Cada modelo de IA que marca un hito empieza igual: con una corrida de entrenamiento. La infraestructura que sostiene esos jobs define todo, desde la velocidad con que un equipo itera hasta la escala del modelo que puede construir y si la corrida termina con confiabilidad.
A medida que los modelos crecen en tamaño, complejidad e inteligencia, las exigencias sobre la infraestructura de entrenamiento también aumentan.
En MLPerf Training 6.0, la última edición de la serie de benchmarks rigurosos y revisados por pares para evaluar rendimiento de entrenamiento de IA, la plataforma NVIDIA Blackwell lideró en cada categoría, demostrando:
- Tiempo más rápido de entrenamiento en cada benchmark.
- Entrenamiento a la escala más grande con 8.192 GPU sobre sistemas NVIDIA Blackwell NVL72.
- La única plataforma con envíos en los siete benchmarks de la suite.
NVIDIA combina rendimiento, escala y confiabilidad en una sola plataforma diseñada bajo codiseño extremo para que los constructores de modelos lancen frontera más rápido, reduzcan costos de entrenamiento y empiecen a generar ingresos antes.
Rendimiento: tiempo más rápido en cada benchmark
MLPerf Training 6.0 sumó dos cargas nuevas de pretraining con mixture-of-experts (MoE) a la suite: DeepSeek-V3 671B y GPT-OSS-20B, reflejo de la centralidad creciente de las arquitecturas MoE. La plataforma NVIDIA fue la única enviada en cada benchmark y entregó el menor tiempo de entrenamiento en los siete.

