósito general; John Schulman destacó su plan de estudios, sus datos sintéticos verificados y su herramienta de poda de contexto como especialmente interesantes.
Tweets principales (por participación)
[...]