
Google DeepMind liberó Gemini 3.5 Flash, la nueva versión de su familia Flash que históricamente se posicionó como la alternativa rápida y económica frente a los modelos Pro. El upgrade es real en velocidad e inteligencia, pero llega con un costo de operación 5,5 veces mayor que el predecesor en pruebas de Artificial Analysis, según un análisis con acceso anticipado al modelo.
La ventana de contexto se mantiene en 1 millón de tokens. Lo que cambió radicalmente es el precio por token y, sobre todo, cuántos tokens necesita el modelo para resolver una tarea.
¿Cuánto cuesta realmente Gemini 3.5 Flash?
El precio por token se triplicó. Google ahora cobra USD 1,50 por millón de tokens de entrada y USD 9,00 por millón de tokens de salida, frente a los USD 0,50 y USD 3,00 que costaba Gemini 3 Flash. Por token, sigue siendo más barato que Gemini 3.1 Pro (USD 2,00 y USD 12,00).
El problema aparece en la práctica. En tareas de agentes, Gemini 3.5 Flash consume tantos tokens adicionales que el costo total termina 75% más alto que el del propio Gemini 3.1 Pro, de acuerdo con la firma Artificial Analysis.
Google no está solo en esta movida. Anthropic subió de forma encubierta entre 30% y 40% el costo efectivo de Opus 4.7 sobre su predecesor por mayor consumo de tokens. OpenAI fue más lejos con GPT-5.5: el salto fue de 50% a 90% sobre 5.4, en su caso porque subió el precio base aunque el consumo bajó. Google subió ambas variables al mismo tiempo.
Para los desarrolladores, el precio bruto por token está dejando de ser una métrica útil aislada. Lo que importa hoy es la eficiencia: cuántos tokens necesita un modelo para terminar el trabajo.
¿Es más inteligente que Gemini 3 Flash?
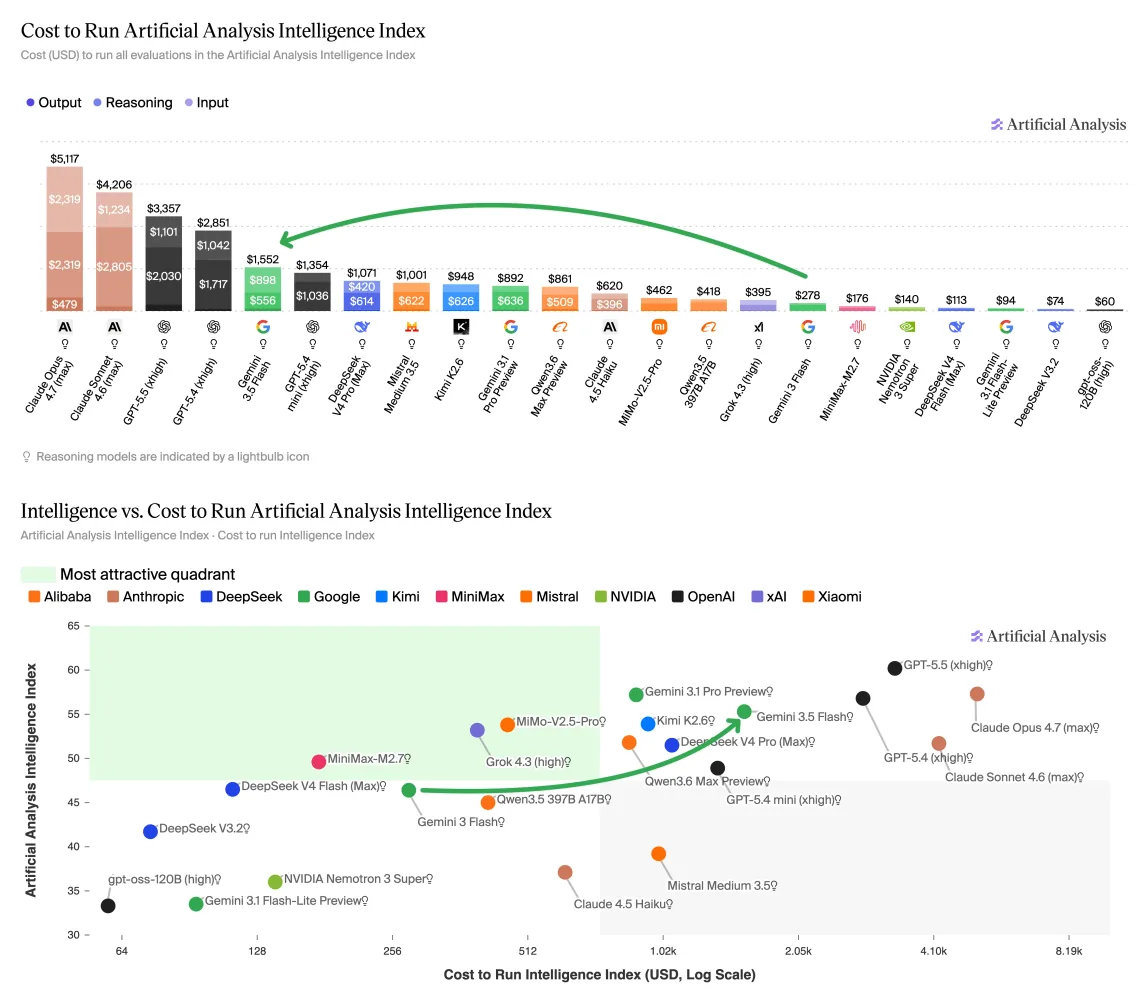
En el Artificial Analysis Intelligence Index, Gemini 3.5 Flash anota 55 puntos, nueve más que el modelo anterior. Lo deja por delante de Grok 4.3 high (53) y Claude Sonnet 4.6 max (52). Las mejoras aparecen en casi todas las categorías evaluadas, aunque como siempre los benchmarks capturan escenarios específicos y el desempeño real solo se ve con uso prolongado en tareas cotidianas.