Esta ronda NVIDIA presentó resultados sobre los rack-scale GB200 NVL72 y GB300 NVL72. Dentro de cada uno, los switches NVLink de quinta generación conectan las 72 GPU con alto ancho de banda, formando una pool unificada de cómputo y memoria que se comporta como una GPU gigante.
El entrenamiento de MoE a gran escala enfrenta el mismo desafío de comunicación all-to-all que la inferencia MoE: los tokens deben rutearse entre GPU hasta llegar al sub-experto correcto, y la ventaja de ancho de banda de NVLink es lo que hace ese tráfico rápido y eficiente.
NVIDIA también mostró métodos de entrenamiento en NVFP4 que mejoran rendimiento manteniendo exigencias estrictas de precisión en pretraining a gran y pequeña escala, además de cargas de fine-tuning. La firma siguió empujando innovación en baja precisión a lo largo de arquitecturas distintas, usando recientemente NVFP4 para pre-entrenar el masivo NVIDIA Nemotron 3 Ultra de 550.000 millones de parámetros.
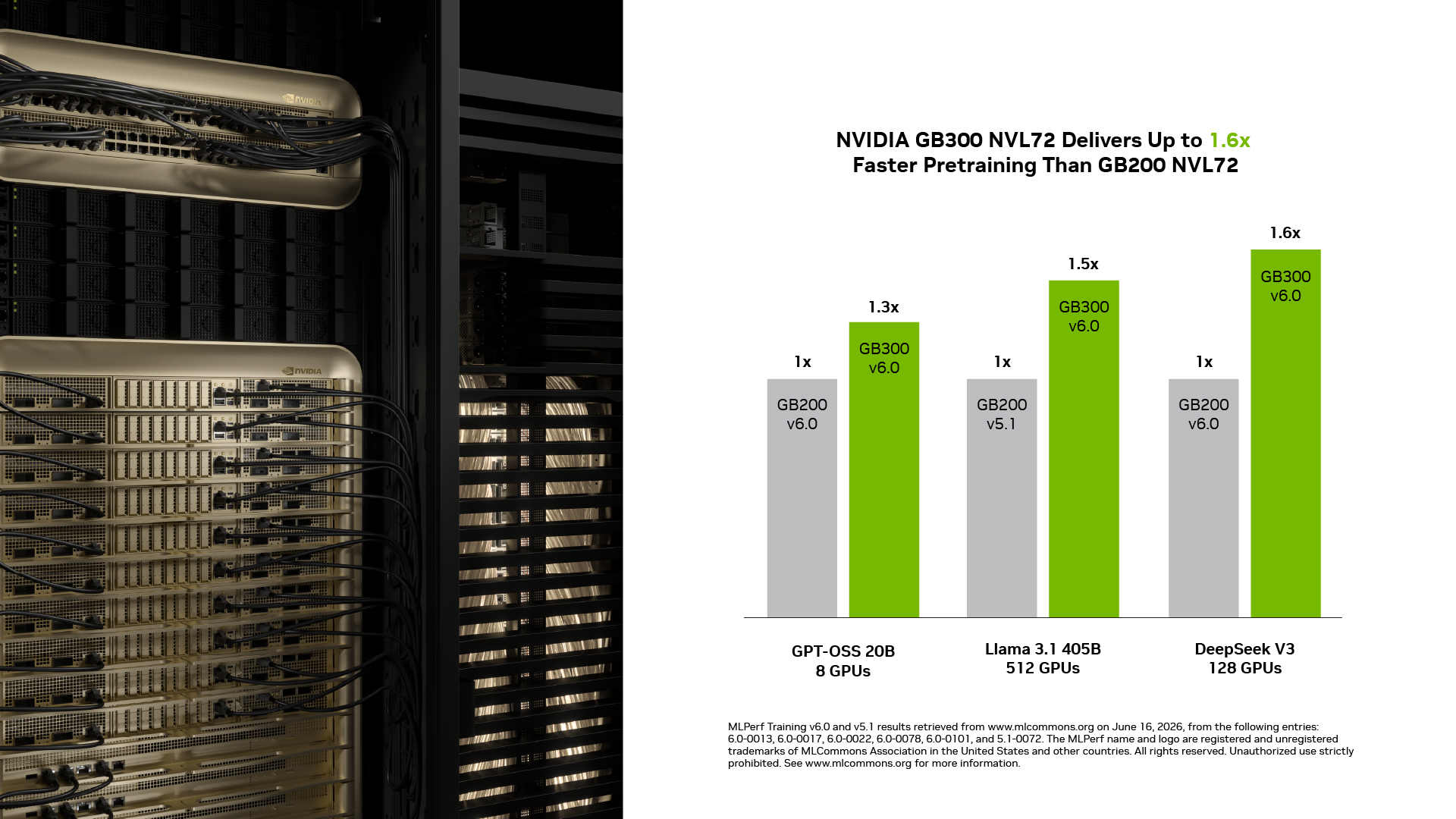
NVIDIA GB300 NVL72 entregó hasta 1,6× el rendimiento del GB200 NVL72: en esta ronda, GB300 NVL72 entrenó hasta 1,6× más rápido que GB200 NVL72 a la misma escala. Capacidades clave de Blackwell Ultra como la mayor densidad de cómputo con NVFP4, la capacidad de memoria ampliada y el techo de potencia más alto que permite a la GPU sostener el peak son los motores de esa mejora.
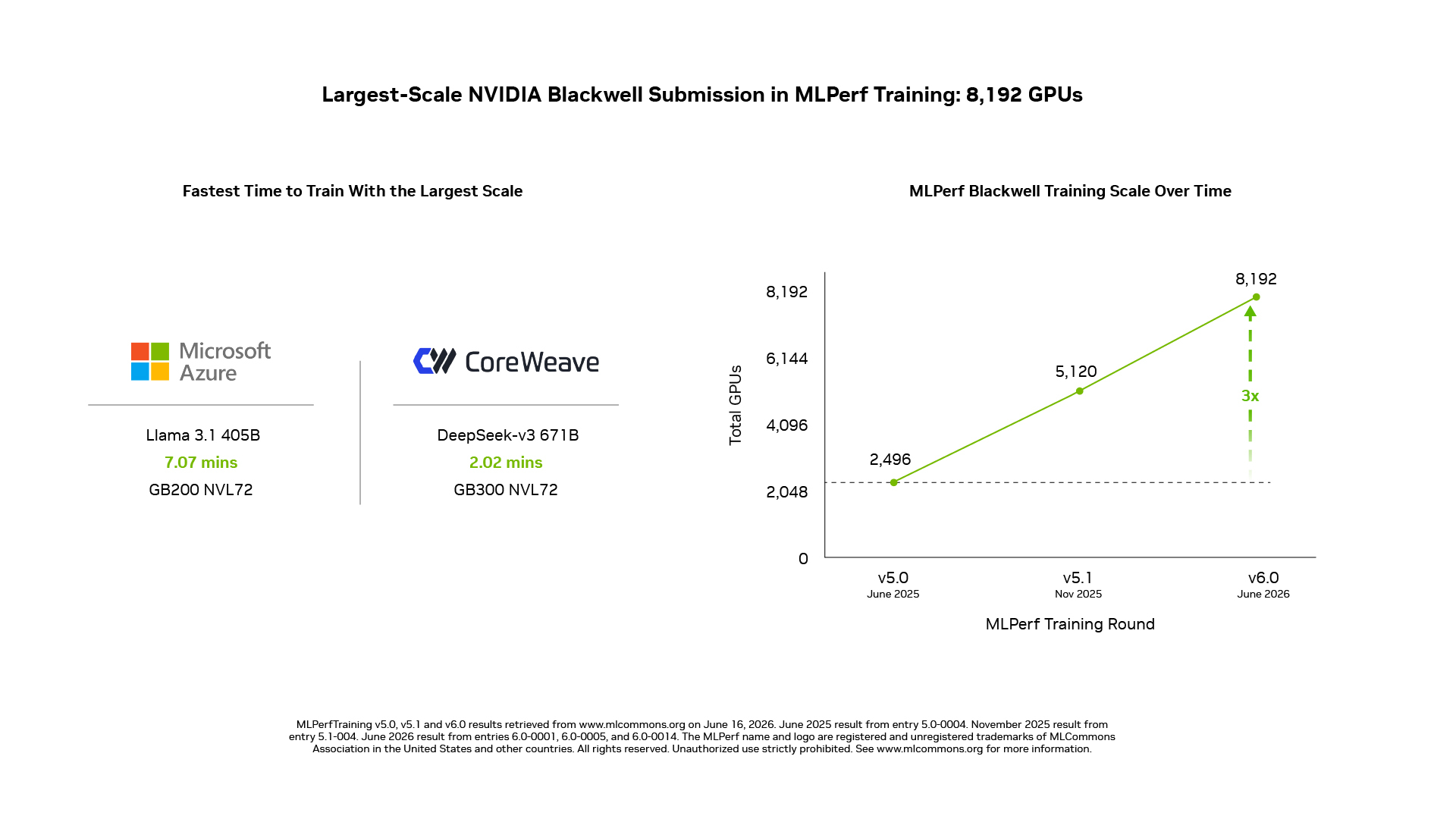
¿Cuán grande es el mayor cluster Blackwell de la ronda?
