Un equipo de investigadores de Meta, la Universidad de Stanford y la Universidad de Washington presentó tres métodos nuevos que aceleran sustancialmente la generación del Byte Latent Transformer (BLT), una arquitectura de modelo de lenguaje que opera directamente sobre bytes en lugar de tokens.
¿Por qué los modelos byte-level son lentos en inferencia?
Para entender qué resuelve esta investigación, hay que entender el trade-off central del modelado byte-level.
La mayoría de los modelos de lenguaje hoy trabaja con tokens, trozos de texto producidos por tokenizadores subword tipo byte-pair encoding (BPE). Un token suele representar varios caracteres o incluso una palabra entera. Esto es eficiente, pero tokenizar viene con desventajas conocidas: sensibilidad al ruido en la entrada, mal manejo de texto multilingüe, comprensión débil a nivel de carácter y fragilidad ante entradas estructuradas como código y números.
Los modelos byte-level esquivan todo esto operando directamente sobre los bytes, la representación de texto de más bajo nivel. El BLT fue un paso clave: igualó el rendimiento de los modelos basados en tokenización al agrupar bytes dinámicamente en patches de largo variable usando una estrategia de segmentación basada en entropía. Las regiones de alta entropía (más difíciles de predecir) reciben patches más cortos; las más predecibles reciben patches más largos. La carga gruesa del cómputo corre sobre representaciones de tokens latentes, no sobre los bytes crudos, usando tres componentes (un encoder local, un Transformer global grande y un decoder local) con un tamaño promedio de patch de 4 bytes y un máximo de 8.
El problema que quedaba pendiente es la velocidad de inferencia. Incluso con el diseño jerárquico de BLT, el decoder local sigue generando un byte a la vez de manera autoregresiva. Como un token subword típico corresponde a varios bytes, BLT necesita múltiples forward passes del decoder para producir la misma cantidad de texto que un modelo a nivel de token produce en un solo paso. En la serving moderna de LLMs, el cuello de botella suele no ser el cómputo sino el ancho de banda de memoria: cargar repetidamente los pesos del modelo y los caches de clave-valor desde memoria. Más forward passes del decoder significa más cargas de memoria, lo que se traduce directamente en generación más lenta.
