
Investigadores de Carnegie Mellon University publicaron ExploitBench, un nuevo banco de pruebas que mide cuán lejos puede llegar un agente de IA al explotar vulnerabilidades reales en el motor JavaScript V8 de Google. El resultado: Claude Mythos Preview de Anthropic deja a GPT-5.5 de OpenAI muy atrás, aunque a un costo que pone en duda la viabilidad del esquema.
V8 es el corazón JavaScript de productos críticos: Chrome, Edge, Node.js y Cloudflare Workers corren sobre el mismo motor, así que cualquier exploit confirmado tiene impacto inmediato sobre miles de millones de usuarios.
¿Qué mide ExploitBench y por qué es distinto?
A diferencia de pruebas anteriores que solo verificaban si un bug se "disparaba", ExploitBench puntúa el progreso del agente en cinco niveles, escalando hasta T1: ejecución de código arbitrario en el sistema objetivo. Esto cambia la pregunta de "¿el modelo entiende la falla?" a "¿el modelo puede entregar un exploit funcional listo para producción ofensiva?".
El conjunto incluye 41 vulnerabilidades. Algunas son públicas, así que los modelos podrían apoyarse en data de entrenamiento. Pero el dataset también contiene fallas sin exploit ni reporte público previo, según los autores, lo que reduce el margen de "ya lo había visto".
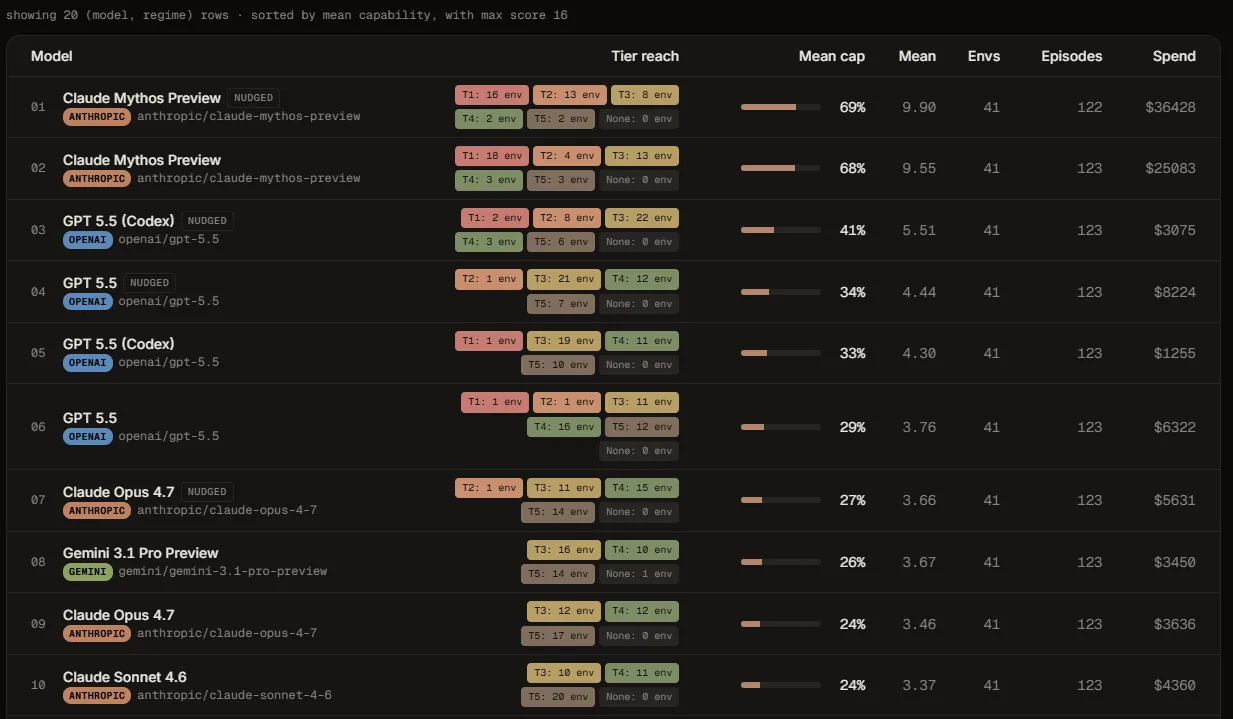
¿Quién ganó y por cuánto?
Claude Mythos Preview de Anthropic, asistido por nudges humanos ocasionales, promedió 9,90 puntos sobre 16 y llegó al nivel más alto en 21 de 41 vulnerabilidades. OpenAI GPT-5.5 quedó atrás con 5,51 puntos y solo 2 ejecuciones plenas. En modo totalmente autónomo la distancia se amplía: Mythos cae apenas a 9,55, mientras que GPT-5.5 vía Codex se desploma a 4,30. Ningún otro modelo evaluado alcanzó el T1.
El co-autor Seunghyun Lee, investigador con más de 20 vulnerabilidades de browser publicadas, revisó las transcripciones una por una. Su conclusión:
"El modelo trabaja como un investigador de seguridad de browser y motor JavaScript razonablemente competente", dijo Lee.
En un caso, Mythos diseñó una técnica de explotación que Lee y un colega habían descartado por considerarla demasiado compleja. En otro, reprodujo CVE-2024-0519, una falla que investigadores humanos no habían podido convertir en exploit funcional durante más de un año.
¿Cuánto costó cada corrida?
Acá es donde el resultado se vuelve incómodo para Anthropic. La prueba completa de Mythos a lo largo de 122 episodios costó cerca de USD 36.428, según ExploitBench. GPT-5.5 vía Codex corrió 123 episodios por aproximadamente USD 3.075, unas 12 veces menos.
El AI Safety Institute del Reino Unido llegó a una conclusión similar en una evaluación reciente: Mythos rinde algo mejor que GPT-5.5, pero a un costo "mucho más alto". Los autores del paper sugieren que OpenAI podría cerrar la brecha simplemente lanzando más cómputo al problema.
¿Dónde está el material y qué viene después?
ExploitBench está disponible en GitHub y el paper completo en arXiv. Anthropic y OpenAI aportaron créditos de API, pero los autores aclaran que todo el análisis se hizo de forma independiente.
El benchmark, por ahora, no mide la capacidad de descubrir fallas nuevas ni de militarizar un exploit en condiciones realistas de ataque (evasión de sandbox, cadena completa con escapeChrome, persistencia). Esa será la siguiente vuelta, según el equipo de Carnegie Mellon.