Para sostener entrenamiento distribuido a escala, NVIDIA ofrece dos plataformas complementarias de scale-out networking: NVIDIA Quantum InfiniBand y NVIDIA Spectrum-X Ethernet. Los data centers eligen entre una y otra según la infraestructura.
En DeepSeek-V3 671B, el MoE más grande de la suite, NVIDIA escaló el envío a 8.192 GPU con sistemas GB200 NVL72: el cluster Blackwell más grande presentado en la historia de MLPerf Training.
NVIDIA también envió resultados con 5.120 GPU sobre GB200 NVL72 en Llama 3.1 405B, uno de los LLMs densos más grandes de la suite.
Los resultados también muestran el codiseño profundo entre NVIDIA y sus socios en arquitectura, networking y software:
- Microsoft Azure escaló el entrenamiento de Llama 3.1 405B a 8.192 GPU con GB200 NVL72 y alcanzó el target de calidad de referencia en 7,07 minutos, la marca más rápida del benchmark.
- CoreWeave entregó el mejor tiempo en DeepSeek-V3 671B y llegó al target en 2,02 minutos sobre 8.192 GPU con sistemas GB300 NVL72 conectados con Spectrum-X Ethernet.
Confiabilidad a escala: ingeniería para producción
En entornos de entrenamiento productivos, una corrida puede extenderse semanas o meses sobre cientos de miles de GPU. A esa escala, el throughput efectivo depende del rendimiento del sistema y de la resiliencia que hace el resultado reproducible en el tiempo.
Los resultados de MLPerf Training v6.0 hablan del rendimiento. Para la resiliencia, la plataforma NVIDIA está pensada en dos ejes:
- Menos interrupciones: las GPU NVIDIA se diseñan para evitar fallas antes de que ocurran. Antes de llegar al data center, se las testea en más de 30 etapas de manufactura para detectar defectos. Una vez desplegadas, el motor de Reliability, Availability and Serviceability monitorea casi todo el chip, y las capacidades de auto-reparación ruteian alrededor de fallas detectadas sin interrumpir la carga. A nivel red, Spectrum-X Ethernet reasigna enlaces caídos en milisegundos.
- Recuperación más rápida cuando algo se cae: NVIDIA Resiliency Extension (NVRx) minimiza el tiempo perdido cuando ocurren fallas, con detección de fallas, recuperación y monitoreo de salud sobre el cluster. Detecta y maneja nodos bajo rendimiento antes de que arrastren al resto. Cuando un nodo se interrumpe, el sistema retoma desde un checkpoint reciente en vez de reiniciar el job completo.
Frontera de IA construida sobre NVIDIA
Los socios del ecosistema participaron extensamente: 19 organizaciones, entre ellas ASUSTeK, Microsoft Azure, Cisco, CoreWeave, Dell Technologies, Fujitsu, Giga Computing, Google Cloud, Hewlett Packard Enterprise, Inventec, Krai, Lambda, Nebius, Netweb Technologies India Ltd., Quanta Cloud Computing (QCT), ScitiX, Supermicro y TTA. Muchos corren los workloads de entrenamiento más exigentes sobre infraestructura NVIDIA.
CoreWeave, que aloja su infraestructura NVIDIA dentro de Dell PowerRack con servidores Dell PowerEdge, hospeda varios de esos workloads. Cohere logró entrenamiento 3× más rápido en GB200 NVL72 para su plataforma agentic North. Midjourney, que entrenó su modelo v8 de generación de imágenes sobre un cluster Blackwell, escala ahora una flota grande de GPU Blackwell Ultra en CoreWeave para entrenar próximos modelos de imagen y video.
En Google Cloud, Thinking Machines Lab vio velocidades 2× más rápidas de entrenamiento y serving sobre GB300 NVL72 frente a la generación previa, acelerando investigación de modelos frontera y flujos de reinforcement learning.
Nebius, corriendo Blackwell y Blackwell Ultra en su AI cloud, le permitió a Higgsfield reducir el tiempo de entrenamiento en 30%, sosteniendo una plataforma que ya sirve a 22 millones de usuarios y genera más de 6 millones de piezas de contenido IA por día.
Para una mirada técnica más profunda a los resultados de MLPerf Training 6.0 y las optimizaciones detrás, hay un post técnico en el blog de desarrolladores de NVIDIA.