TL;DR

Miles es el framework open source de RadixArk para el post-training por refuerzo (RL) de LLMs a gran escala. Compone SGLang para el rollout, NVIDIA Megatron-LM para el entrenamiento, orquestación con Ray y extensibilidad PyTorch-nativa detrás de un trainer chico y enchufable, con recetas de baja precisión unificadas, alineación rollout/training consciente de MoE, sincronización rápida de pesos vía NVIDIA NCCL/RDMA, observabilidad y tolerancia a fallos incorporadas. La promesa: hacer el RL de LLMs a escala frontier más fácil de construir, reproducir y operar.
¿Por qué Miles?
El aprendizaje por refuerzo se volvió una parte central del post-training de LLMs. Pero a medida que los modelos crecen, migran de densos a mixture-of-experts (MoE) y corren sobre hardware distribuido y especializado (por ejemplo, las series Blackwell y Hopper de NVIDIA), el RL post-training deja de ser solo un bucle de entrenamiento. Es un problema de sistemas distribuidos.
Un framework moderno de RL para LLMs necesita coordinar varias piezas en movimiento:
- Los rollout workers deben generar muestras con alto throughput.
- Los trainers deben consumir esas muestras eficientemente y computar actualizaciones estables de política.
- La política de rollout y la de entrenamiento deben mantenerse sincronizadas.
- Los modelos MoE grandes introducen comportamiento de ruteo que debe permanecer alineado entre rollout y training.
- Las recetas de baja precisión necesitan funcionar consistentemente en todo el pipeline.
- Los jobs de larga duración requieren observabilidad, checkpointing y tolerancia a fallos desde el inicio.
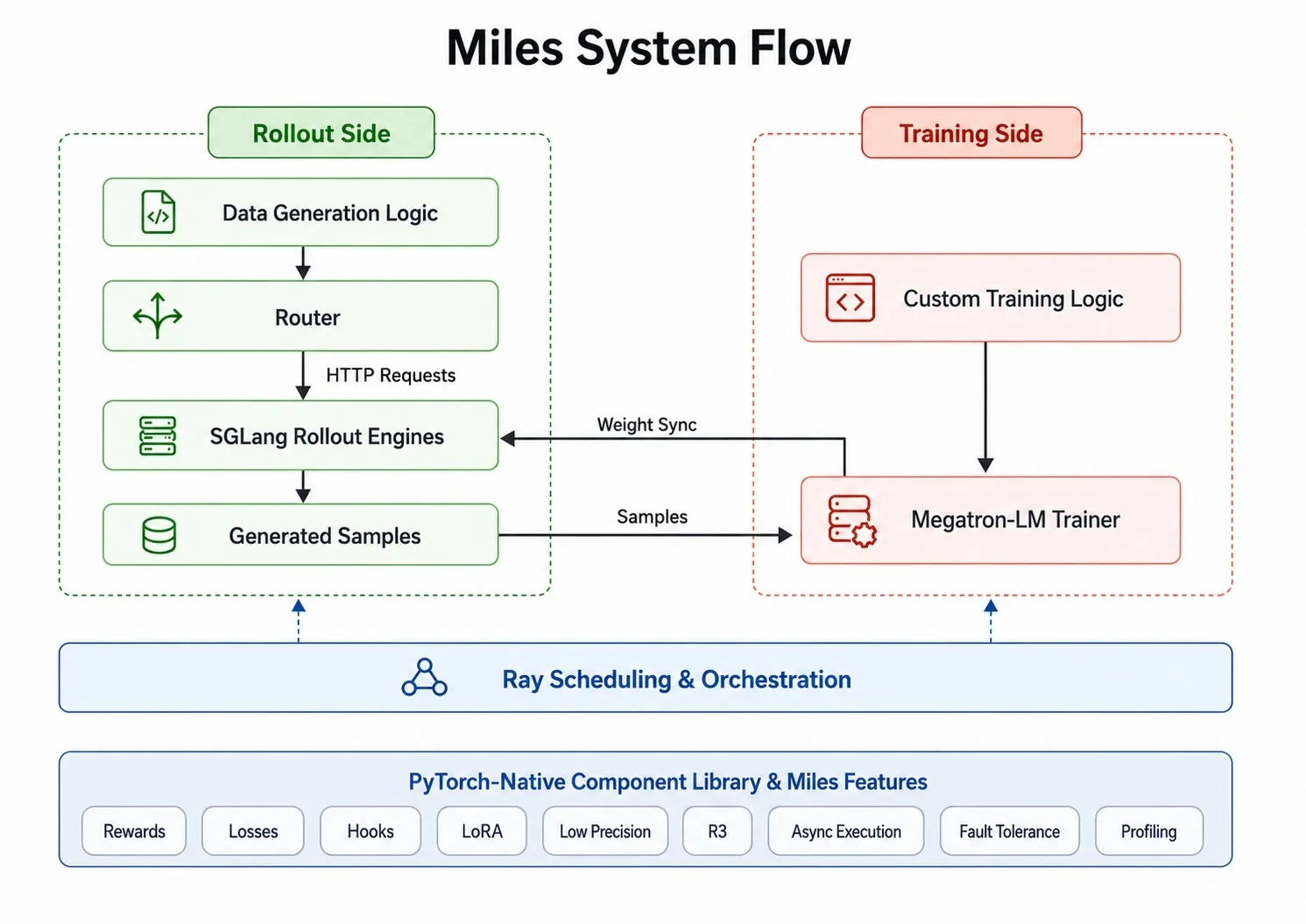
