
Una entrada técnica publicada por NVIDIA en su Developer Blog detalla cómo Dynamo, su stack de inferencia distribuida, ahora soporta intercambios agénticos multivuelta: razonamiento intercalado con llamadas a herramientas, parsers específicos por modelo, despacho de tool calls en streaming y, sobre todo, una corrección que reduce unas 5x el tiempo hasta el primer token (TTFT) cuando se sirve a clientes tipo Claude Code, Codex u OpenClaw.
¿Qué cambió en NVIDIA Dynamo?
El motor de inferencia debe respetar un contrato de interacción más expresivo que el de modelos antiguos: el modelo intercala razonamiento con varias llamadas a herramientas en una misma vuelta de asistente, y la siguiente vuelta del usuario devuelve los resultados al contexto. NVIDIA endurece cuatro frentes en esta versión:
- Replay de razonamiento por modelo y por turno: los tramos de pensamiento se mantienen anclados a la tool call que explican. En la versión anterior, el mismo turno se reconstruía como un único bloque de razonamiento seguido de un bloque de tool calls, lo que confundía al modelo al perder la secuencia y los delimitadores.
- Estabilidad de prompt para reusar la caché KV: removiendo el header de facturación específico por sesión vía el flag
--strip-anthropic-preamble, la caché KV vuelve a reutilizarse entre sesiones. - Streaming de tool calls como eventos de despacho tipados: las llamadas a herramientas se ejecutan apenas se decodifican, sin esperar al fin del turno.
- Soporte nativo del template de razonamiento: controles de thinking por petición que preservan el razonamiento intercalado en turnos con tool-calling.
El header que envenenaba la caché
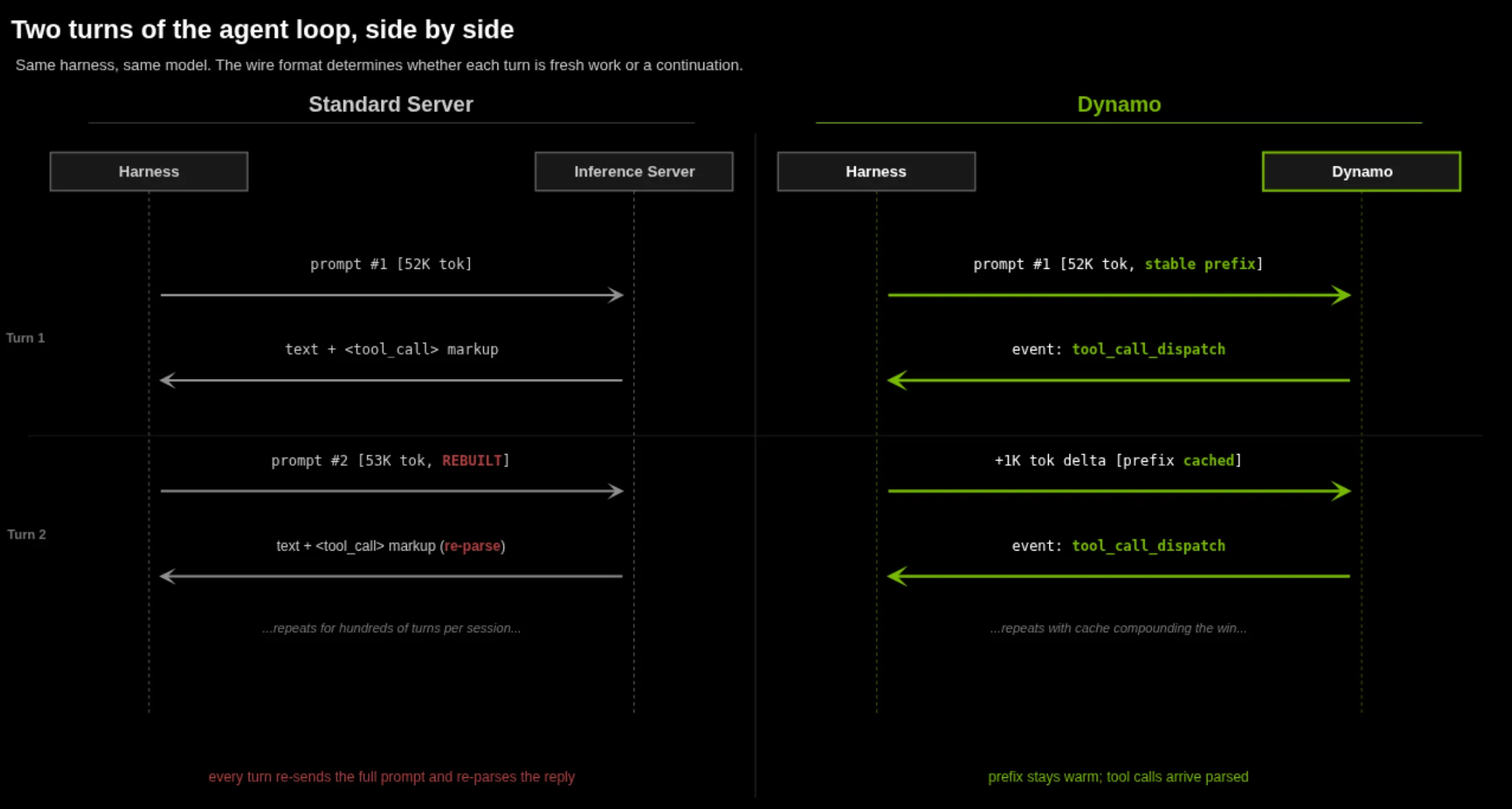
Claude Code envía miles de tokens de prompt scaffolding pensados para mantenerse idénticos entre usuarios y sesiones. El problema: cada prompt arranca con un header de facturación específico por sesión que destruía la caché en servicios de inferencia custom.
x-anthropic-billing-header: cc_version=0.2.93; cch=abc123def456==;
You are Claude Code, an interactive CLI tool...Una línea variable en la posición cero significa que cada sesión nueva arranca con un prefijo distinto, así que las instrucciones estables y las definiciones de herramientas que vienen atrás nunca alinean para reutilización.
