Código disponible en github.com/facebookresearch/ads_model_kernel_library
En este post, Meta presenta el diseño de TLX Block Attention: un kernel Triton dirigido a GPUs NVIDIA Blackwell que aprovecha el conocimiento en tiempo de compilación de un patrón de atención block-diagonal para eliminar categorías enteras de overhead algorítmico presentes en las implementaciones de atención de propósito general. En GPUs NVIDIA B200, el kernel logra un speedup de ~1,85x en el forward y ~2,50x en el backward sobre Flash Attention v2, además de un ~3,5x en el backward combinado de atención y rotary embeddings cuando los rotary embeddings se fusionan en el epilogue de atención.
Este trabajo se construye sobre TLX (Triton Language Extensions), un conjunto de extensiones de bajo nivel al compilador Triton que exponen control nativo del hardware sobre warp specialization, operaciones asíncronas de tensor cores y gestión de jerarquía de memoria en GPUs Blackwell. TLX cierra la brecha entre la productividad Python de Triton y el control fino del hardware que tradicionalmente requería CUDA o CUTLASS en crudo. Más en el repositorio triton-ext.
1. ¿Qué problema resuelve TLX Block Attention?
La self-attention es un mecanismo que permite a un modelo ponderar cuán relevante es cada elemento de una secuencia respecto a los demás: básicamente pregunta "qué partes de este input deberían informar mi comprensión del resto". Es el bloque básico de los Transformers y lo que permite a estos modelos capturar relaciones ricas y dependientes del contexto.
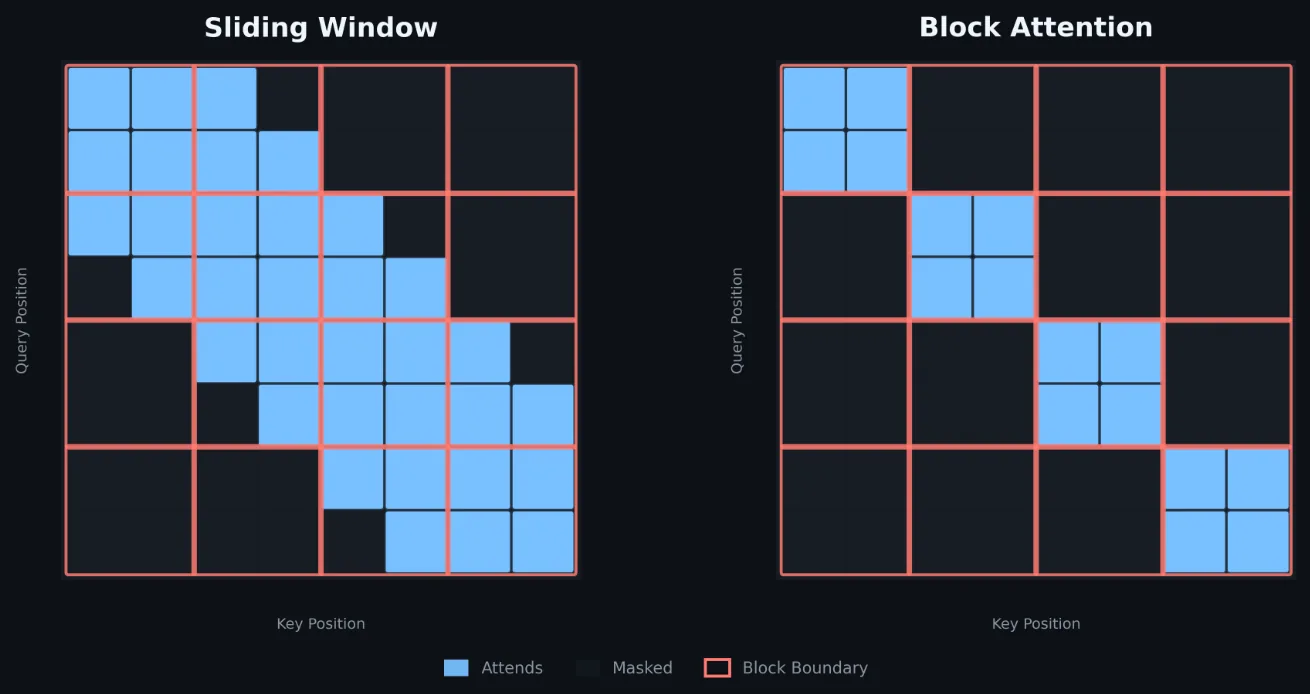
La self-attention block-diagonal —donde la secuencia se parte en grupos de tamaño fijo que solo atienden dentro de sí mismos— es un patrón muy usado en modelos de recomendación y feature-interaction (BlockBERT, Qiu et al., EMNLP 2020). En el stack de ads ranking de Meta, las cargas de producción típicas corren con batch sizes de 1.152, secuencias de hasta unos 4.000 tokens, dimensiones de head de 64 o 128 y alrededor de 70% de sparsity en la estructura de atención a medida que crecen las secuencias. A medida que estos modelos se vuelven más profundos y anchos, el costo de la atención se transforma en el cuello de botella dominante.