Miles fue construido para este escenario. Está montado nativamente sobre SGLang para rollout de alto throughput, se integra profundamente con Megatron-LM para entrenamiento escalable, usa Ray para orquestar el sistema distribuido y mantiene PyTorch como la capa numérica y de programación común a lo largo del stack.
El objetivo es simple: hacer el entrenamiento RL a gran escala más componible, reproducible y fácil de escalar, mientras se mantiene el trainer central lo bastante chico para que investigadores y equipos de infraestructura puedan personalizarlo.
¿Cómo está armada la arquitectura de Miles?
Miles sigue una filosofía de small-core, many-edges.
El bucle de entrenamiento central es intencionalmente compacto. Las piezas que los usuarios quieren cambiar más seguido (lógica de rollout, cómputo de reward, funciones de loss, filtrado de muestras, métricas y hooks del training loop) se enchufan al momento del launch a través de módulos Python provistos por el usuario. Esto permite a los equipos adaptar el sistema a nuevos algoritmos y restricciones de producción sin forkear el framework.
Debajo de ese núcleo chico, Miles compone cuatro sistemas mayores:
- SGLang para generación de rollout de alto throughput.
- Megatron-LM para entrenamiento distribuido escalable.
- Ray para orquestación de cluster, ciclo de vida de actores, scheduling y supervisión.
- PyTorch para modelos, autograd, primitivas distribuidas, soporte de dtype, extensibilidad y profiling.
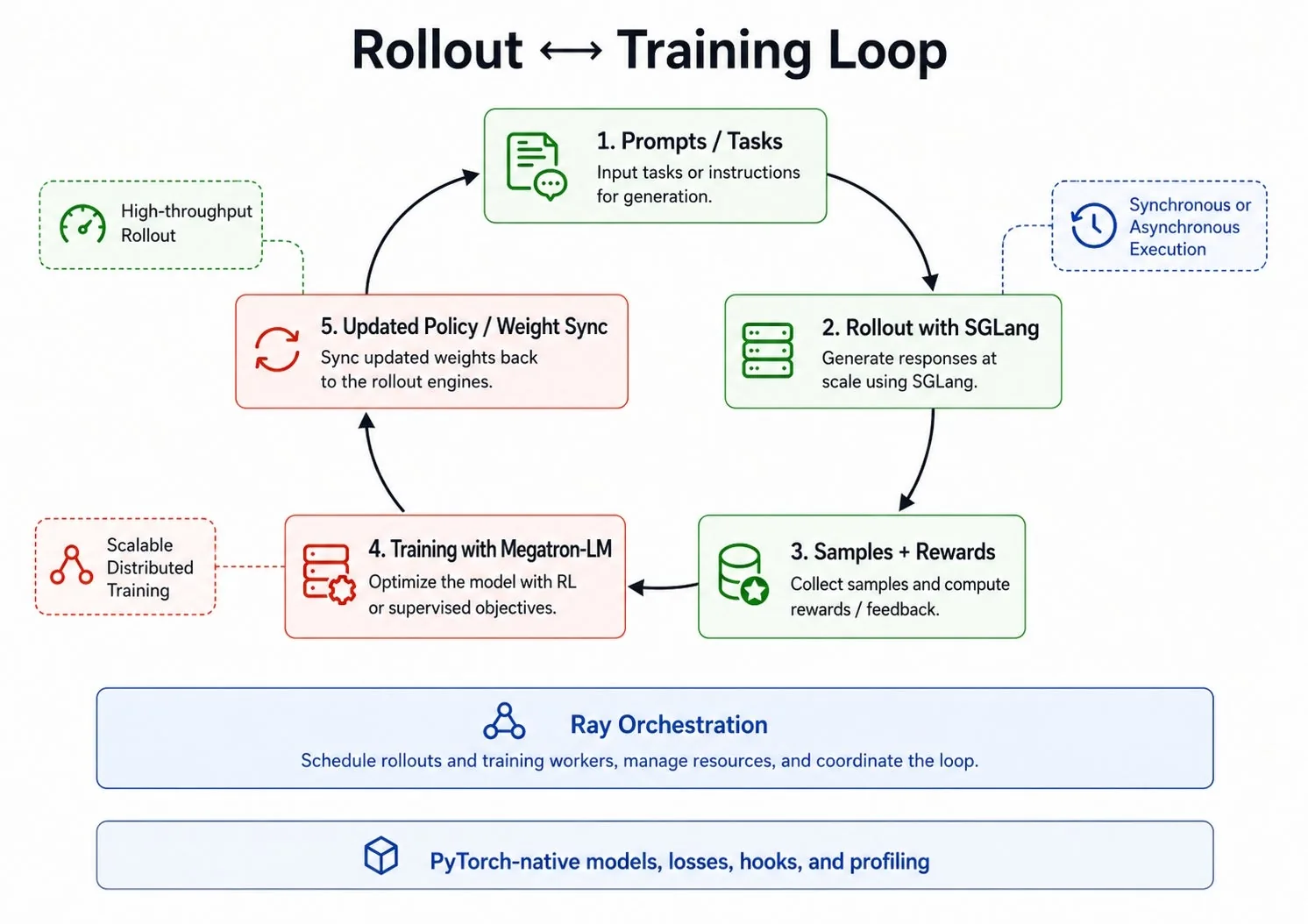
Esta composición importa. El RL post-training requiere que generación y entrenamiento trabajen juntos, pero las dos fases tienen perfiles de rendimiento muy distintos: el rollout está limitado por ancho de banda de memoria (las lecturas de KV-cache y parámetros dominan durante el decoding), mientras que el entrenamiento está limitado por cómputo y es intensivo en comunicación. Sincronización de pesos, transferencia de muestras, conversión de checkpoints, consistencia de ruteo y comportamiento de baja precisión: todo tiene que manejarse con cuidado a través de esa frontera.