Paper completo: arxiv.org/pdf/2605.08044
Tres métodos, un mismo objetivo: menos forward passes
El equipo de investigación propone tres técnicas que reducen este cuello de botella, cada una haciendo un trade-off distinto entre velocidad y calidad de generación.
BLT Diffusion (BLT-D)
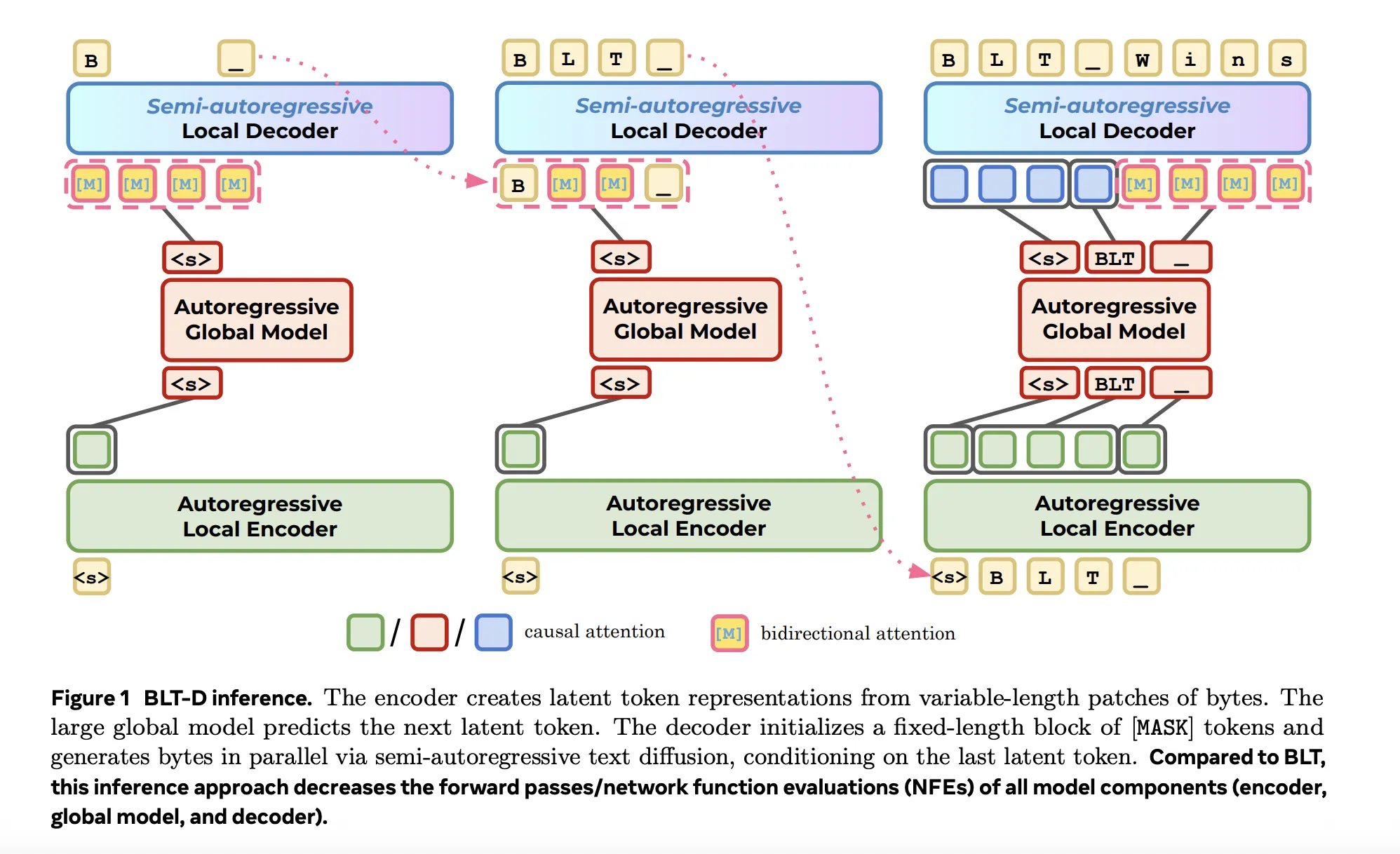
Es la contribución central y la variante más rápida. La idea clave es reemplazar la decodificación byte por byte autoregresiva con difusión discreta por bloques en el decoder local.
Durante el entrenamiento, el decoder recibe dos entradas: una secuencia limpia de bytes (el texto original) y una secuencia corrupta de bloques de bytes de largo fijo. Para cada bloque, se muestrea un timestep continuo de difusión t desde U(0,1), y cada byte del bloque es reemplazado independientemente con un token [MASK] con probabilidad t. Esto significa que el grado de masking varía por ejemplo de entrenamiento: un t más bajo deja la mayoría de los bytes visibles; un t más alto enmascara la mayoría. El tamaño de bloque B (fijado en 4, 8 o 16 bytes en los experimentos) típicamente excede el promedio de 4 bytes por patch de BLT, enseñándole al decoder a predecir bytes más adelante en el futuro de lo que normalmente lo haría. La función de pérdida total combina la pérdida estándar autoregresiva de predicción del siguiente byte sobre la secuencia limpia y una pérdida de predicción de byte enmascarado sobre los bloques corruptos, conceptualmente similar a cómo funciona el masked language modeling de BERT, pero aplicado a nivel de byte dentro de la arquitectura jerárquica de BLT.
En inferencia, BLT-D inicializa un bloque de posiciones [MASK] y desenmascara iterativamente múltiples posiciones por paso del decoder usando una de dos estrategias: desenmascaramiento por confianza (desenmascarar posiciones cuya probabilidad predicha supere un umbral α) o muestreo entropy-bounded (EB), que selecciona el mayor subconjunto de posiciones cuya entropía acumulada se mantenga bajo un umbral γ. Ambas estrategias generan múltiples bytes por forward pass en vez de uno solo. El encoder y el modelo global, los componentes caros de BLT, son invocados una vez por bloque en lugar de una vez por patch, reduciendo aún más el total de llamadas al modelo. BLT-D también soporta KV caching, beneficiándose de cualquier técnica que reduzca el footprint del KV cache.
