NVIDIA CUDA 13.3 trae nuevas capacidades y optimizaciones de rendimiento para los desarrolladores del ecosistema CUDA. El lanzamiento de NVIDIA CUDA Tile programming en C++ habilita un desarrollo de kernels de alto nivel basado en tiles, que gestiona automáticamente los detalles de bajo nivel de la GPU para entregar rendimiento óptimo y portabilidad. Además, CUDA Tile programming ahora está soportado en GPUs con Compute Capability 9.0 (NVIDIA Hopper), sumándose al resto de arquitecturas GPU compatibles.
También se libera CUDA Python 1.0, consolidando el soporte y la estabilidad del ecosistema de software CUDA Python e introduciendo funcionalidades críticas como green contexts y checkpointing de procesos.
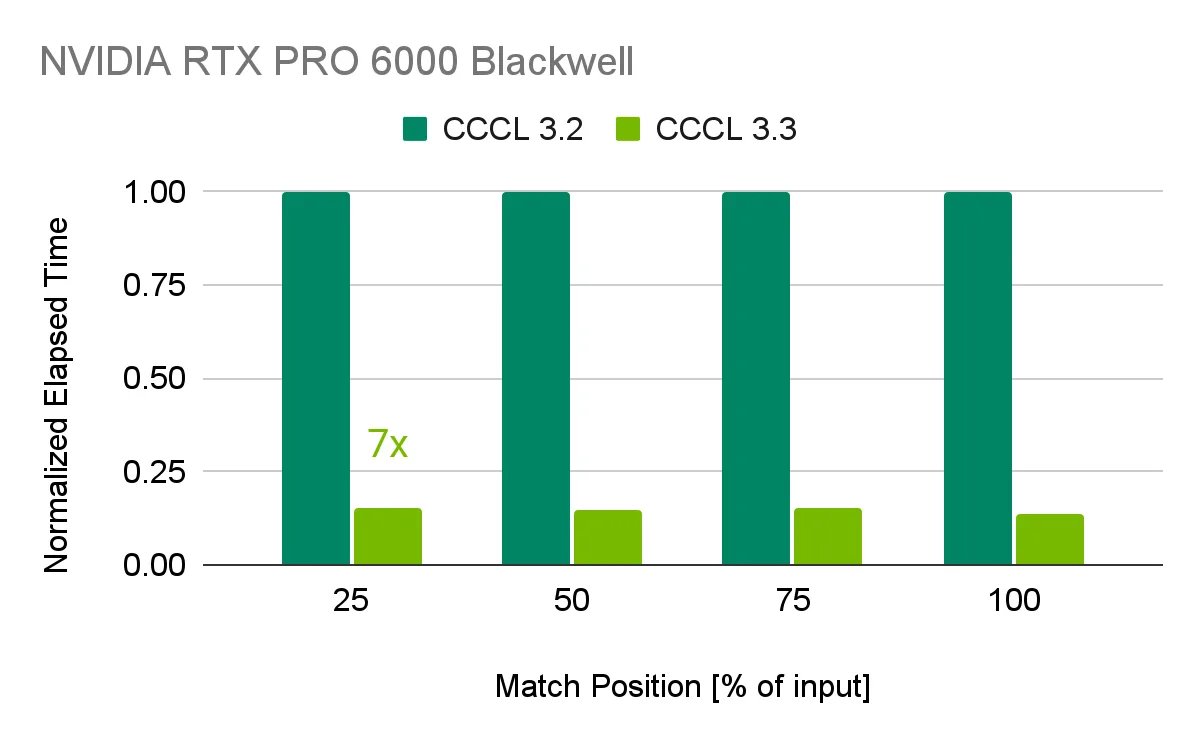
Para entusiastas del rendimiento, el recién lanzado framework de autoajuste de compilador CompileIQ entrega hasta un 15% de speedup sobre kernels críticos como GEMM y attention. Esta entrega también incluye soporte oficial de C++23 en NVCC, interoperabilidad extendida de tensores con DLPack/mdspan en CCCL 3.3, y numerosas actualizaciones a las librerías matemáticas (cuBLAS, cuSPARSE, cuSOLVER) y a las herramientas de profiling (Nsight Compute y Nsight Systems).
¿Qué cambia con CUDA Tile en C++?