Ray: orquestando jobs RL de larga duración
Miles está construido directamente sobre el runtime distribuido de Ray. En una corrida Miles, cada proceso de larga vida se representa como un actor Ray: rangos del trainer, servidores de rollout SGLang, proxies de ruteo y workers asíncronos de rollout viven dentro del modelo de actores de Ray.
Miles usa el scheduler GPU-aware de Ray y sus placement groups para colocar actores, soportando layouts desagregado (rollout y training en nodos separados) y colocado (rollout y training en los mismos nodos) mediante specs de placement al momento del launch. La colocación de procesos debe ser rack-aware para facilitar reservas de nodos de repuesto y aislamiento de errores, dado que distinguir un problema dentro de un rack (por ejemplo, una GPU mala versus un problema de rack completo) no siempre es directo.
Prompts, muestras y pesos actualizados circulan continuamente entre actores de rollout y rangos del trainer, y Miles usa actores y tareas Ray para coordinar ese flujo. Para transferencia masiva de pesos, Ray maneja el camino de control mientras los bytes de tensores se mueven sobre canales dedicados NCCL/RDMA, dando a Miles tanto programabilidad a nivel Ray como un fast path para data grande.
Como los actores Ray son persistentes, mantienen su propio estado y se schedulean de forma independiente, Miles puede correr un modo totalmente asíncrono en el que rollout y training ya no se bloquean mutuamente: los actores de rollout hacen streaming continuo de muestras a una cola que el trainer drena a su propio ritmo.