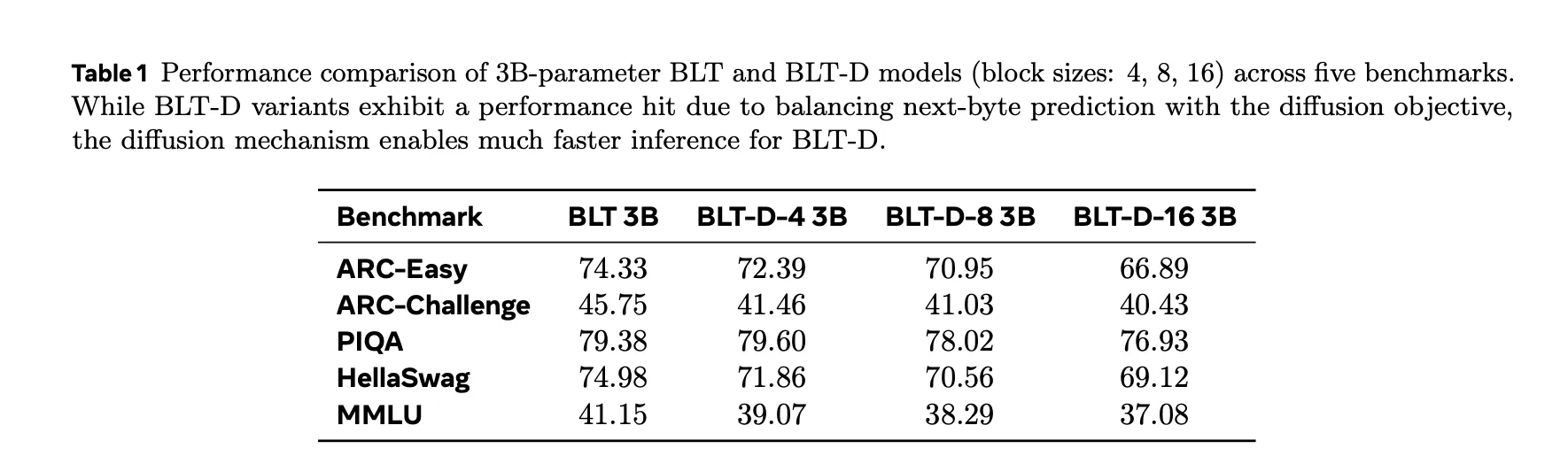
A 3B parámetros, BLT-D-4 (tamaño de bloque 4) casi iguala los scores de tareas de BLT requiriendo menos de la mitad del ancho de banda de memoria. BLT-D-16 (tamaño de bloque 16) logra una reducción de 87-92% en el costo estimado de ancho de banda de memoria comparado con BLT, lo que la convierte en la configuración más rápida evaluada, aunque con scores pass@1 más bajos en benchmarks de coding (HumanEval, MBPP).
BLT Self-Speculation (BLT-S)
Toma una ruta distinta, basándose en speculative decoding, una técnica donde un modelo borrador económico propone tokens y un modelo más grande los verifica en paralelo. Lo inusual de BLT-S es que no requiere un modelo borrador separado ni cambios arquitectónicos ni entrenamiento adicional. Reutiliza el decoder local liviano de BLT como drafter.
En la inferencia estándar de BLT, el decoder deja de generar cada vez que el patcher basado en entropía determina que se alcanzó un borde de patch nuevo, típicamente cada cuatro bytes. BLT-S, en cambio, deja que el decoder genere autoregresivamente hasta un tamaño de ventana fijo k (8 o 16 bytes en los experimentos), sin importar los picos de entropía, condicionando sobre el último token latente disponible. Tras producir un draft de k bytes, el modelo completo re-encodea la secuencia candidata a través del encoder, el modelo global y el decoder, y produce predicciones del siguiente byte. Los bytes drafteados se aceptan hasta el primer desajuste; el primer byte desajustado se reemplaza con la predicción verificada.
Bajo decodificación greedy, este procedimiento garantiza que las salidas verificadas son idénticas a la decodificación autoregresiva estándar de BLT, sin pérdida de calidad. BLT-S aumenta levemente los forward passes del decoder pero reduce sustancialmente las llamadas al encoder y al modelo global. A 3B parámetros con k=16, BLT-S puede lograr hasta un 77% de reducción de ancho de banda de memoria sin pérdida de rendimiento en la tarea.
