NVIDIA publicó BioNeMo Recipes, un framework abierto en GitHub que demuestra cómo afinar modelos fundacionales biológicos de miles de millones de parámetros usando Low-Rank Adaptation (LoRA) sobre una única GPU de workstation. La técnica, desarrollada por el equipo de NVIDIA Computational Biology, reduce drásticamente la barrera de hardware para investigación genómica y proteómica fuera de los grandes centros de cómputo.
¿Qué resuelve BioNeMo Recipes?
Los modelos fundacionales biológicos están reescribiendo la biología computacional. Modelos preentrenados sobre corpus masivos de secuencias de proteínas o genoma —como ESM2 (un modelo de lenguaje para proteínas) y Evo 2 (un modelo de lenguaje para ADN)— capturan regularidades estadísticas que transfieren bien a tareas posteriores: predicción de estructura, efecto de variantes y anotación funcional.
El problema es que adaptar estos modelos a una tarea específica es no trivial. Con miles de millones de parámetros, el fine-tuning completo se vuelve impráctico, tanto en cómputo como en almacenamiento del estado del optimizador y los checkpoints.
LoRA aborda este desafío directamente. Al mantener congelado el backbone preentrenado y entrenar solo un pequeño conjunto de matrices adaptadoras de bajo rango, LoRA puede igualar la calidad del fine-tuning completo en muchas tareas mientras entrena ~1% de los parámetros, ajustando un modelo de mil millones más su adaptador en una sola GPU de workstation.
Caso 1: predicción de estructura secundaria de proteínas
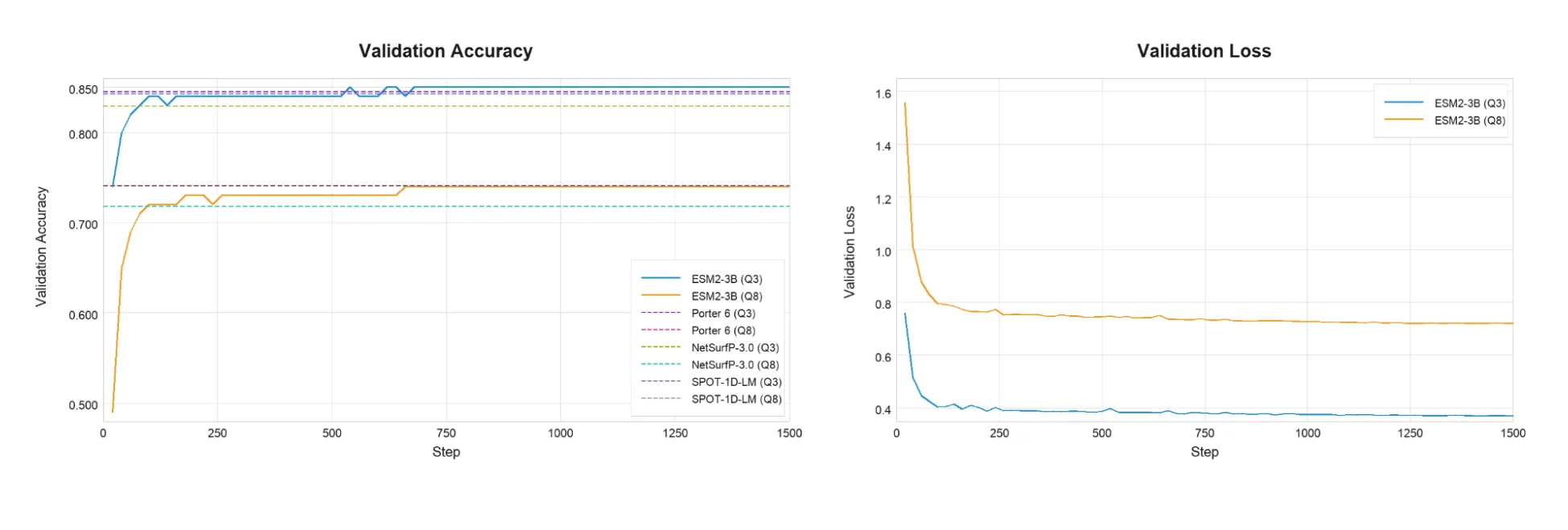
El primer caso de estudio usa ESM2-3B + LoRA para predicción de estructura secundaria de proteínas (PSSP), una tarea donde se asigna una etiqueta estructural a cada aminoácido en una secuencia. Las etiquetas de estructura secundaria describen conformaciones locales del esqueleto proteico: hélices y láminas, sin requerir predicción 3D completa.