Megatron-LM: escalando el backend de entrenamiento
Miles usa Megatron-LM como su backend de entrenamiento en producción, enchufándose directamente a su parser de argumentos, pipeline de construcción de modelo, training loop, primitivas de paralelismo y formato de checkpoint distribuido, en vez de envolverlo como una biblioteca black-box. Eso le da a Miles la infraestructura necesaria para entrenamiento denso y MoE a escala frontier, preservando un workflow limpio para el usuario.
Miles reutiliza directamente la superficie de configuración de Megatron (largo de secuencia, rotary embeddings, GEMM agrupado, todos los sabores de paralelismo, settings de optimizador, activation checkpointing, etc.) en vez de envolverla o re-declararla. Los usuarios configuran una corrida Miles mediante un único script de launch que combina opciones específicas de Miles con opciones estándar de Megatron.
Las arquitecturas frontier cambian rápido, con nuevos bloques de atención, mecanismos de ruteo y layouts de expertos que llegan constantemente. Miles los maneja mediante model specs enchufables: archivos de spec chicos que insertan componentes PyTorch custom (por ejemplo, un módulo de gated attention-output, un bloque Gated-Delta-Net o un router MoE específico del modelo) directamente en el pipeline de Megatron. Esto le permite a Miles soportar nuevas arquitecturas (DeepSeek-V3/V4, GLM-4.7 y variantes MoE de Qwen3, por ejemplo) sin mantener un fork de Megatron que se diverja constantemente del upstream.
Miles usa el formato de checkpoint distribuido consciente de paralelismo de Megatron, por lo que un modelo se puede convertir desde Hugging Face una vez y después cargarse en distintas configuraciones de paralelismo (tensor, pipeline, contexto, experto) sin re-convertir pesos desde cero.
PyTorch: la capa común para modelos, numérica y extensibilidad
PyTorch es el modelo de programación común dentro de Miles: los componentes de modelo son torch.nn.Modules regulares, las losses son grafos autograd estándar, y mixed precision, gradient checkpointing, primitivas distribuidas y profiling se quedan todos dentro de workflows PyTorch familiares. Esto importa porque el RL post-training de LLMs cambia rápido: los equipos necesitan agregar nuevos rewards, losses, routers, módulos de modelo y herramientas de debugging sin aprender una nueva abstracción cada vez.
Miles construye su pipeline de baja precisión sobre el sistema de dtype de PyTorch, con recetas BF16, FP8, MXFP8 e INT4-QAT que abarcan training y rollout, en vez de vivir como features aislados del backend. Esta consistencia importa para RL porque la política usada para generar muestras y la política usada para computar log probabilities de entrenamiento deben mantenerse alineadas.
Qué trae Miles fuera de la caja
- Integración rollout y training: conecta rollout SGLang con entrenamiento Megatron-LM, con ejecución desagregada y colocada para distintos presupuestos GPU y objetivos de utilización.
- Ejecución asíncrona: modo totalmente async que desacopla rollout de training, eliminando el bloqueo por iteración entre las dos fases.
- Sincronización rápida de pesos: después de cada actualización de training, los pesos frescos fluyen hacia los rollout workers sobre canales dedicados NCCL/RDMA.
- Alineación rollout/training consciente de MoE: Rollout Routing Replay preserva las decisiones de ruteo a través de la frontera rollout/training, reduciendo el desajuste que desestabilizaría el RL MoE.
- Soporte de baja precisión unificado: pipeline BF16 / FP8 / MXFP8 / INT4-QAT diseñado como parte del stack RL end-to-end, no como recetas aisladas de training.
Contexto para equipos LatAm
Para equipos de investigación en LatAm que hacen fine-tuning por refuerzo sobre modelos como Qwen3 MoE o DeepSeek-V3, Miles cambia el punto de partida. Antes había que armar el pegamento entre SGLang, Megatron y Ray a mano, con re-conversiones de checkpoint cada vez que cambiaba la forma del cluster. Ahora ese pegamento viene resuelto y el foco puede quedar en la receta RL (reward, loss, filtrado) en vez de en la ingeniería distribuida. El código está en el blog oficial de PyTorch y se distribuye bajo licencia open source.