Hoy estas cargas corren sobre kernels de propósito general como Flash Attention v2 con block masking o ventana deslizante. FlexAttention (FA4) soporta patrones block-sparse pero opera con un tamaño mínimo de tile de 256, incompatible con los bloques de 64 tokens que requieren estos modelos. Flash Attention v2 con block masking es el mejor baseline disponible a ese tamaño de tile, pero deja rendimiento significativo sobre la mesa: la iteración por tiles, la corrección del softmax online, el bookkeeping del logsumexp y los lanzamientos de kernels auxiliares son esenciales para una atención causal de largo arbitrario, pero puro overhead cuando el patrón es block-diagonal y conocido en tiempo de compilación.
La tesis central del trabajo: cuando se conoce el patrón de atención en tiempo de compilación, se puede construir algo mucho más rápido. Meta explota la restricción fija de que cada tile Q atiende exactamente a un tile K/V y propaga ese conocimiento por todo el algoritmo para colapsar acumuladores de varias iteraciones en GEMMs únicos, eliminar etapas de corrección y remover lanzamientos de kernels auxiliares.
2. ¿Por qué Block Attention permite tantas simplificaciones?
Flash Attention estándar maneja secuencias de largo arbitrario iterando un tile Q sobre múltiples tiles K/V, mientras mantiene estadísticas vivas (máximo por fila y log-sum-exp) y aplica un factor de corrección en cada paso para preservar la estabilidad numérica:
# Inner loop de Flash Attention (estándar)
for k_tile in K_tiles:
S = Q @ k_tile.T # scores parciales
m_new = max(m_old, rowmax(S))
alpha = exp(m_old - m_new) # factor de corrección
O = alpha * O + exp(S - m_new) @ v_tile
l = alpha * l + rowsum(exp(S - m_new))
O = O / l # normalización final
# Guarda L = m + log(l) en HBM para el backwardEste enfoque es correcto y elegante para secuencias arbitrarias. Pero para atención block-diagonal con un tamaño de bloque fijo de 64 tokens, el bucle de Q-tile-sobre-K-tiles se reduce a una sola iteración: cada tile Q y su tile K/V correspondiente son el mismo tile. Esa restricción única se propaga en cascada por todo el algoritmo:
- Sin iteración multi-tile. La matriz de scores S = Q · Kᵀ ∈ ℝ^{64×64} queda completa después de un solo GEMM. No hay bucle que mantener.
- Sin corrección de softmax online. Como solo hay un tile, el máximo y la suma por fila calculados sobre S son globalmente correctos al instante. El factor de corrección α = exp(m_old − m_new) es idénticamente 1 y se puede eliminar.
- Sin almacenamiento de logsumexp (L). Flash Attention guarda el log-sum-exp por fila en HBM para que el backward pueda recomputar el softmax. Con un solo tile, el backward puede recomputar P = softmax(S) directamente desde Q, K, V sin tensor auxiliar, eliminando una escritura y lectura completas a HBM por cada par forward/backward.
- Sin kernel de preprocesamiento Di. El backward estándar de Flash Attention lanza un kernel separado para calcular Di = rowsum(dO ⊙ O) antes del backward principal. En TLX Block Attention, Di se calcula inline dentro de la etapa dP/dS del backward, eliminando un kernel launch y su tráfico de memoria asociado.
- Sin acumulación de output con reescalado. Con un solo tile, la salida O = P · V es un resultado fresco de un único GEMM, no una acumulación de resultados parciales reescalados. Esto habilita
use_acc=Falseen todas las llamadasasync_dot, indicando al hardware del tensor core que el acumulador TMEM no necesita preservarse entre llamadas y puede reusarse libremente.
# Del kernel: use_acc=False indica que no se necesita acumulación
tlx.async_dot(
q_tile[buff_idx],
k_tile_T,
TMEMqk[tmem_idx],
use_acc=False, # Resultado fresco, sin acumulación
mBarriers=[qk_SMEM_free[buff_idx], qk_TMEM_full[tmem_idx]],
)Estas no son micro-optimizaciones: representan la eliminación de etapas algorítmicas enteras. El backward pass se beneficia de manera particular. La ausencia de un tensor L almacenado quita un viaje de ida y vuelta a HBM por cada batch × heads × secuencia, y el cómputo inline de Di elimina un kernel launch con su overhead asociado de driver y ancho de banda.
3. ¿Cómo es la arquitectura del kernel?
