Sabemos que Claude Code es fenomenal para desarrollo y programacion. Pero podemos quedarnos sin tokens con facilidad, y la cuenta se vuelve cara rapidamente a medida que el proyecto se complejiza. ¿Que pasaria si pudieramos quedarnos con todo lo bueno de Claude Code, pero usando modelos locales en vez del cloud de Anthropic?
Otra razon para querer modelos locales es tener algo propietario o privado que no queremos exponer a los modelos cloud, o trabajar en un vuelo sin conexion a internet.
Aqui es donde Docker Model Runner es realmente util: nos permite correr LLMs muy facil de forma local en nuestra maquina, y despues hacemos un poco de configuracion para que funcione con Claude Code.
¿Que necesitas antes de empezar?

Antes de comenzar, asegurate de tener:
- Docker Desktop o Docker Engine instalado.
- Docker Model Runner habilitado.
- Claude Code instalado y listo.
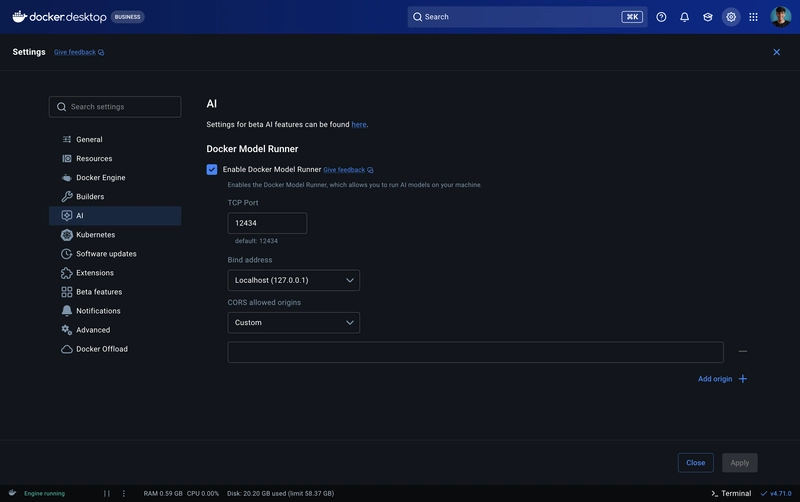
Si estas en Docker Desktop, anda a Settings > AI y habilita el acceso TCP para Model Runner.
O, si preferis la terminal:
docker desktop enable model-runner --tcp 12434Paso 1: Elegir y descargar un modelo local

Hay un monton de LLMs para elegir. En este ejemplo se va con ai/phi4:14B-Q4_K_M, pero podes elegir el que mejor le caiga a tu maquina. Podes encontrar todos los modelos en el catalogo de Docker Hub AI. Asegurate de que el modelo que elijas sea bueno en el lado de codigo.
Para descargar el modelo, ejecuta el comando:
docker model pull ai/phi4:14B-Q4_K_MEl tiempo de descarga depende del tamano del modelo.
Paso 2: Chequear la conexion
Con los subcomandos docker model podemos chequear varias cosas: estado del runner y modelos que tenemos descargados. Es muy similar a como trabajamos con imagenes y contenedores Docker.
docker model status
docker model lsPaso 3: Probar el endpoint
Antes de saltar a Claude Code, conviene confirmar que la API esta respondiendo. Podemos usar curl contra el endpoint /v1/messages:
curl http://localhost:12434/v1/messages \
-H "Content-Type: application/json" \
-d '{
"model": "ai/phi4:14B-Q4_K_M",
"max_tokens": 100,
"messages": [{"role": "user", "content": "Hello!"}]
}'La respuesta del modelo confirma que el endpoint local esta arriba. Para mejor formato de salida se sugiere usar jq.
Paso 4: Apuntar Claude Code al endpoint local
Es muy simple. Solo necesitamos decirle a Claude Code que use la API local en vez de la de Anthropic. Lo hacemos con una variable de entorno y el nombre del modelo.
Setea la variable de entorno ANTHROPIC_BASE_URL apuntando al endpoint de Docker Model Runner, y pasa el nombre del modelo con --model:
ANTHROPIC_BASE_URL=http://localhost:12434 claude --model ai/devstral-small-2Listo. Claude Code esta ahora apuntando y corriendo contra tu modelo local. Tambien vas a ver el modelo en uso desde la propia interfaz de Claude Code.
Paso 5: Hacerlo persistente con shell config
Como sabemos, la variable de entorno ANTHROPIC_BASE_URL no es persistente y solo vive durante la sesion actual de terminal. Setearla cada vez es molesto. Para hacerla permanente, agregamos la siguiente linea a la config del shell (~/.zshrc, ~/.bashrc, etc.):
export ANTHROPIC_BASE_URL=http://localhost:12434Despues de eso, reinicia la terminal y Claude Code usara siempre el endpoint local cuando le pases --model.
Paso 6: Usar Claude Code y ver el flujo
Para correr con el modelo local pasamos la misma flag de modelo:
claude --model ai/phi4:14B-Q4_K_MSi querias mirar bajo el capot, podes ver cada request que Claude Code envia al modelo local con:
docker model requests --model ai/phi4:14B-Q4_K_MNuevamente, jq ayuda al formato.
¿Y si necesito mas contexto?
El tamano de contexto por defecto en la mayoria de los modelos esta bien para tareas chicas, pero Claude Code lee muchos archivos. Para trabajo en proyectos grandes vas a querer mas headroom y un contexto mayor.
Por ejemplo, para empaquetar gpt-oss con una ventana de 32K tokens:
docker model pull ai/gpt-oss
docker model package --from ai/gpt-oss --context-size 32000 gpt-oss:32kLuego corres Claude Code con la nueva variante:
claude --model gpt-oss:32kY este es el juego: seguir probando y experimentando con distintos modelos y tamanos de contexto hasta encontrar el ideal para cada tarea.