TokenSpeed, el motor de inferencia LLM open source publicado por la fundacion LightSeek bajo licencia MIT, alcanzo un nuevo record corriendo 580 tokens por segundo sobre el modelo Qwen3.5-397B-A17B en GPU. La cifra es relevante para cargas agenticas, donde la latencia por turno suele ser el cuello de botella mas critico. El motor esta disponible en GitHub.
¿Que hace Qwen3.5 distinto de los Transformers tradicionales?
Los modelos Qwen3.5, el buque insignia de la familia open source de Qwen, adoptan un mecanismo de atencion hibrido que intercala capas de atencion completa estandar con capas de atencion lineal basadas en Gated Delta Network (GDN). A diferencia de los Transformers puros, este diseño hibrido mantiene la capacidad de modelado pero reduce drasticamente la complejidad computacional en inferencia de secuencias largas.
TokenSpeed apunta a entregar performance speed-of-light comparable a TensorRT-LLM manteniendo la usabilidad amigable de vLLM. Esta construido desde cero con arquitectura nativa SPMD y compilacion estatica, lo que acelera la ejecucion de tareas multi-paso de agentes.
Prefix cache para arquitecturas GDN/Mamba
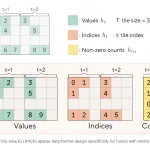
El prefix cache es critico para workloads agenticos, donde las secuencias multi-turno de tool-calling comparten contextos largos e historias de conversacion. TokenSpeed lo divide en dos capas: C++ posee el cache logico (matching de radix-tree, IDs de pagina, eviction, ciclo de vida de slots Mamba) y Python posee los tensores fisicos (paginas KV en GPU, conv_state y ssm_state de Mamba, ordenamiento de streams, copy-on-write).
Para el KV cache normal, un prefix hit significa reutilizar los IDs de pagina cacheados. Para Mamba no basta: un prefix reutilizable tambien debe llevar el estado recurrente al mismo limite de prefijo. TokenSpeed resuelve esto adjuntando un MambaSlot al mismo nodo del radix-tree que representa el prefijo KV cacheado.
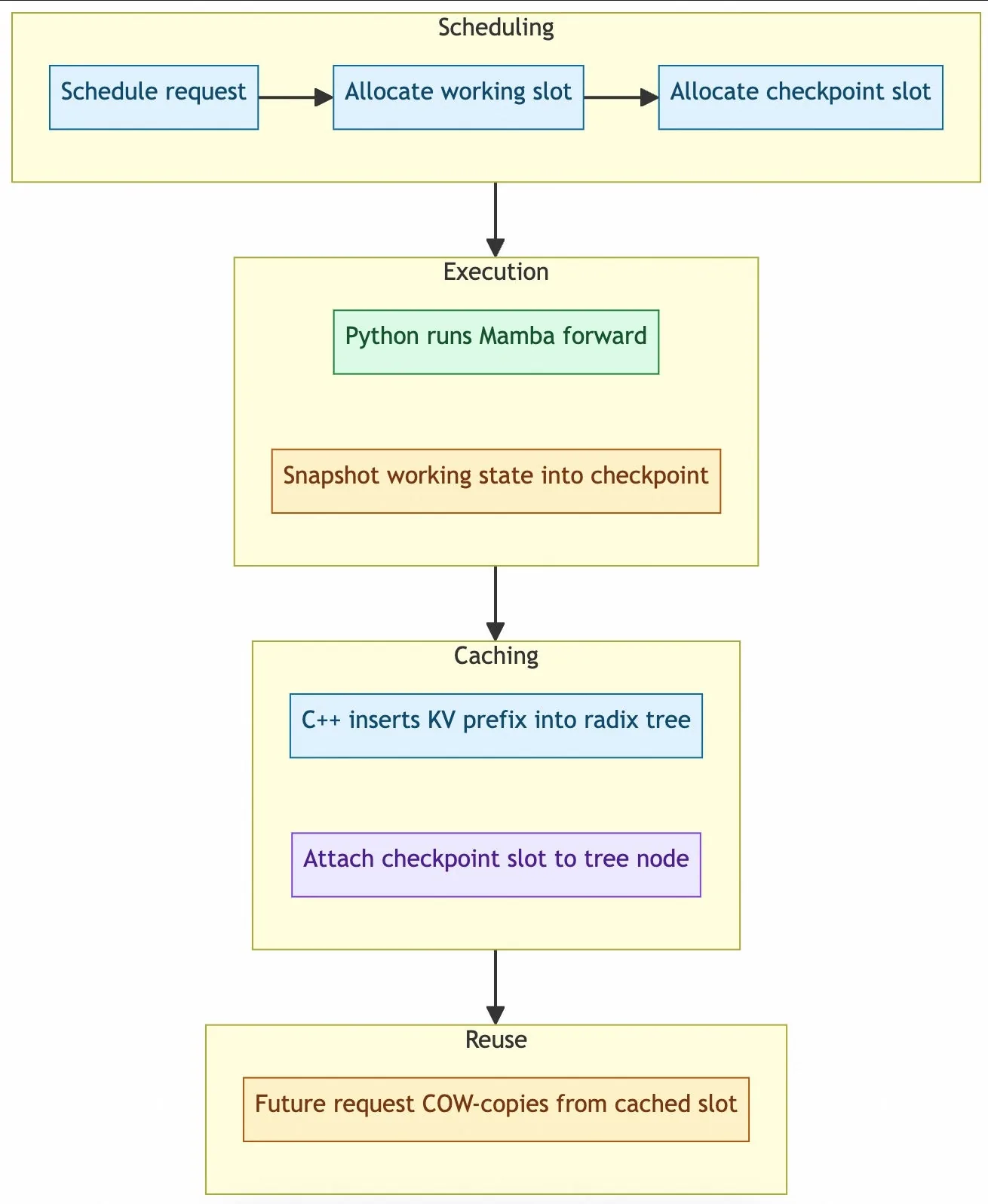
Ciclo de vida de slots
Cada request activa de Mamba puede mantener dos tipos de slot:
workingslot: estado mutable usado por el paso forward actual.checkpointslot: destino del snapshot que despues puede publicarse en el arbol de prefijos.
