
Mayo dejó al ecosistema de modelos abiertos en modo bonanza. Casi todos los laboratorios open frontier publicaron actualizaciones: Google con Gemma 4, DeepSeek con su largamente esperado DeepSeek-V4, Moonshot AI con Kimi K2.6, Xiaomi con MiMo V2.5 Pro y Z.ai con GLM-5.1.
El lanzamiento de DeepSeek V4 gatilló además una evaluación del Center for AI Standards and Innovation (CAISI), que ya había revisado modelos abiertos en el pasado. Su conclusión es polémica: los modelos open quedan rezagados frente a la frontera estadounidense, con una brecha que se ensancha en el tiempo.
¿Qué dice el CAISI y por qué Interconnects lo discute?
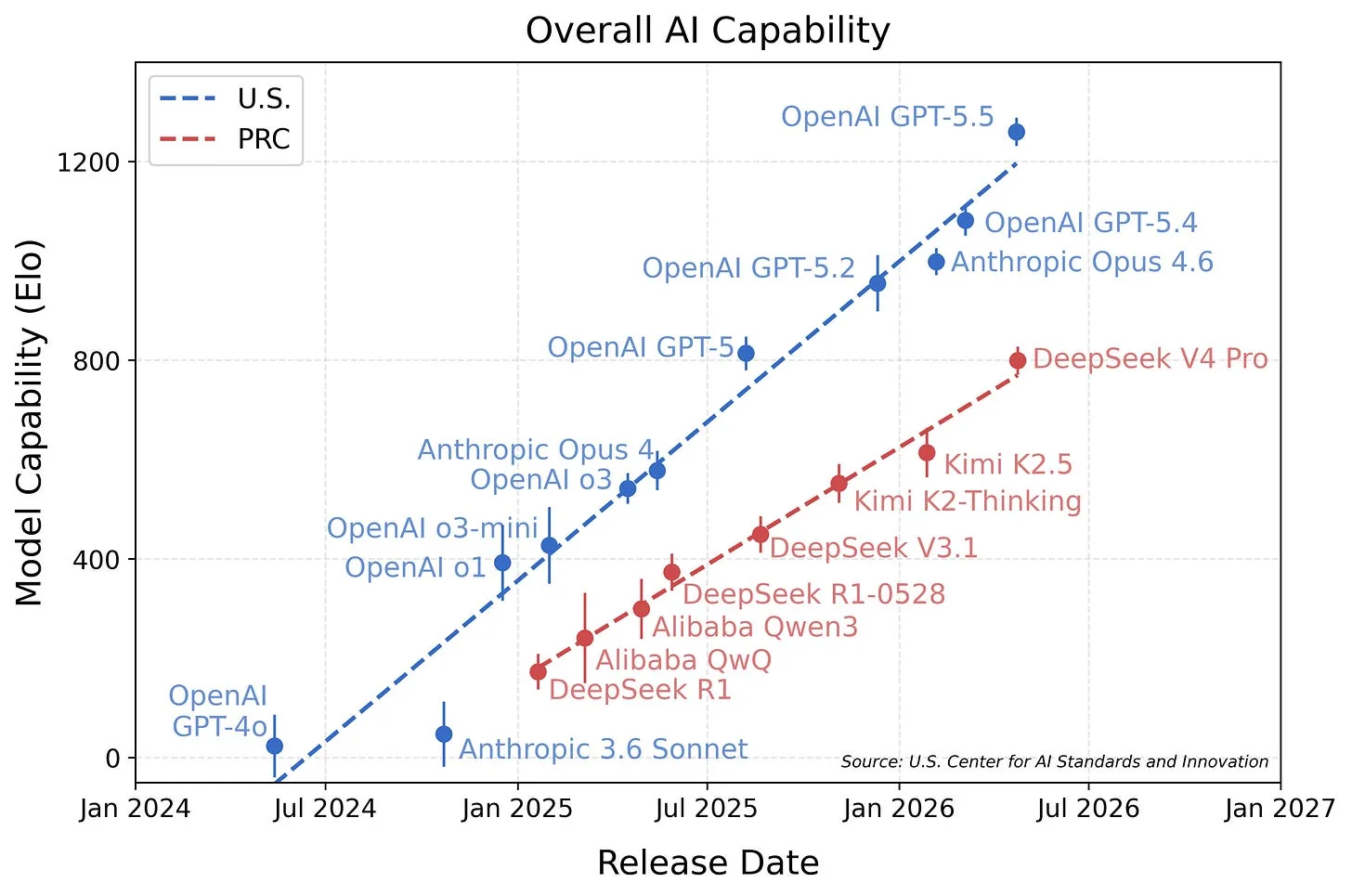
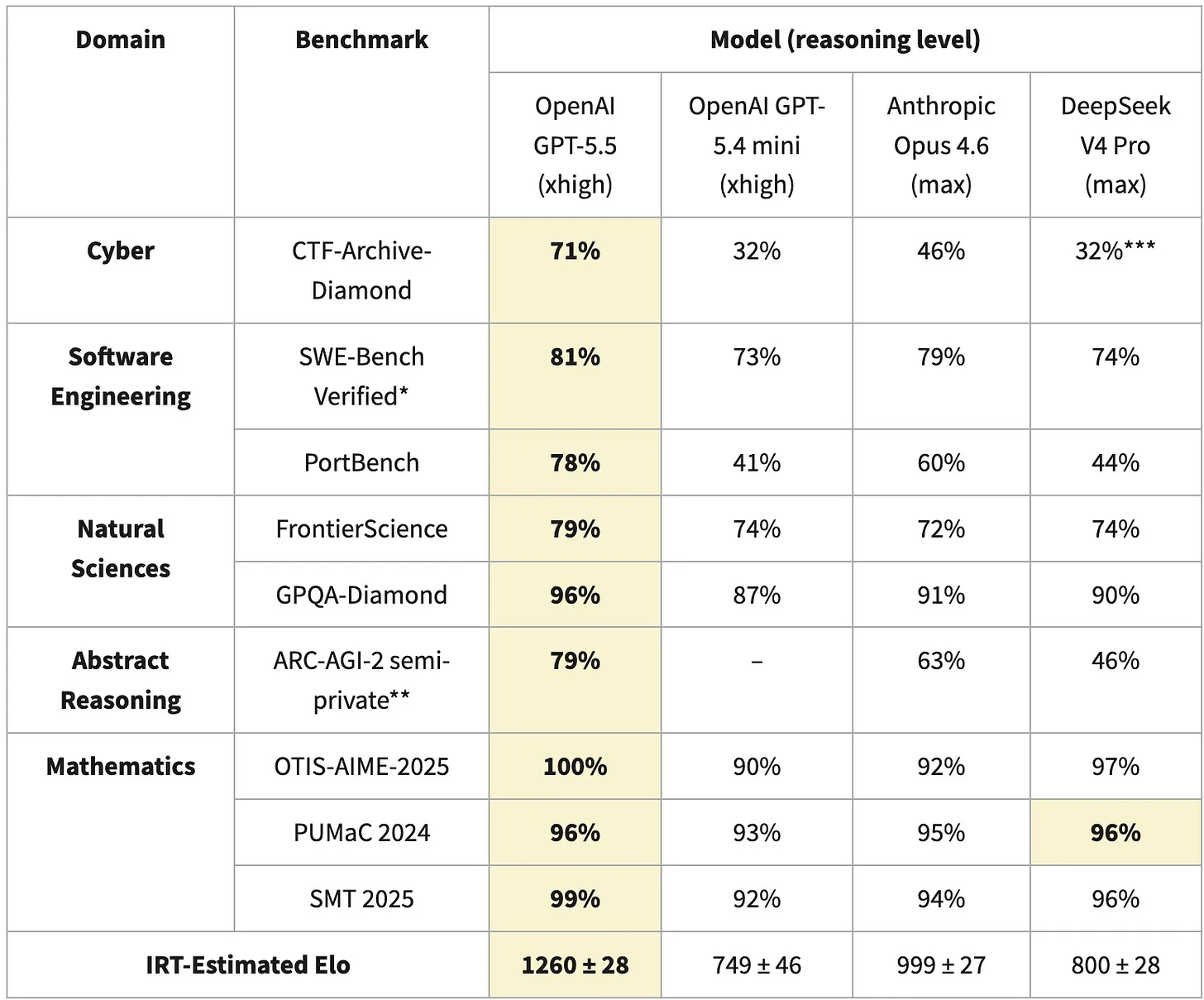
Para llegar a ese veredicto, el CAISI calculó un Elo score basado en Item Response Theory, un método estándar que permite comparar modelos evaluados sobre baterías distintas. En el caso de V4 usaron nueve benchmarks, pero la diferencia tan grande del Elo final se explica casi por completo por el mal rendimiento de DeepSeek V4 en tres pruebas puntuales: CTF-Archive-Diamond (corrida sobre un subset y extrapolada con IRT), PortBench (un benchmark privado del CAISI) y ARC-AGI-2 (con un método de scoring distinto al de los leaderboards públicos).