En AA Omniscience, que mide precisión de conocimiento y tendencia a alucinar, el modelo mejora 11 puntos. La tasa de alucinación cae al 61%, 31 puntos porcentuales menos que Gemini 3 Flash. Suena impresionante hasta que se mira a los líderes: MiMo-V2.5-Pro y Grok 4.3 high están en apenas 25%. Gemini 3.5 Flash recorta diferencias, pero sigue lejos del podio.
¿Por qué gasta tantos tokens en agentes?
Las tareas agénticas fueron históricamente el punto débil de Gemini, y es justamente donde 3.5 Flash más mejora. En GDPval-AA, que mide tareas reales con acceso a web y shell, alcanzó un Elo de 1.656, un salto enorme sobre Gemini 3 Flash (1.204) y Gemini 3.1 Pro (1.314). Queda apenas por debajo de GPT-5.4 xhigh (1.674).
Ese rendimiento se paga caro. Gemini 3.5 Flash necesita en promedio 49 turnos por tarea, más que cualquier otro modelo evaluado. Claude Opus 4.7 max usa 45, GPT-5.4 xhigh 40, y Gemini 3.1 Pro solo 23. Todos esos pasos extra disparan el consumo de tokens de entrada.
El consumo de tokens de salida cambió poco: 73 millones contra 72 millones de Gemini 3 Flash. Los responsables del costo total son los tokens de entrada, que empujan al Flash por encima del Pro en cuenta final pese a tener precio unitario más bajo.
Programación: el flanco más débil
La programación es donde se piden modelos rápidos, capaces y baratos, y donde Gemini 3.5 Flash se queda corto. En el Artificial Analysis Coding Index, que combina Terminal-Bench Hard y SciCode, anota apenas 45 puntos. Lejos de Gemini 3.1 Pro Preview (55), más lejos aún de GPT-5.5 xhigh (59) y GPT-5.4 xhigh (57). También lo superan Claude Opus 4.7 max (53) y Claude Sonnet 4.5 max (51).
Para un modelo que iguala a esos rivales en el índice general de inteligencia, la brecha es notable. Las fortalezas están claramente en lo agéntico y multimodal, pero coding es uno de los casos de uso más importantes de la IA agéntica, lo que limita el valor práctico de esas mejoras.
La ventaja real: velocidad y multimodalidad
Gemini 3.5 Flash supera los 280 tokens de salida por segundo, alrededor de un 70% más rápido que Gemini 3 Flash. Ningún otro modelo con inteligencia similar se acerca a esa tasa de salida.
A diferencia de muchos rivales, soporta también entrada de video y audio, además de texto e imágenes. Claude Opus 4.7, Grok 4.3 y GPT-5.5 están limitados a entrada de imagen, según Artificial Analysis. En el benchmark multimodal MMMU-Pro, Gemini 3.5 Flash anota 84%, el resultado más alto registrado hasta la fecha. Google se queda con los dos primeros puestos: Gemini 3.1 Pro es segundo con 82%.
El nuevo cálculo de ROI
El alza de precios refleja un cambio más profundo. Los modelos actuales están pensados para tareas complejas y multi-paso donde planifican solos, usan herramientas e iteran. Ese comportamiento agéntico requiere mucho más cómputo por tarea que un chatbot simple.
A menos que el costo de inferencia del hardware caiga al mismo ritmo que sube el cómputo por tarea, los precios de los modelos más fuertes van a seguir trepando. Para casos simples seguirán existiendo modelos viejos más baratos u opciones pequeñas como Gemini 3.1 Flash-Lite.
Para las empresas, el retorno de inversión en IA se vuelve más difícil de medir. Tareas aisladas como generación de código o traducción se evalúan con tiempos de entrega y costos de dotación, pero el trabajo de conocimiento es más nebuloso. ¿Cómo se pone número a un mejor informe estratégico o una decisión terminada en la mitad del tiempo? ¿Y qué pasa con los costos posteriores: el tiempo dedicado a revisar errores o el aprendizaje que no ocurre cuando la IA hace el trabajo?
Esas ganancias de productividad tienden a diluirse entre departamentos, aparecen tarde y son difíciles de separar de otros factores. Pagar por modelos más caros es una apuesta a que las ganancias de eficiencia compensen y a que el trabajo asistido por IA sea la nueva normalidad.