Con el lanzamiento de CUDA 13.3, el soporte de CUDA Tile se extiende a C++, permitiendo que la enorme base de código y desarrolladores en C++ pueda crear kernels GPU tile altamente optimizados. Este modelo automatiza el paralelismo, el movimiento de memoria, la asincronía y otros detalles de bajo nivel, dando como resultado código C++ portable entre arquitecturas GPU NVIDIA. Más detalles en el blog post oficial.
CUDA Python 1.0 y semantic versioning

CUDA Python es el conjunto de librerías que expone CUDA al lenguaje Python. Con la versión 1.0, NVIDIA se compromete formalmente con semantic versioning: los cambios incompatibles solo ocurrirán en releases mayores, los releases menores agregan funcionalidades y los parches son correcciones de bugs. Toda API pública programada para eliminación se deprecará primero en una versión menor con un camino de reemplazo claro.
cuda.coop también está disponible dentro del paquete cuda-cccl bajo el namespace _experimental, sujeto a cambios de API. Ofrece las primitivas reutilizables block-wide y warp-wide a nivel de device para usar dentro de kernels CUDA Numba.
cuda.core es ahora estable
cuda.core ofrece una interfaz pythónica al runtime CUDA, incluyendo dispositivos, streams, programas, linkers, recursos de memoria y grafos. La versión 1.0 consolida APIs que se venían estabilizando en releases previos en una sola superficie soportada. Al mismo tiempo, se agregó soporte para green contexts, checkpointing CUDA y otras funcionalidades.
- Green contexts: dividen los SMs de una GPU en particiones disjuntas, cada una con su propio contexto y streams, para que los kernels sensibles a latencia queden aislados de los kernels de throughput largos en el mismo proceso.
- Checkpointing de procesos: snapshot completo del estado CUDA de un proceso en ejecución (asignaciones de device, streams, contexto) para restaurarlo más tarde. Habilita flujos tipo CRIU para procesos GPU: jobs largos tolerantes a falla, preempción y migración en clústeres compartidos, y warm-start rápido de workers de inferencia. Solo disponible en Linux.
- Inter-process sharing (IPC): comparte memoria GPU entre procesos Python sin copiar a través del host. Un proceso asigna y los demás mapean la misma VRAM física a su propio espacio de direcciones. Ideal para serving ML multiproceso y pipelines productor/consumidor sin copia.
A continuación, ejemplos rápidos de uso de las APIs de cuda.core:
from cuda.core import Device, Stream, Program, ProgramOptions, LaunchConfig, launch
# pick and activate a GPU
dev = Device()
dev.set_current()
# create a CUDA stream
stream = dev.create_stream()
# NVRTC compile + lookup
prog = Program(src, code_type="c++", options = ProgramOptions(arch=f"sm_{dev.arch}"))
kernel = prog.compile("cubin").get_kernel("my_kernel")
# launch a kernel
launch(stream, LaunchConfig(grid=64, block=256), kernel, *args)# Green contexts: partition SMs into disjoint groups
from cuda.core import ContextOptions, SMResourceOptions
sm = dev.resources.sm
long_grp, crit_grp = sm.split(SMResourceOptions(count=(sm.sm_count - 16, 16)))[0]
ctx_crit = dev.create_context(ContextOptions(resources=[crit_grp]))
s_crit = ctx_crit.create_stream()
# Process checkpoint / restore (Linux)
from cuda.core import checkpoint
proc = checkpoint.Process(os.getpid())
proc.lock(timeout_ms=5000)
proc.checkpoint()
proc.restore()
proc.unlock()CCCL Python 1.0.0: cuda.compute
cuda.compute trae los algoritmos paralelos altamente sintonizados de las CUDA Core Compute Libraries (CCCL) (sort, scan, reduce, transform, unique, histogram, top-k y otros) a Python como bloques de construcción llamables desde host. Entre los cambios respecto al release anterior:
- Lambdas Python utilizables como operadores de algoritmo, reduciendo boilerplate para reducciones, scans, transforms y predicados simples.
- Soporte para operadores con efectos secundarios (estado), habilitando casos como acumuladores corrientes y transformaciones condicionales.
