ExecuTorch extiende el ecosistema PyTorch para entregar inferencia local de IA en dispositivos edge restringidos. Para proveer un punto de entrada practico, Arm creo un conjunto de Jupyter Labs que complementan la documentacion oficial de ExecuTorch explicando tanto el como como el por que de cada paso. El blog y los labs introducen inferencia tanto en CPU como en NPU a traves de plataformas Cortex-A y Cortex-M + Ethos-U, y muestran el uso de adaptadores de Model Explorer desarrollados por Arm para ganar visibilidad sobre el despliegue de modelos con ExecuTorch.
La IA se esta volviendo rapida e indiscutiblemente parte de como trabajamos y vivimos. Pero hoy, mucha de esa inteligencia sigue atada al cloud, accedida via APIs e interfaces web.
Ese modelo no siempre encaja. Las empresas quieren cada vez mas acercar la IA a donde realmente se usa: dispositivos como wearables, camaras inteligentes y otros sistemas edge de bajo consumo. Correr IA localmente puede reducir latencia, mejorar privacidad y desbloquear capacidades nuevas en tiempo real, pero tambien introduce un nuevo desafio: ¿como corres modelos complejos eficientemente sobre hardware restringido con memoria, computo y energia limitados?
PyTorch se volvio el framework principal para entrenar e inferenciar modelos de IA en el cloud. ExecuTorch extiende ese ecosistema para llevar la inferencia local al edge. Toma un modelo PyTorch, lo exporta a un formato liviano y lo corre en un runtime construido especificamente para inferencia edge. Si ya estas familiarizado con PyTorch, el atractivo es claro: te quedas en el mismo ecosistema mientras ganas un camino de despliegue mejor adaptado a dispositivos reales.
¿Como funciona ExecuTorch en CPUs edge?
Puede que ya estes familiarizado con correr PyTorch en dispositivos edge como la Raspberry Pi 5. Mientras eso funciona bien, la Pi se ubica en la categoria de single-board computers (SBCs), con muchisimos mas recursos que muchos sistemas embebidos o IoT de grado de produccion. Para targets mas restringidos, como microcontroladores Cortex-M, correr PyTorch no es viable por su tamano y dependencias.
ExecuTorch aborda esto y permite el despliegue eficiente de modelos PyTorch a dispositivos edge. Esto se logra exportando un modelo a un artefacto minimo .pte que contiene tanto los pesos del modelo como un grafo de computacion estatico. Eso elimina la necesidad de Python en tiempo de ejecucion y evita el overhead de ejecucion dinamica que no es necesario para inferencia.
El paso de export es seguido por lowering, donde el grafo del modelo se transforma a una forma compatible con el backend. Ahi es donde empieza la optimizacion hardware-aware.
El artefacto resultante es:
- liviano y portable
- predecible en ejecucion
- adecuado para despliegue en sistemas restringidos
Mas alla de la portabilidad del .pte, hay otros beneficios. Incluso en dispositivos como la Raspberry Pi, que pueden correr modelos PyTorch sin necesitar ExecuTorch, se pueden encontrar mejoras de rendimiento usando ExecuTorch. Pero el rendimiento depende fuertemente de como se ejecuta el modelo. ExecuTorch logra rendimiento delegando partes del modelo a backends optimizados.