Meta eligió Triton como framework de autoring porque ofrece un modelo de programación nativo de Python orientado a tiles que mapea de manera natural a la estructura de pipeline con warp specialization descrita más abajo, evitando el boilerplate de CUDA o CUTLASS y manteniendo portabilidad. Las extensiones TLX exponen primitivas específicas de Blackwell como async_dot, local_trans y gestión explícita de barreras TMEM/SMEM en un nivel de abstracción que balancea control de hardware con productividad.
Este kernel se apoya en varias primitivas de TLX que van más allá del Triton base: tlx.async_dot para emitir operaciones MMA tcgen05 con warp specialization y control explícito de acumulador; tlx.async_descriptor_load para llenados de SMEM por TMA; tlx.local_trans para transferencias TMEM-a-registro; y el modelo de sincronización mBarrier que coordina la pipeline productor-consumidor entre warp groups.
Warp specialization
TLX Block Attention usa warp specialization: distintos warps dentro del mismo CTA son asignados de manera permanente a unidades de hardware diferentes y ejecutan paths de código distintos durante toda la vida del kernel. Esto contrasta con el modelo CUDA tradicional, donde todos los warps ejecutan el mismo código y divergen solo a través de condicionales.
Fig. 1 — Timeline de warps del pipeline forward (conceptual, una iteración):
Tiempo →
Load [─ TMA Q,K ─][─ TMA V ─]
QK MMA [── async_dot Q·Kᵀ ──]
Softmax [── exp2/normalize → P ──]
PV MMA [── async_dot P·V ──]
Epilogue [── local_load → BF16 → store ──]
La salida de cada etapa señaliza una barrera que desbloquea la siguiente etapa, creando una pipeline productor-consumidor entre unidades de hardware. Mientras el warp de Epilogue escribe el tile i a memoria global, los warps MMA computan el tile i+1 y el warp Load trae el tile i+2 vía TMA: tres tiles en vuelo simultáneamente.
Contexto roofline
Con BLOCK_D=64 y HEAD_DIM=128, la intensidad aritmética es de ~33 FLOP/byte, bastante por debajo del punto de quiebre (ridge point) de la B200 de ~281 FLOP/byte. El kernel es memory-bandwidth-bound por diseño. Por eso ocultar latencia vía TMA y minimizar el tráfico innecesario de memoria (el tensor L eliminado, el rotary fusionado) son las palancas de optimización dominantes.
Manejo de buffers
Para mantener las unidades de hardware ocupadas continuamente, el kernel usa SMEM con triple buffer (3 slots) y TMEM con doble buffer (2 slots), consumiendo unos 169 KB del presupuesto de 256 KB de SMEM. Con tres slots SMEM, el warp Load puede precargar el tile i+2 mientras el warp MMA procesa el tile i+1 y el warp Epilogue drena el tile i. El kernel de backward baja a SMEM doble buffer (~162 KB) para acomodar tiles de gradiente adicionales dentro del mismo presupuesto de 256 KB.
4. ¿Cómo se gana el 2,50x en el backward?
En Flash Attention estándar, el backward pass requiere que el forward guarde el tensor logsumexp (L) en HBM. Este tensor es necesario para reconstruir las probabilidades de atención (P) durante el backward. Además, la atención estándar requiere un kernel separado de preprocesamiento para calcular Δᵢ (la suma por fila de dO ⊙ out).
Como la atención block-diagonal calcula toda la matriz de scores 64x64 en un solo tile, Meta bypassea ambos requisitos por completo. El kernel de backward no lee ningún tensor de logsumexp ni necesita un paso de preprocesamiento separado: en su lugar recomputa S = Q · Kᵀ y P = softmax(S) inline, una operación barata cuando el tile cabe en un solo pase.
Esta cascada de simplificaciones permite construir una pipeline de backward warp-specialized de 7 etapas completamente fusionada.
¿Qué significa para Chile y LatAm?
Para los equipos de ranking y recomendación en empresas locales —Mercado Libre, Cornershop, NotCo, Falabella IA— el kernel TLX Block Attention es un caso de estudio concreto sobre cómo bajar el costo unitario de inferencia y entrenamiento cuando el patrón de atención es conocido. Las tres cifras a anotar son: 1,85x speedup forward, 2,50x backward y 3,5x con rotary embeddings fusionados, todas medidas en NVIDIA B200. Eso se traduce, a un costo aproximado de USD 4,50 por hora-B200 en cloud público, en ahorros de 45-65% del gasto en GPU para cargas equivalentes. La condición previa es que el modelo use atención block-diagonal con bloques de 64 tokens, lo que aplica a la mayoría de los modelos de ads ranking modernos y a algunos modelos de recomendación. El código abierto en facebookresearch/ads_model_kernel_library permite portarlo a stacks de ranking propios sin pasar por NVIDIA NeMo ni licencias adicionales.