Investigadores de Sakana AI y NVIDIA publicaron en arXiv un trabajo conjunto que ataca el cuello de botella de costos en grandes modelos de lenguaje sin tocar la arquitectura. La propuesta combina un nuevo formato de matriz dispersa llamado TwELL con un set de kernels CUDA optimizados, y reporta aceleraciones de 20,5% en inferencia y 21,9% en entrenamiento sobre un modelo de 2.000 millones de parámetros corriendo en un nodo de ocho GPUs H100 PCIe.
¿Cuál es el problema que TwELL resuelve?
En un transformer típico, las capas feedforward consumen más de dos tercios de los parámetros del modelo y más del 80% del total de FLOPs. La parte frustrante es que la mayoría de las neuronas no se activan para cada token: con activación ReLU, los autores miden que el 99,5% de las activaciones ocultas son cero. En teoría se podría saltar ese cómputo, pero las GPUs NVIDIA están optimizadas para multiplicación densa con Tensor Cores, y los formatos sparse tradicionales como ELLPACK necesitan un kernel adicional para convertir activaciones densas en sparse, gasto que cancela el ahorro.
Trabajos previos como TurboSparse, ProSparse y Q-Sparse atacaron este problema solo en el régimen GEMV de un token (inferencia interactiva), pero fallaban en el régimen GEMM batched de miles de tokens, justo el que cubre entrenamiento e inferencia de alto volumen.
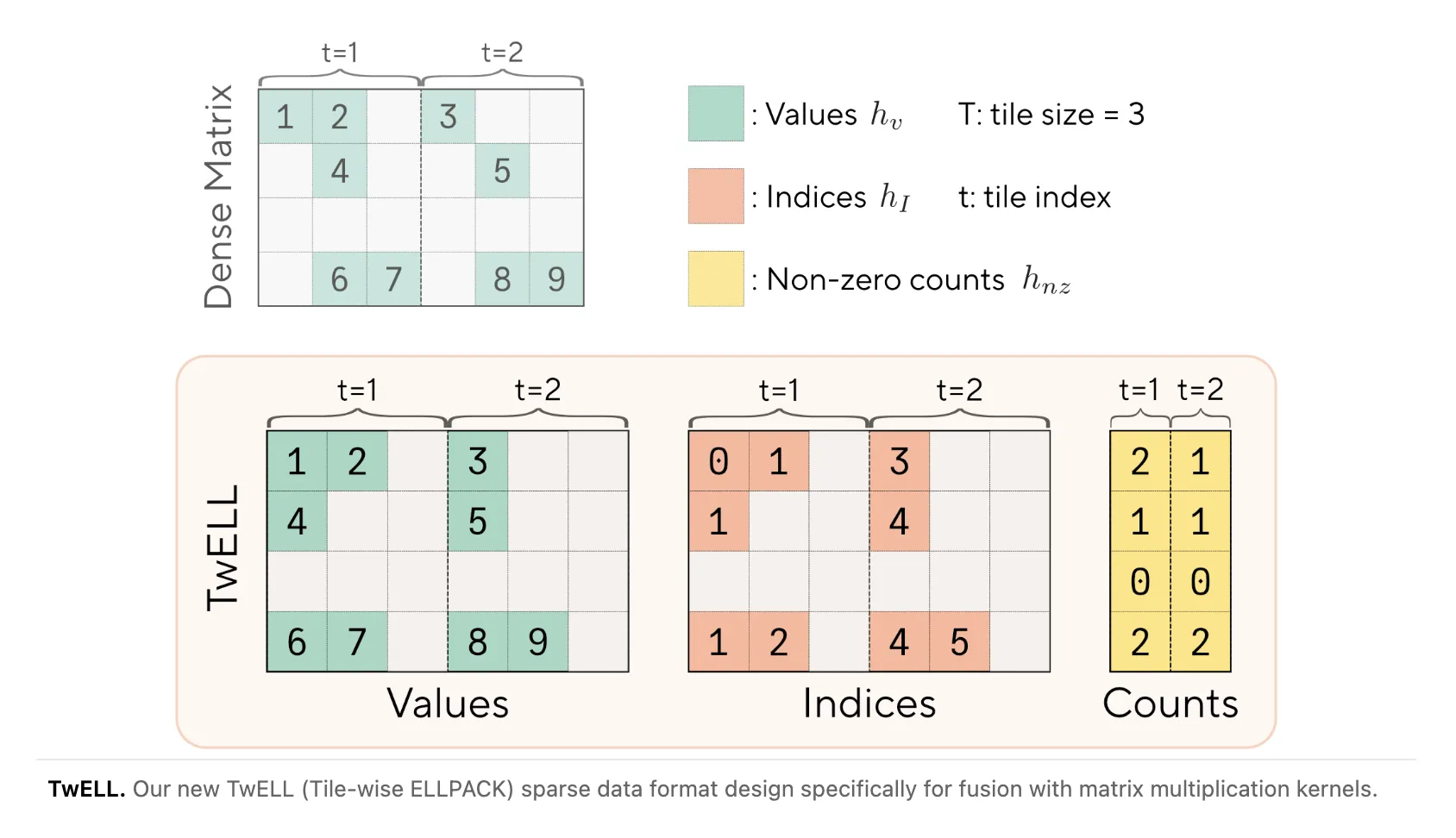
¿Qué hace distinto a TwELL frente a ELL clásico?