BLT Diffusion+Verification (BLT-DV)
Se sienta en el medio. Como BLT-D se entrena con un objetivo de difusión y un objetivo estándar de predicción del siguiente byte, los mismos pesos del modelo pueden correrse autoregresivamente usando máscaras causales del decoder; no se necesita modelo separado ni entrenamiento adicional. BLT-DV explota esto: la difusión draftea un bloque de bytes primero, y luego un solo forward pass autoregresivo verifica el draft, aceptando bytes hasta el primer desajuste. Empíricamente, la difusión de un paso combinada con verificación entregó la configuración más rápida de BLT-DV. Aunque la difusión de un solo paso por sí sola suele degradar rápidamente la calidad de generación, el paso de verificación previene esa degradación. A 3B parámetros, BLT-DV puede lograr hasta un 81% de reducción de ancho de banda de memoria comparado con BLT.
Entender los números
Todos los modelos se entrenaron sobre el dataset BLT-1T (1 billón de tokens de fuentes públicas, incluyendo un subset de Datacomp-LM), con modelos de 1B parámetros entrenados por 240.000 pasos y modelos de 3B por 480.000 pasos. La evaluación cubrió cuatro tareas de generación: traducción francés-inglés y alemán-inglés usando el benchmark FLORES-101 (4-shot, SentencePiece BLEU) y dos benchmarks de coding (HumanEval, 0-shot, pass@1, y MBPP, 3-shot, pass@1).
Más allá de las tareas de generación, el equipo también evalúa BLT-D en cinco benchmarks basados en likelihood: ARC-Easy, ARC-Challenge, PIQA, HellaSwag y MMLU. Como BLT-D se entrena con un objetivo de predicción del siguiente byte junto al objetivo de difusión, puede computar likelihoods autoregresivos aplicando una máscara causal al decoder, el mismo mecanismo del que depende el paso de verificación de BLT-DV. Los resultados muestran que las variantes de BLT-D logran scores cercanos al baseline de BLT en los cinco benchmarks, confirmando que integrar difusión por bloques no compromete la capacidad de razonamiento autoregresivo del modelo.
La eficiencia se reporta vía tres métricas proxy: NFEs (network function evaluations) del decoder, NFEs del encoder y modelo global, y una cifra estimada de ancho de banda de memoria en gigabytes derivada del conteo de parámetros y de los forward passes bajo precisión de 16 bits. El equipo es explícito en que estas son métricas proxy: convertir las reducciones de NFE en mejoras reales de wall-clock requiere una implementación de inferencia altamente optimizada, que los autores marcan como la dirección más importante de trabajo futuro.
Las tareas de traducción son las que más se benefician de BLT-D en todos los tamaños de bloque. Las tareas de coding muestran más sensibilidad al tamaño de bloque: BLT-D-16 ofrece las ganancias más grandes de eficiencia pero muestra caídas significativas en HumanEval y MBPP. Un hallazgo adicional notable viene del análisis de diversidad de generación: al usar muestreo entropy-bounded con top-p sampling en inferencia, más NFEs del decoder se correlacionan con mayor ratio tipo-token (una medida de diversidad léxica). Esto significa que el trade-off eficiencia-diversidad es ajustable en tiempo de inferencia sin reentrenar.
Conclusiones clave
- BLT-D introduce difusión discreta por bloques en el decoder local de BLT, entrenado con una pérdida combinada de predicción de siguiente byte y de byte enmascarado, para generar múltiples bytes por forward pass en lugar de uno a la vez.
- BLT-S usa el decoder liviano del propio BLT como drafter especulativo (sin modelo separado, sin cambios arquitectónicos, sin entrenamiento adicional) y bajo decodificación greedy produce salida idéntica a BLT estándar.
- BLT-DV combina draft por difusión con un paso de verificación autoregresivo usando los mismos pesos del modelo BLT-D, recuperando calidad perdida en decodificación sólo-difusión sin entrenamiento extra.
- Todos los métodos pueden lograr un costo estimado de ancho de banda de memoria más de 50% inferior al de BLT en tareas de generación; BLT-D-16 puede llegar al 87-92% de reducción.
- La capacidad autoregresiva de BLT-D se mantiene robusta en benchmarks basados en likelihood (ARC-Easy, ARC-Challenge, PIQA, HellaSwag, MMLU), y su diversidad de generación es ajustable en inferencia vía los umbrales de muestreo entropy-bounded.