Cuando se usa el ECI de Epoch AI, que también aplica IRT sobre un conjunto de benchmarks, la brecha entre abiertos y cerrados se ha mantenido entre 3 y 7 meses desde R1.
Tanto el CAISI como el ECI tienen un techo metodológico, advierte Interconnects. Las tareas de coding se evalúan con acceso a bash y un bucle simple con presupuesto fijo de tokens, no con harnesses como Claude Code u OpenCode, que es justamente donde se entrenan estos modelos. Por eso aparecen resultados llamativos: hay benchmarks que afirman que portear aplicaciones entre lenguajes hoy no es posible, mientras en GitHub Bun fue portado de Zig a Rust con 1 millón de LOC modificadas. Una comparación justa de frontera debería usar los harnesses preferidos de cada modelo y prompting específico por familia.
¿Qué modelos abiertos se llevan los aplausos del mes?
Estos son los lanzamientos destacados por el boletín, con su licencia y tamaño cuando corresponde:
| Modelo | Laboratorio | Tamaño | Licencia / Notas |
|---|---|---|---|
| Gemma 4 (4B / 9B / 26B-A4B MoE / 31B) | hasta 31B densos | Apache 2.0 (cambio clave) | |
| DeepSeek-V4 Pro / Flash | DeepSeek | 1.6T-A49B MoE / 284B-13B | Flash sería la estrella real |
| Kimi K2.6 | Moonshot AI | — | Foco en tareas long-horizon |
| MiMo V2.5 Pro | Xiaomi (XiaomiMiMo) | — | Apache 2.0, codo a codo con K2.6 y GLM-5.1 |
| GLM-5.1 | Z.ai | — | Mejora general, foco en horizonte largo |
| Laguna XS.2 | Poolside AI | 33B-A3B | Primer open-weight coding del lab |
| Qwen3.6-35B-A3B | Qwen / Alibaba | 35B-A3B | Actualización de la familia 3.5 |
| LFM2.5-350M | Liquid AI | 350M | 28T tokens; sobreentrenamiento extremo |
| Trinity-Large-Thinking | arcee-ai | — | Versión de razonamiento, top OpenRouter |
El cambio de licencia de Gemma 4 a Apache 2.0 es una noticia editorial dentro de la noticia: elimina la incertidumbre y los desafíos legales que generaban las licencias custom de Google sobre versiones anteriores de la familia.
¿Qué pasa con los chinos y por qué importa para LatAm?
DeepSeek-V4-Flash, con 284B totales y 13B activos, aparece como la opción más práctica del paquete chino para correr local o en proveedores no-hyperscaler. Kimi K2.6 y MiMo 2.5 Pro empujan en long-horizon, es decir, agentes que sostienen tareas durante horas, lo que está alineado con lo que Andrej Karpathy llamó autoresearch. Para equipos en Chile o LatAm que ya estaban usando DeepSeek V3 o Qwen detrás de su stack, el upgrade es directo: pesos disponibles en Hugging Face, sin pasar por aprobaciones de Google o Anthropic.
La nota original deja además una observación editorial honesta dentro del propio equipo de Interconnects: Florian cree que la frontera abierta está más cerca de la cerrada de lo que indican los benchmarks, mientras que Nathan opina que los cerrados siguen más adelante. El debate interno es señal de que la lectura única del "open lags behind" no aplica.



