Investigadores del Allen Institute for AI (Ai2) y de UC Berkeley presentaron EMO, un modelo mixture-of-experts (MoE) que desarrolla estructuras modulares durante el preentrenamiento. La novedad: el modelo puede reducirse a una fracción mínima de sus expertos sin caída relevante de rendimiento.
Las arquitecturas MoE son hoy estándar en familias como DeepSeek-V4 o Qwen3.5. Solo activan un puñado de expertos por token, lo que permite escalar a cientos de miles de millones de parámetros sin disparar los costos de cómputo. El problema, hasta ahora, es que el modelo completo igual tenía que residir en memoria: tokens distintos dentro de la misma tarea recurren a expertos distintos, así que no se puede cargar solo un "slice" del modelo para resolver, por ejemplo, una tarea matemática o de programación.
Según el paper publicado, eso ocurre porque los expertos de los MoE estándar tienden a quedarse con patrones gramaticales superficiales: responden a preposiciones, puntuación o artículos, no a dominios de alto nivel como matemáticas o código. Eso vuelve imposible recortar un subconjunto útil.
¿Cómo entrena EMO la modularidad?
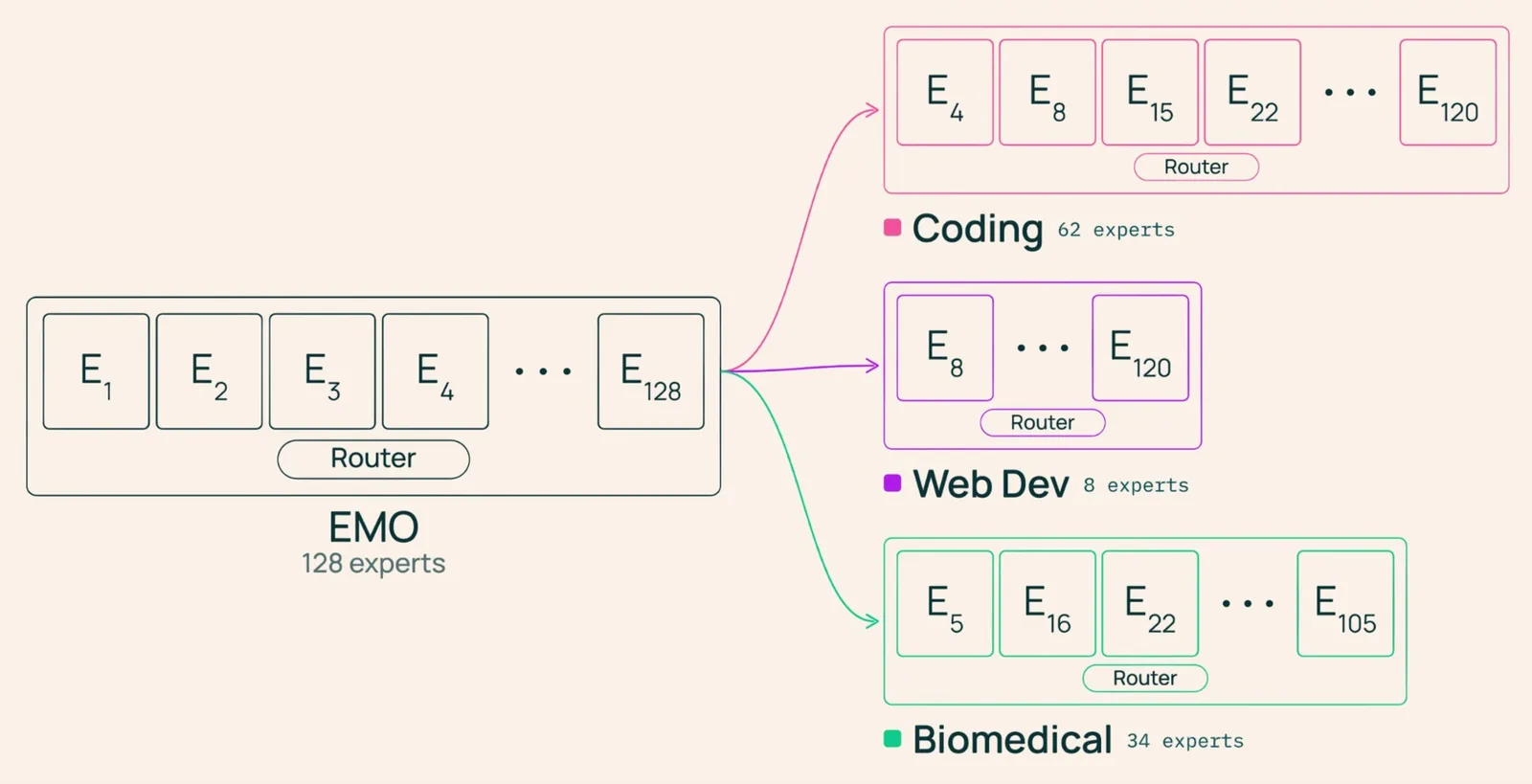
EMO ataca el problema con un truco simple. En lugar de ordenar la data de entrenamiento en dominios fijos (matemáticas, biología) antes del training, al estilo de proyectos como BTX o el propio FlexOlmo de Ai2, los autores usan los límites del documento como señal. Los tokens dentro de un mismo documento suelen pertenecer al mismo dominio.