El scheduler asigna estos slots en C++, pero Python escribe el contenido tensor real. Un checkpoint slot se vuelve reutilizable solo cuando Python lo poblo con estado limpio y C++ lo adjunto a un nodo del radix-tree alineado a bloque.
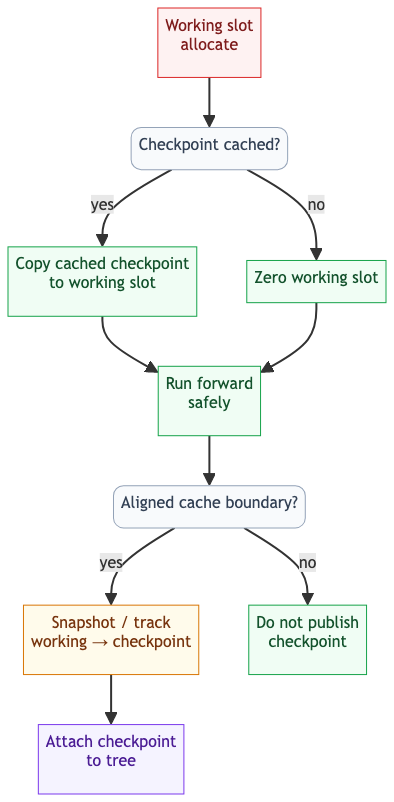
Riesgo de correctitud: estado obsoleto
El principal riesgo es data obsoleta en slots reutilizados. El MambaChunkAllocator entrega IDs de slot enteros sin limpiar la memoria GPU. TokenSpeed garantiza que un slot working nuevo es seguro de exactamente dos maneras: o recibe copy-on-write desde un checkpoint conocido como limpio, o Python lo zerea explicitamente antes de uso.
Scheduler dual: KV Cache y Mamba State
La arquitectura hibrida impone requisitos unicos al scheduler: debe gestionar simultaneamente KV Cache (capas de atencion completa) y Mamba State (capas de atencion lineal) como dos pools de recursos separados. Los mecanismos clave son:
- Gestion dual de pools: cada request mantiene tanto indices de bloques KV Cache como indices de slots de pool Mamba (
mamba_pool_indices). - Ciclo de vida de estado: al llegar la request se asigna slot mamba_pool; durante prefill se puebla el estado inicial o se carga del prefix cache; durante decode se actualiza en sitio cada paso; al completarse o preempt se libera el slot.
- Soporte de decoding especulativo: el scheduler mantiene un cache de estado intermedio (
spec_cache) con snapshots Conv/SSM por paso especulativo, permitiendo rollback si la verificacion falla. - Ruteo por capa:
HybridLinearAttnBackendrutea las llamadas forward al backend apropiado segun ellayer_id.
Disaggregacion Prefill-Decode: dos mundos, un cable
Para modelos hibridos, las capas Mamba mantienen tensores de estado mas alla de los pares clave-valor convencionales. Estos estados deben transferirse desde los nodos de prefill a los nodos de decode junto con los KV caches, lo que exige alineamiento correcto capa por capa entre capas full-attention y Mamba.
