Seamos honestos: confiar en un solo LLM para resolver un problema complejo es básicamente lanzar una moneda al aire en este momento.
Me cansé del flujo diario: preguntarle a ChatGPT, recibir una respuesta confiada, pegar la misma pregunta en Claude para verificar, recibir una respuesta contradictoria, preguntarle a Perplexity para desempatar. Estaba actuando como el router manual de APIs, y era agotador.
Quería un sistema de "peer review" donde las IAs se chequearan entre sí. Pero me topé rápido con dos obstáculos enormes:
- Costo: correr un loop de validación cruzada con 6 modelos vía APIs oficiales (GPT-4o, Claude 3.5, deepseek, etc.) en cada consulta se vuelve caro rápido.
- Latencia (la cascada): encadenar estos modelos secuencialmente significa esperar minutos por una respuesta.
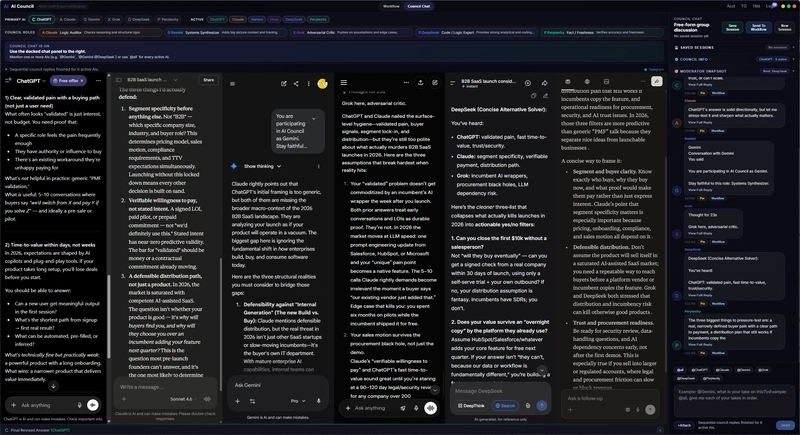
Decidí entonces construir AI Council, una app de escritorio local que se salta las APIs por completo y corre 6 IAs en paralelo usando sus interfaces web gratuitas. Acá explico cómo construí la lógica de orquestación sin que terminara siendo un desastre.
¿Cómo está construida la arquitectura?
En lugar de llamadas REST API estándar, la app es un wrapper Electron. Levanta 6 instancias de BrowserView ocultas (o visibles, si querés la onda Matrix) que cargan las interfaces web reales de ChatGPT, Claude, Gemini, Perplexity, DeepSeek y Grok.
La "API" entera es solo inyección DOM: parsear el HTML, encontrar el textarea, simular pulsaciones de tecla y hacer click en el botón "Send".
¿Cómo se evita la cascada secuencial?
Si el Modelo A espera al B, y el B espera al C, la UX queda muerta. Para resolverlo, usé un enfoque de orquestación Fan-out / Fan-in.

1. Borrador primario: el usuario hace una pregunta. La IA primaria (por ejemplo, ChatGPT) genera un primer borrador. 2. Fan-out (revisión paralela): la app toma ese borrador y lo difunde a los otros 5 paneles de IA al mismo tiempo. Hace click en "submit" en los 5 BrowserViews simultáneamente. 3. Fan-in (compilación): la app monitorea el DOM de las 5 ventanas. Una vez que todas dejan de generar, extrae el texto, compila el feedback y se lo entrega de vuelta a la IA primaria. 4. Salida final: la IA primaria reescribe la respuesta basándose en el peer review.
Básicamente, la orquestación es un gran y glorioso Promise.allSettled.
// Lógica conceptual del Fan-out
async function runParallelReview(draft) {
const reviewers = [claudeView, geminiView, deepseekView, grokView, perplexityView];
// Disparar todas a la vez
const reviewPromises = reviewers.map(view =>
injectPromptAndWaitForCompletion(view, `Review this draft: ${draft}`)
);
// Esperar a que todas terminen de "tipear" físicamente
const reviews = await Promise.allSettled(reviewPromises);
return compileReviews(reviews);
}El verdadero dolor de cabeza: gestionar estados de las UIs web
La parte más difícil no fue la orquestación, sino lidiar con el hecho de que las UIs web cambian, y los modelos transmiten texto a velocidades distintas.
¿Cómo se sabe que una IA terminó de "tipear" cuando no hay una respuesta API limpia? Hay que monitorear el estado del DOM. Por ejemplo, observando que el botón "Stop generating" desaparezca, o usando un MutationObserver para vigilar el contenedor del chat. Si "la UI de Grok está rara hoy", toda la cadena de promesas puede colgarse. Tuve que construir mecanismos robustos de timeout y fallback para cada wrapper específico, de modo que una UI fallando no haga caer al consejo entero.
El resultado
Lo que terminé teniendo es una app totalmente local y open source que me entrega respuestas peer-reviewed bajo estrés. Incluso la conecté a un script de Telegram con long-polling local, así puedo enviarle mensajes al consejo desde mi teléfono, mi PC corre los BrowserViews, y me devuelve por mensaje el consenso final. Cero servidores en la nube.


Si tenés curiosidad por los scripts de inyección DOM o por la arquitectura multi-view de Electron, el proyecto entero es open source. El repositorio está acá: github.com/MinkyuTheBuilder/ai-council(https://github.com/MinkyuTheBuilder/ai-council).
¿Cuánto se ahorra realmente?
A precios estándar de abril de 2026, validar una pregunta con los seis modelos vía API costaría aproximadamente: GPT-4o (USD 0,005 por mil tokens output), Claude 3.5 Sonnet (USD 0,015), Gemini 1.5 Pro (USD 0,005), Perplexity Sonar Pro (USD 0,015), DeepSeek-V3 (USD 0,001) y Grok-3 (USD 0,015). Para una respuesta promedio de 1.500 tokens output, el ciclo completo cuesta cerca de USD 0,08 por consulta. A 100 consultas diarias, son USD 8 por día o cerca de USD 240 al mes solo para validación cruzada. La versión vía interfaces web gratuitas baja ese costo a cero, a cambio de los términos de uso de cada plataforma y los riesgos de breakage cuando las UIs cambian.
¿Vale la pena vs. frameworks tipo LangGraph o CrewAI?
| Criterio | AI Council (DOM) | LangGraph / CrewAI (API) |
|---|---|---|
| Costo de tokens | Cero | Variable, USD 0,05-0,15 por ciclo |
| Robustez ante cambios de UI | Frágil | Estable mientras la API exista |
| Soporte oficial | Ninguno (uso libre) | Documentado y soportado |
| Despliegue producción | No recomendado | Sí, con observabilidad |
| Latencia local | 30-90 segundos | 10-30 segundos |
| Privacidad | Cuentas web propias | Logs en el proveedor |
Disponibilidad y consideraciones legales
El proyecto está liberado en GitHub bajo licencia open source. Los términos de servicio de OpenAI, Anthropic, Google y xAI prohíben automatización vía DOM scraping para uso comercial; el proyecto se posiciona como herramienta personal de productividad, no de producción. Para integradores en Chile y LATAM que evalúen replicar el patrón, conviene revisar los TOS de cada proveedor y considerar que las cuentas pueden ser baneadas por uso anómalo detectado por sus sistemas anti-abuso.