EMO obliga a todos los tokens de un documento a elegir sus expertos activos desde un pool compartido. El modelo decide qué expertos forman ese pool promediando las preferencias del router entre todos los tokens del documento y quedándose con los más seleccionados.
Para que el entrenamiento se mantenga estable hicieron falta dos ajustes. Primero, los autores dejaron de calcular el load balancing (que busca repartir la carga de manera uniforme entre expertos) de forma local por batch de entrenamiento, y lo computan ahora globalmente entre muchos documentos. Si no lo hacían, los dos objetivos de entrenamiento peleaban entre sí: uno agrupa tokens dentro de un documento, el otro los dispersa entre tantos expertos como sea posible.
Segundo, los investigadores varían aleatoriamente el tamaño del pool de documentos durante el entrenamiento, en vez de fijarlo. Eso le enseña al modelo a operar con subgrupos de expertos de distintos tamaños al momento de inferencia.
¿Cuánto se puede recortar sin perder rendimiento?
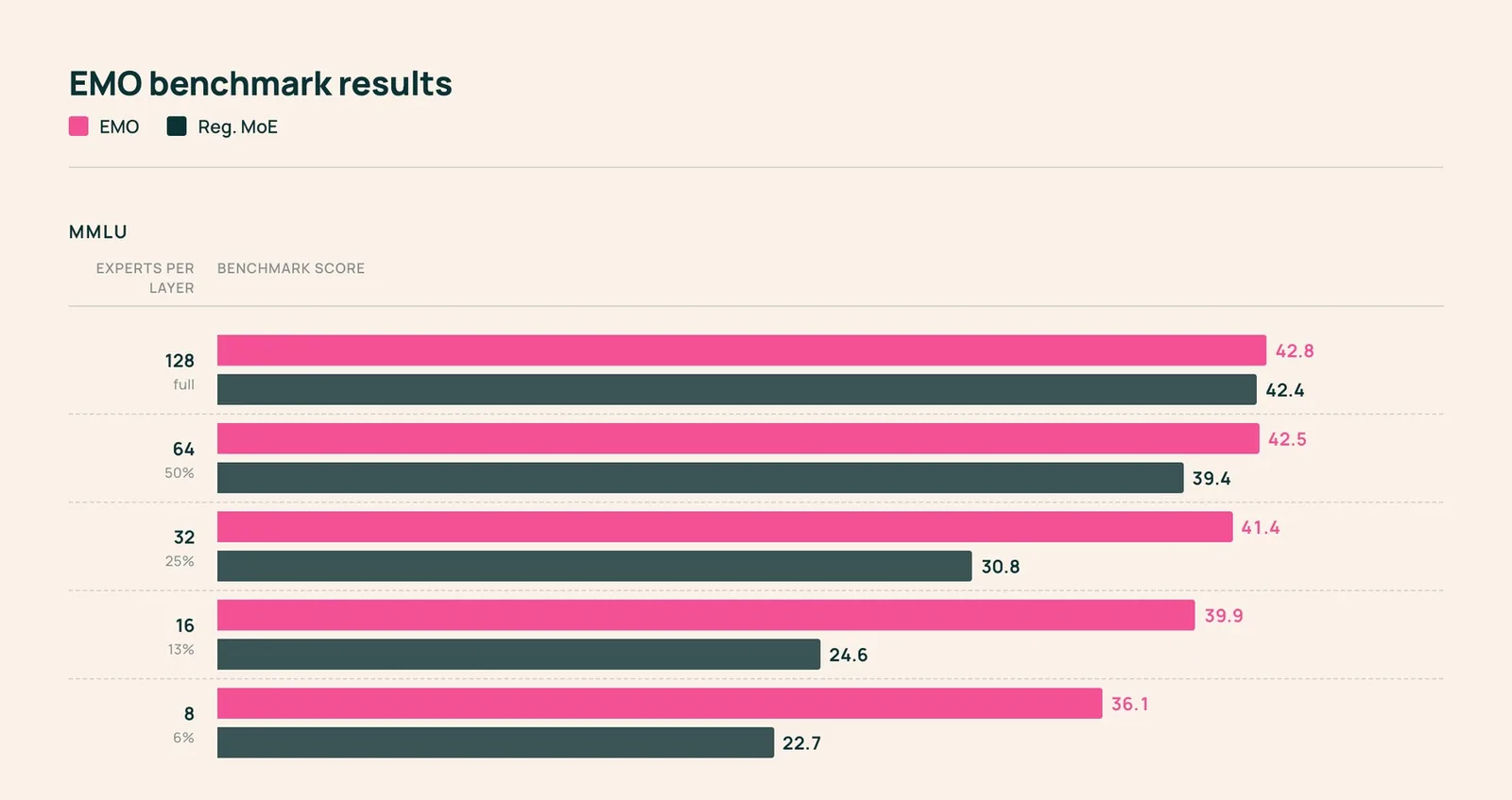
El equipo entrenó un MoE con 1.000 millones de parámetros activos y 14.000 millones totales, con 128 expertos (ocho activos por token) sobre 1 billón de tokens del corpus de preentrenamiento OLMoE. Como modelo completo, EMO iguala a un MoE estándar entrenado con la misma configuración. Los autores afirman que supera a OLMoE pese a usar cinco veces más datos.
