TL;DR: el delegado MLX para ExecuTorch ya está disponible.
- El nuevo delegado MLX habilita inferencia GPU acelerada y optimizada para modelos PyTorch en Mac con Apple Silicon, usando el framework MLX de Apple.
- El delegado se integra con el stack de exportación de PyTorch 2 y soporta múltiples opciones de cuantización (BF16, FP16, FP32, afín de 2/4/8 bits y NVFP4).
- Cubre transformers densos (Llama, Qwen, Gemma), modelos Mixture-of-Experts dispersos y speech-to-text (Whisper, Voxtral, Parakeet) tanto para transcripción offline como en tiempo real.
- Nota: el delegado MLX está en estado experimental.
Apple Silicon se transformó en una plataforma popular para correr modelos de lenguaje grandes de manera local. Hasta ahora, los usuarios de ExecuTorch en macOS estaban limitados a backends basados en CPU como XNNPACK o el backend AOTI Metal. Con la liberación del delegado MLX, la inferencia pasa al GPU vía el framework MLX de Apple.
¿Qué hace exactamente el delegado MLX?
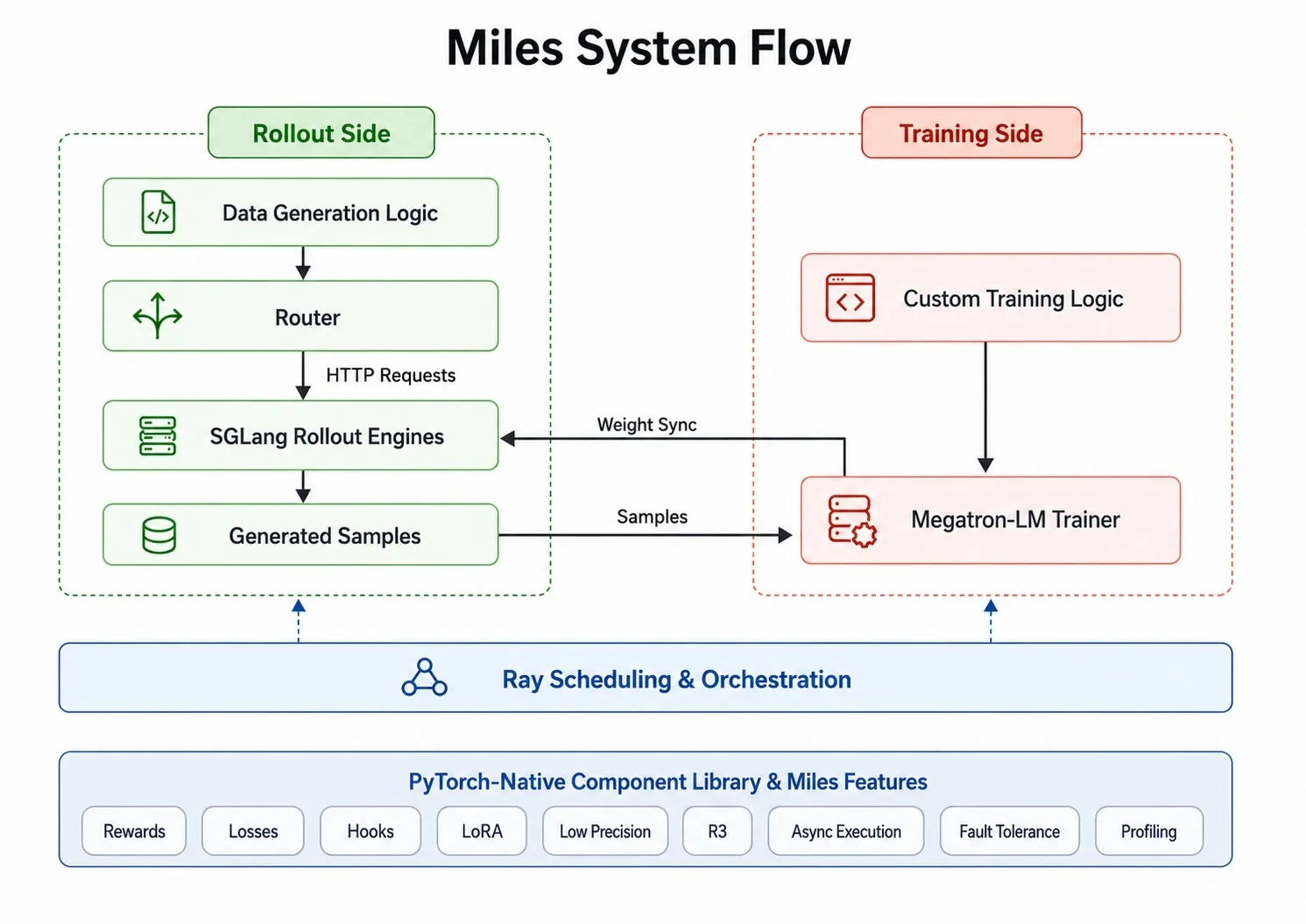
El delegado MLX es un backend de ExecuTorch que compila y corre modelos de PyTorch sobre GPU de Apple Silicon. El modelo se exporta con el pipeline estándar de ExecuTorch y el delegado se encarga del resto: particionar el grafo, serializarlo a un formato optimizado y despachar las operaciones a los kernels Metal del GPU en tiempo de ejecución.