Los resultados son concretos: ESM2-3B + LoRA alcanza precisiones Q3 de 84,80% y Q8 de 74,30%, equivalentes a los baselines líderes como Porter 6, con entrenamiento end-to-end en una sola NVIDIA RTX 6000 Blackwell Workstation Edition. El secreto del rendimiento está en dos optimizaciones: aceleración con Transformer Engine (TE) y empaquetado de secuencias en formato THD, que juntas entregan una mejora de throughput de 5,5× y eficiencia de memoria significativamente mejor.
Caso 2: clasificación de sitios de splicing en ADN
El segundo caso aplica Evo2-1B + LoRA a clasificación de sitios de splicing, una tarea fundamental para entender cómo el ADN se transcribe en proteínas funcionales. La configuración coloca adaptadores LoRA sobre las capas de atención, MLP y los mixers Hyena (Evo 2 usa la arquitectura striped Hyena, no transformers puros).
El salto de precisión es dramático: del 52,3% del baseline head-only al 96,6% con LoRA, entrenando solo 1,42% de los parámetros del modelo. Esto demuestra que el framework BioNeMo Recipes puede adaptar eficientemente modelos fundacionales grandes de proteínas y ADN a través de distintas modalidades sobre hardware de workstation.
¿Cómo funciona LoRA bajo el capó?
El fine-tuning completo es pesado porque requiere almacenar y actualizar todos los parámetros del modelo y sus estados del optimizador, que rápidamente se vuelven impráticos a medida que los modelos escalan.
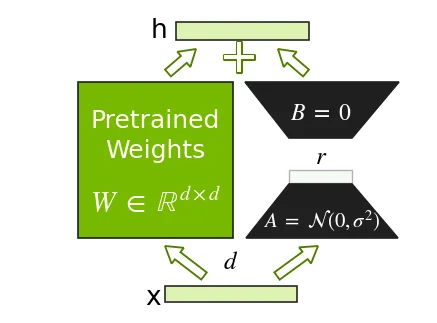
LoRA es un método práctico para afinar transformers preentrenados sin actualizar ni almacenar el estado del optimizador para todos los parámetros del modelo. La idea central es que, en lugar de actualizar la matriz de pesos densa W del modelo, LoRA agrega una nueva matriz entrenable de bajo rango (W = BA) en paralelo y mantiene W congelada. Esto reduce dramáticamente el número de parámetros entrenables y la huella de memoria del optimizador.
LoRA se parametriza por un pequeño conjunto de hiperparámetros que negocian capacidad, estabilidad y costo. El rango r controla el tamaño de las matrices de bajo rango agregadas y por tanto el número de parámetros entrenables. Los módulos objetivo especifican qué capas reciben adaptadores, con elecciones comunes como las proyecciones de atención y MLP. Para conjuntos de datos pequeños, el dropout de LoRA puede habilitarse como forma adicional de regularización.
¿Qué hardware se necesita realmente?
Una NVIDIA RTX 6000 Blackwell Workstation Edition parte alrededor de los 8.500 dólares según configuración (junio 2026), un orden de magnitud por debajo de los nodos H100 multi-GPU. Para un laboratorio universitario de bioinformática en Chile o Argentina, eso es la diferencia entre comprar el equipo con un Fondecyt y depender de centros como Powerhouse o el NLHPC. La RTX 6000 Blackwell entrega 96 GB de VRAM GDDR7, suficiente para mantener ESM2-3B y su adaptador LoRA en memoria sin offloading.
Todo el código fuente para personalizar o reproducir estos resultados está disponible en NVIDIA BioNeMo Recipes en GitHub. El proyecto se apoya en patrones familiares de PyTorch, Hugging Face y Megatron-Bridge, con componentes orientados al rendimiento como Transformer Engine integrados donde aportan valor, pero manteniendo los recipes legibles.
El paper original de LoRA está disponible en arXiv:2106.09685 para quienes quieran entender la teoría completa de la reparametrización.