Luego empezaron a quitar expertos para ver hasta dónde se podía llegar:
- Con solo el 25% de los expertos activos (32 de 128), EMO pierde aproximadamente un punto porcentual absoluto de rendimiento, promediado sobre varios benchmarks.
- Con el 12,5% (16 expertos), la caída ronda los tres puntos.
- Un MoE estándar colapsa en el mismo escenario, perdiendo entre 10 y 15 puntos porcentuales y, en algunos casos, quedando por debajo del nivel de un modelo denso con la misma cantidad de parámetros activos.
En el benchmark de matemáticas GSM8K, los subconjuntos con apenas 12,5% de los expertos recuperan rendimiento de modelo completo tras un fine-tuning. El MoE estándar, en cambio, cae a 4,9 puntos con la mitad de los expertos y se hunde por debajo del azar en el escenario más pequeño.
Encontrar los expertos correctos no requiere mucha data, según los autores: basta un ejemplo few-shot para seleccionar un subgrupo comparable al elegido sobre un dataset de validación completo. EMO funciona con selección simple basada en el router y con el método más especializado Easy-EP.
¿Qué aprenden los expertos: tópicos, no puntuación?
Para entender qué aprendió EMO, los investigadores analizaron cómo el modelo distribuye los tokens entre expertos por dentro. Para cada token registraron la probabilidad con que el router lo envía a cada experto. Esos patrones funcionan como una "huella digital" por token, y agrupándolos por similitud aparecen clusters.
La diferencia es contundente: en un MoE estándar los clusters de expertos corresponden a categorías lingüísticas superficiales (preposiciones, nombres propios, artículos definidos). Los de EMO, en cambio, mapean a tópicos reales: salud, medicina y bienestar, política y elecciones de EE.UU., reseñas de cine, música, TV y libros. Los tokens de un mismo documento convergen en un único cluster en EMO, mientras que en un MoE estándar se reparten entre muchos.
Sobre una muestra de 20 millones de documentos del dataset WebOrganizer, con 24 etiquetas de dominio asignadas por humanos, los autores verificaron que dominios relacionados activan expertos parecidos. En EMO los patrones se separan limpiamente, sobre todo en las capas más profundas; en el MoE estándar se solapan más.
Más allá del ahorro de memoria
La aplicación más obvia es correr modelos en entornos con poca memoria, cargando solo los expertos relevantes para el dominio. En una comparación directa, los subgrupos de expertos de EMO igualan o superan tanto a un MoE estándar de 32 expertos como a un modelo denso con ocho parámetros activos, ambos entrenados desde cero.
Los investigadores también plantean usos de fine-tuning en tiempo de ejecución. Una app para niños, por ejemplo, podría apagar los clusters que responden a spam, juego o contenido adulto. En un test inicial, los autores reentrenaron un subgrupo de 32 expertos de EMO y lo reinsertaron en el modelo de 128: eso mejoró al modelo completo, aunque sin alcanzar el nivel del subgrupo standalone. EMO también podría ayudar al monitoreo, porque los expertos hacen visible qué partes del modelo está usando un input dado.
Ai2 está liberando el modelo EMO, una baseline de MoE estándar comparable y el código de entrenamiento en Hugging Face y GitHub. Los investigadores también publicaron una demo interactiva de las activaciones de tokens. Quedan preguntas abiertas: cómo seleccionar y combinar mejor los subgrupos de expertos, cómo reentrenar módulos individuales para tareas específicas, y cómo aprovechar la estructura modular para hacer los modelos más interpretables.