- Nuevas APIs
cuda.compute.upper_boundycuda.compute.lower_boundque exponen la búsqueda binaria paralela de CUB a Python. - Caching consolidado entre todos los algoritmos para invocaciones repetidas más rápidas.
import cuda.compute
from cuda.compute import OpKind
d_input = cp.arange(1, 1_000_001, dtype=cp.int32)
d_output = cp.empty(1, dtype=cp.int32)
h_init = np.array([0], dtype=np.int32)
cuda.compute.reduce_into(
d_input, d_output, OpKind.PLUS, d_input.size, h_init
)
cuda.compute.reduce_into(
d_input, d_output,
lambda a, b: a if a > b else b,
d_input.size, h_init,
)Nuevo backend Numba CUDA MLIR
Numba CUDA MLIR es un nuevo generador de kernels compatible con Numba para Python, escrito desde cero sobre MLIR y el toolchain moderno NVVM. Preserva el familiar modelo de programación @cuda.jit de Numba-CUDA mientras entrega menor latencia de compilación, mejor diagnóstico y un camino más limpio para incorporar nuevas arquitecturas y capacidades de GPU a medida que llegan al stack NVVM. Se puede usar como reemplazo directo de numba.cuda cambiando solo la sentencia import:
# Before
from numba import cuda
# After
from numba_cuda_mlir import cuda
@cuda.jit
def vector_add(a, b, out):
i = cuda.grid(1)
if i < out.shape[0]:
out[i] = a[i] + b[i]Más allá de la compatibilidad existente con Numba-CUDA, Numba CUDA MLIR aporta:
- Compilación JIT más rápida: sobre una batería de kernels reales (vector add, softmax, Cholesky, attention, Black-Scholes, FFT, matmul), los tiempos warm de JIT son aproximadamente 1.4x más rápidos en geomedia y hasta 2x en kernels individuales, respecto a Numba-CUDA.
- Menor latencia de launch: la sobrecarga host-side por despacho de kernel cae aproximadamente 2-3.5x para kernels típicos y hasta 17x para kernels con muchos argumentos escalares, donde antes el empaquetado de argumentos dominaba el costo.
Numba CUDA MLIR 0.3 ya está disponible en PyPI como numba-cuda-mlir[cu13].
¿Cómo se prueba CUDA Python hoy?
El stack completo se instala directamente desde PyPI:
pip install cuda-python cuda-cccl numba-cuda-mlir[cu13]Esto trae cuda.bindings 13.3.0, cuda.core 1.0.0 y cuda.compute 1.0.0, junto con cuda-pathfinder para descubrimiento de librerías.
CompileIQ: autoajuste de compilador por kernel
Junto a CUDA 13.3 debuta CompileIQ, un nuevo framework de autoajuste de compilador orientado a máximo rendimiento en kernels GPU. Los compiladores GPU aplican heurísticas de optimización genéricas que son ampliamente efectivas pero no necesariamente óptimas para cada kernel específico. CompileIQ invierte esa dinámica usando algoritmos evolutivos y genéticos para generar configuraciones de compilación especializadas a medida para cada kernel.
Ese cambio desbloquea rendimiento adicional. Por ejemplo, para kernels críticos como GEMM y attention (que concentran más del 90% del compute de inferencia LLM), CompileIQ entrega hasta un 15% de speedup sobre kernels Triton attention y CUTLASS GEMM que ya estaban optimizados.
Librerías matemáticas
Las librerías matemáticas centrales de CUDA en 13.3 traen varias funcionalidades nuevas y mejoras de rendimiento:
- cuSPARSE: soporte para formato CSC en SpSV y SpSM, soporte de precisión mixta en SpMVOp, soporte para CSR de tipo de índice mixto (offset de 64 bits, índice de 32 bits) en SpMVOp. Se mejoró el rendimiento de
cusparseSpMVOp_createDescr()en 2,5 veces. Se introduce la nueva API SPMVOP_ALG1, que permite actualizar valores de matriz manteniendo el mismo patrón de dispersión, optimización del tamaño de buffer y reducción del overhead de preprocesamiento.
¿Qué pesos relativos tiene este release?
CUDA 13.3 ataca tres frentes en paralelo: hace más accesible el rendimiento de Hopper a desarrolladores C++ con Tile programming, estabiliza la pila Python que venía evolucionando rápido, y empuja el techo de rendimiento sobre kernels que ya estaban afinados con CompileIQ. El 15% extra sobre GEMM y attention no es marginal cuando hablamos del 90% del cómputo de inferencia LLM en producción.