La idea central es construir el formato sparse dentro del epílogo del kernel de matmul existente, sin lanzamiento extra ni escritura adicional a memoria global. TwELL particiona las columnas de la matriz de activaciones en tiles horizontales que coinciden con el tamaño de tile T_n del matmul, y empaca los valores no-cero localmente dentro de cada tile.
En inferencia, un solo kernel fusionado lee las activaciones en formato TwELL y ejecuta las proyecciones up y down juntas. El estado intermedio nunca se escribe en memoria global, recortando el tráfico DRAM en cada pasada hacia adelante. Para entrenamiento, donde la sparsity es altamente no uniforme, los autores introducen un formato híbrido que rutea filas dinámicamente entre una matriz ELL compacta y un respaldo denso para filas con demasiados no-ceros.
Receta de entrenamiento: dos cambios y nada más
El equipo describe la integración como deliberadamente mínima:
- Reemplazar SiLU por ReLU como activación del gate. ReLU produce ceros exactos en inputs negativos, lo que permite la sparsity sin estructura.
- Agregar un término L1 sobre las activaciones ocultas, con coeficiente recomendado 2x10⁻⁵.
Nada más cambia: ni learning rate, ni weight decay, ni batch size, ni optimizador. La sparsity se estabiliza en unos 1.000 pasos de entrenamiento (cerca de 1.000 millones de tokens), así que los kernels rinden durante casi toda la corrida y no solo al final.
¿Cuánto se acelera realmente?
Los benchmarks publicados muestran ganancias que escalan con el tamaño del modelo. Sobre un modelo de 2B parámetros, la accuracy promedio cae de 49,1% a 48,8% (esencialmente plano), mientras la inferencia gana 20,5% y el entrenamiento 21,9%, con un consumo de energía por token un 17% menor. Las pruebas corren sobre un nodo de ocho H100 PCIe con secuencias de 2.048 tokens.
En modelos más chicos las ganancias son algo menores en inferencia (17% en 0,5B) pero el ahorro de memoria peak alcanza el 28% en el 1,5B, lo que permite entrenar con batches más grandes. En una NVIDIA RTX PRO 6000 (188 SMs vs 114 del H100), los autores reportan aceleraciones aún mayores en entrenamiento porque el GEMM denso corre más lento ahí, ampliando la ventaja relativa de TwELL sobre hardware más accesible.
Implicaciones para integradores y hardware accesible
El código y los kernels quedan liberados como open source en GitHub junto al paper en arXiv (2603.23198, aceptado a ICML 2026), y los autores señalan que la técnica funciona con cualquier arquitectura Transformer++ con feedforward gated (Llama, Qwen, Mistral). Para un equipo que ya entrena modelos de 1-2B parámetros en GPUs accesibles, el cambio se reduce a un pull request en el código de entrenamiento. La promesa de 17% menos energía por token también tiene lectura concreta: un cluster que hoy paga decenas de miles de dólares al mes en electricidad podría ahorrar el equivalente a una GPU consumer cada año.