El fix mecánico es trivial: quitar el header inestable antes de la tokenización. El impacto medido es mayúsculo. NVIDIA midió el efecto en un deployment de Dynamo sobre B200 con un prompt de 52K tokens:
- Prefijo estable: 168 ms TTFT
- Con header por sesión: 912 ms TTFT
- Removiendo el header antes de tokenizar: 169 ms TTFT
Un header variable cuesta 744 ms por request y convierte un system prompt reutilizable en un prefill frío. Es una reducción de aproximadamente 5x para usuarios nuevos que conectan contra el mismo despliegue, o para el mismo usuario que abre una sesión nueva.

Razonamiento intercalado y dos parsers a la vez
El replay del razonamiento no tiene una forma universal correcta. Algunos modelos descartan deliberadamente el razonamiento previo en turnos sin tool calls (DeepSeek-R1 es el ejemplo más claro), pero esa misma conducta es errónea en turnos agénticos donde la cadena de pensamiento explica la secuencia de llamadas.
NVIDIA cita explícitamente el postmortem público de Anthropic del 23 de abril sobre Claude Code: el thinking previo puede limpiarse al reanudar una sesión para reducir el costo de prefill después de que el prompt cacheado expira.
En las pruebas, NVIDIA usó el modelo nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4 corriendo sobre 4x B200 con TP=4, parser de razonamiento nemotron_deci y parser de tool calls qwen3_coder. El resultado intermedio es un stream SSE en el que el bloque thinking fluye token a token entre los 82 ms y los 602 ms, seguido por un breve bloque de texto y luego el tool_use como unidad estructurada a los 800 ms.
Para configurar Dynamo en este modo
Las banderas relevantes en el frontend son:
python -m dynamo.frontend \
--http-port 8000 \
--enable-anthropic-api \
--strip-anthropic-preamble \
--enable-streaming-tool-dispatchDel lado del worker, los parsers se configuran con --dyn-tool-call-parser <parser> y --dyn-reasoning-parser <parser>. NVIDIA empaquetó esos parsers en crates reutilizables, lo que en la práctica permite reproducir el comportamiento en stacks de inferencia custom sin reescribir desde cero. La corrección completa, incluyendo la secuencia correcta de eventos Anthropic Messages API, viene en el PR #7358 del repositorio ai-dynamo.