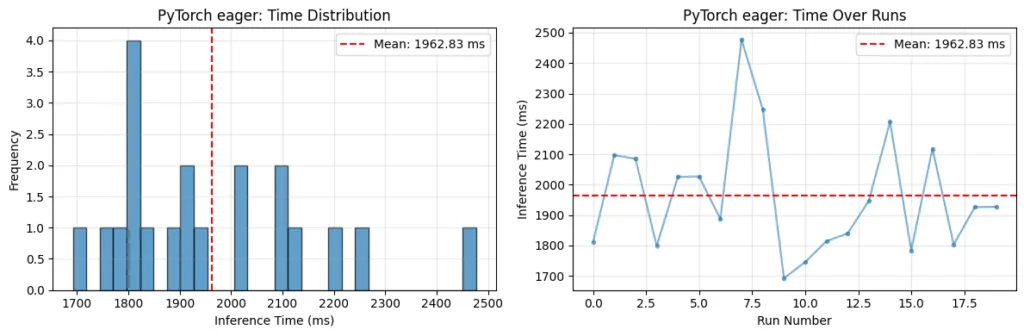
En CPUs Arm, eso se hace tipicamente usando el backend XNNPACK. Cuando esta habilitado, operadores soportados (como convoluciones y multiplicaciones de matrices) se delegan a implementaciones altamente optimizadas. En plataformas Arm, esas implementaciones aprovechan los microkernels KleidiAI, que hacen uso eficiente de caracteristicas arquitectonicas como Neon. En los labs, se compara la inferencia de un modelo transformer OPT-125M sobre una Raspberry Pi 5: el grafico muestra una reduccion significativa de latencia al usar ExecuTorch con XNNPACK.
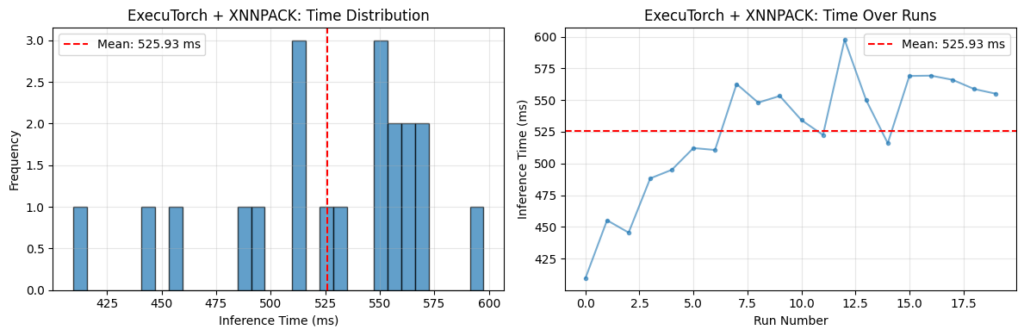
Fig 1. Comparacion del tiempo de inferencia de PyTorch y ExecuTorch en la CPU de Raspberry Pi 5
Tanto el modo eager de PyTorch como ExecuTorch + XNNPACK se corrieron descartando varias iteraciones de calentamiento para evitar el patron tipico de corridas iniciales mas lentas seguidas de un steady-state mas rapido. En el caso de ExecuTorch se observa la tendencia opuesta: las primeras corridas medidas son mas rapidas, con la latencia aumentando en corridas subsiguientes. Este comportamiento se atribuye a efectos termicos en la Raspberry Pi: la inferencia sostenida y altamente optimizada con ExecuTorch + XNNPACK pone mayor carga sobre la CPU, lo que lleva a aumento de temperatura y a una reduccion correspondiente de la frecuencia de reloj con el tiempo. No se uso enfriamiento activo durante estos experimentos.
Es importante notar que la delegacion de backend no ocurre por defecto. Correr ExecuTorch sin XNNPACK a menudo resultara en mayor latencia comparado con PyTorch (que tiene sus propias optimizaciones KleidiAI), aunque todavia te beneficias de una huella de runtime reducida y portabilidad mejorada.
La idea clave: ExecuTorch provee el framework de despliegue, pero la seleccion de backend determina que tan efectivamente se utiliza el hardware.
¿Como saltar de CPU a NPU con Ethos-U y TOSA?
Para ir mas lejos, podemos targetear aceleracion por hardware usando NPUs Arm Ethos-U, tipicamente emparejadas con CPUs Cortex-A o Cortex-M.
En este punto la ejecucion se vuelve heterogenea. En lugar de correr el modelo entero sobre un procesador, ExecuTorch particiona el grafo: los subgrafos soportados se delegan a la NPU, los operadores no soportados caen de vuelta a la CPU.