Desde la perspectiva del desarrollador, el flujo es idéntico al de cualquier otro backend de ExecuTorch:
- Exportar el modelo con
torch.export. - Bajarlo con
to_edge_transform_and_lowerusando elMLXPartitioner. - Correr el archivo
.pteresultante con el runtime de ExecuTorch.
El delegado actualmente soporta cerca de 90 operadores ATen, lo que cubre todo el rango necesario para inferencia de transformers: matmul cuantizado, atención multi-cabezal, embeddings de posición rotatorios, ruteo de mezcla de expertos y operaciones recurrentes de estados, entre otras.
¿Por qué hacerlo como delegado de ExecuTorch?
Ya existen herramientas excelentes para correr modelos en Apple Silicon, entre ellas el propio mlx-lm del proyecto MLX. El equipo de PyTorch lo justifica con tres razones.
Rendimiento. El delegado MLX alcanza 3-6 veces más throughput en cargas generativas comparado con los delegados ExecuTorch previos en macOS. Mover la inferencia a los kernels Metal optimizados de MLX hace una diferencia significativa para aplicaciones de chat y transcripción en tiempo real.
Integración con PyTorch 2. El delegado se enchufa directamente al stack de exportación de PyTorch 2. Usa torch.export para capturar el grafo y TorchAO para cuantización, las mismas herramientas que el resto de backends. Si el modelo se puede exportar con torch.export, corre sobre MLX.
Portabilidad. ExecuTorch ofrece una sola API de runtime para todos los backends. Una aplicación construida sobre el runtime C++ o Python puede correr modelos exportados para MLX, XNNPACK, CoreML, Vulkan o CUDA sin cambiar el código de la aplicación.
Cuantización y tipos de datos
El delegado cubre las opciones de precisión y cuantización esperables para inferencia en dispositivo:
- BF16, FP16 y FP32 para pesos y activaciones.
- Cuantización afín de 2, 4 y 8 bits vía la API
quantize_de TorchAO. Es el mismo esquema de cuantización que usan los backends XNNPACK y Vulkan, lo que abre la puerta a archivos PTE únicos que corren en el backend disponible en tiempo de ejecución. - Cuantización NVFP4 usando el tipo de dato FP4 de NVIDIA.
- Embeddings cuantizados con pesos compartidos entre la capa de embedding y la cabeza del modelo de lenguaje.
¿Qué modelos puedo correr?
El delegado fue validado sobre un rango amplio de arquitecturas.
Modelos de lenguaje
Transformers densos funcionan sin ajustes, con soporte para cachés KV completos y de ventana deslizante:
- Llama 3.2 1B
- Qwen 3 (0.6B, 1.7B, 4B)
- Phi-4 mini (3.8B)
- Gemma 3 (1B, 4B) con atención de ventana deslizante
Modelos Mixture-of-Experts dispersos se soportan mediante operaciones de gather personalizadas que rutean tokens al experto correcto sobre el GPU:
- Qwen 3.5 35B-A3B: 256 expertos con ruteo top-8, combinando capas de atención lineal GatedDeltaNet con capas de atención SDPA completas.
Modelos de transcripción de voz
Transcripción offline sobre una grabación completa:
- OpenAI Whisper (de tiny hasta large-v3-turbo)
- NVIDIA Parakeet TDT (0.6B) con timestamps a nivel palabra
- Mistral Voxtral (3B)
Transcripción streaming en tiempo real que procesa audio en chunks a medida que llega, habilitando casos de uso en vivo:
- Mistral Voxtral Realtime (4B) con entrada de micrófono en vivo, cachés KV en ring buffer y atención de ventana deslizante.
Cobertura adicional
Más allá de estos modelos flagship, se validaron más de 30 modelos adicionales a través de los test suites del backend, cubriendo transformers densos, arquitecturas encoder-decoder y modelos de visión.
Cada modelo soportado tiene un README con instrucciones detalladas de exportación e inferencia:
- LLMs vía HuggingFace: cubre Llama, Qwen y Gemma usando optimum-executorch.
- LLMs vía export_llm: cubre Phi-4 y Stories 110M con el pipeline basado en Hydra.
- Qwen 3.5 MoE: cubre la exportación de MoE dispersa con
--backend mlx. - Voxtral Realtime: cubre transcripción de voz streaming y offline.
- Parakeet: cubre reconocimiento de voz con timestamps.
- Whisper: cubre los modelos de reconocimiento de voz de OpenAI.
¿Qué significa para el ecosistema Apple Silicon?
La llegada del delegado MLX al stack PyTorch 2 cierra la brecha entre dos mundos que durante meses operaron en paralelo: investigadores entrenando con PyTorch sobre CUDA y desarrolladores de productos corriendo los mismos modelos en Mac M1/M2/M3/M4. Hasta ahora, ese paso intermedio implicaba reescribir el código a mlx-lm o aceptar la penalidad del CPU. El delegado elimina ese costo y permite empacar una sola distribución que apunte a MLX, CoreML, Vulkan o CUDA según el dispositivo final.
Para desarrolladores que quieran reportar problemas o requerir nuevas funcionalidades, el equipo invita a abrir issues en el repositorio de ExecuTorch en GitHub o sumarse al canal de Discord.