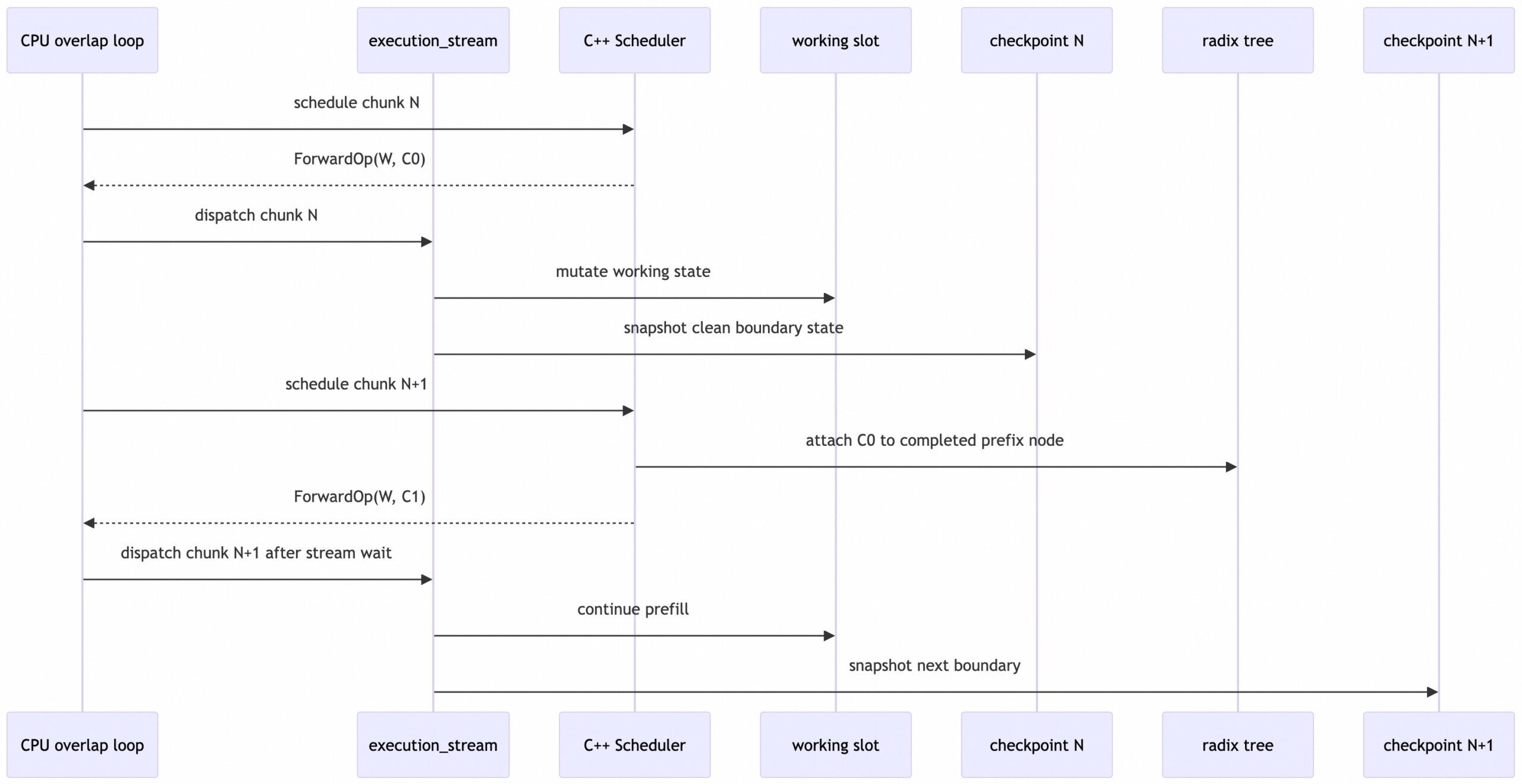
TokenSpeed introdujo tres piezas para esto:
1. Transferencia unificada de estado: el sistema mapea los indices de slot de cada request a offsets fisicos en bytes, agrupa slots contiguos en bloques scatter-gather, y los emite como escrituras RDMA bulk. Desde la red, los estados Mamba son simplemente otro conjunto de regiones de memoria: sin serializacion, sin staging intermedio.
2. Scheduling cross-layer con heartbeat unificado: en modo layerwise transfer, el nodo de prefill empieza a enviar datos no bien cada grupo de capas termina, solapando computacion con comunicacion. El contador de pasos unificado se incrementa una vez por capa forward (sin importar el tipo).
3. Three-phase handshake: en un sistema desagregado el nodo prefill no solo produce estados, tambien produce el primer token de salida. El nodo decode necesita ambos antes de poder generar.
Tabla comparativa: motores de inferencia hibridos
| Motor | Licencia | Mamba/GDN | Pico declarado |
|---|---|---|---|
| TokenSpeed | MIT | Si | 580 tps (Qwen3.5-397B-A17B) |
| vLLM | Apache 2.0 | Parcial | ~280 tps modelos similares |
| TensorRT-LLM | NVIDIA EULA | Si | Cercano a SOL |
| SGLang | Apache 2.0 | En desarrollo | ~350 tps |
¿Que significa esto para integradores LatAm?
Para equipos chilenos que sirven modelos grandes desde GPU rentadas en proveedores cloud, 580 tps significa que un solo nodo H200 puede atender el throughput que antes requeria dos o tres. En workloads agenticos con tool-calling intensivo, donde una conversacion puede involucrar 20-30 llamadas a herramientas, el prefix cache hibrido reduce el costo por sesion en factores de 5x a 10x. El motor esta bajo licencia MIT, sin restricciones comerciales, y se distribuye desde el blog tecnico de LightSeek.