Ethos-U opera sobre modelos enteros cuantizados (tipicamente INT8), asi que los modelos deben ser cuantizados antes de la delegacion. El primer paso es crear un cuantizador especifico al backend usando EthosUQuantizer y un compile_spec que coincida con tu target Ethos-U especifico.
Por ejemplo, el Ethos-U targeteado aqui es un Ethos-U85 con 256 unidades multiply-accumulate (MAC):
compile_spec = EthosUCompileSpec(
target="ethos-u85-256",
system_config="Ethos_U85_SYS_DRAM_Mid",
memory_mode="Shared_Sram",
extra_flags=["--output-format=raw"],
)
quantizer = EthosUQuantizer(compile_spec)Una vez creado el cuantizador, el flujo de cuantizacion PyTorch 2 Export (PT2E) puede correrse normalmente. El siguiente paso involucra lowering del modelo a TOSA (Tensor Operator Set Architecture), una representacion intermedia disenada para tender un puente entre frameworks de alto nivel y backends de hardware. TOSA provee un conjunto de operadores estable y hardware-agnostico. En lugar de requerir que cada vendor de hardware soporte cada operador especifico de framework, los modelos se bajan a TOSA y los backends de hardware implementan este conjunto mas chico y estandarizado.
Este paso usa la API to_edge_transform_and_lower, especificando el uso de EthosUPartitioner. Para Ethos-U eso dispara el camino de backend que serializa a TOSA y corre Vela para producir un command stream optimizado para ejecucion en la NPU. Finalmente, .to_executorch(...) empaqueta el resultado a un archivo .pte.
Entender este flujo es util al analizar rendimiento. La delegacion eficiente tipicamente resulta en subgrafos grandes y contiguos corriendo en la NPU. Si hay operadores no soportados, el grafo puede volverse fragmentado, llevando a multiples subgrafos mas chicos y a mayor overhead por transiciones frecuentes entre CPU y NPU.
Para hacer esto visible, los labs utilizan el Model Explorer de Google junto con adaptadores desarrollados por Arm. Estas herramientas permiten:
- Inspeccionar el grafo ExecuTorch (
.pte) y visualizar como se particiona a traves de backends - Examinar la representacion TOSA (
.tosa) - Visualizar archivos VGF (
.vgf) usados por el Arm ML SDK para Vulkan (no cubierto en los labs)
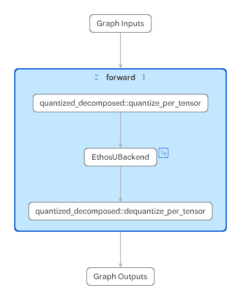
Fig 2. Model Explorer con el PTE Adapter inspeccionando archivos .pte que targetean Ethos-U para dos modelos distintos (MobileNetV2, MobileNetV2 + capa LRN)
La imagen muestra un MobileNetV2 con una capa LRN adicional insertada. Como LRN no esta nativamente soportada, se descompone en operaciones de menor nivel durante el lowering. No todas estas operaciones pueden delegarse, y el grafo se particiona en multiples segmentos. Las regiones soportadas se delegan a la NPU, mientras que la porcion no soportada corre en la CPU. En contraste, el modelo de la izquierda es MobileNetV2 regular, y contiene solo operadores soportados, permitiendo que toda la region de computo se delegue como un unico subgrafo continuo de Ethos-U.
¿Por donde seguir?
Para familiarizarse con estos temas, Arm libero una coleccion de Jupyter labs disenados para correr y modificar el codigo sobre tu propio hardware, haciendo la teoria inmediatamente accionable. El repositorio esta aca.
La coleccion incluye contribuciones del profesor Marcelo Rovai (Universidad UNIFEI, miembro del Edge AI Foundation Academia-Industry Partnership), con revisores academicos de IIIT Bangalore. Para una vision mas amplia de los recursos de Edge AI provistos por Arm, mirar el portal de developer.arm.com.



