
TL;DR: El soporte de DeepSeek-V4 estuvo disponible en SGLang desde Day-0, pero ese fue solo el punto de partida. Desde el lanzamiento, el equipo coordinó un conjunto de mejoras en kernels, runtime y hardening: fusión de MHC y token-bucket prewarm, KV Compression V2, W4A4 MegaMoE, mejor budgeting y eviction para SWA, admisión mejorada de decode disaggregated, soporte para CUDA graphs rompibles en el path de prefill de DeepSeek-V4 y fixes de bugs tanto en SGLang como en Dynamo que eliminaron inestabilidad en la frontera de serving.
En la lane pública SemiAnalysis InferenceX GB300 disaggregated (DeepSeek-V4 Pro, FP4, ISL=8192, OSL=1024, dynamo-sglang), la curva MTP de junio de 2026 entrega ~11.200 tok/s/GPU a aproximadamente 50 tok/s/user, contra los ~2.200 tok/s/GPU de la curva sin MTP del Day-0 (abril de 2026). Un aumento de 5x a la misma interactividad visible para el usuario.
¿Qué muestran los resultados de performance?
NVIDIA GB300 Disaggregated 8K/1K
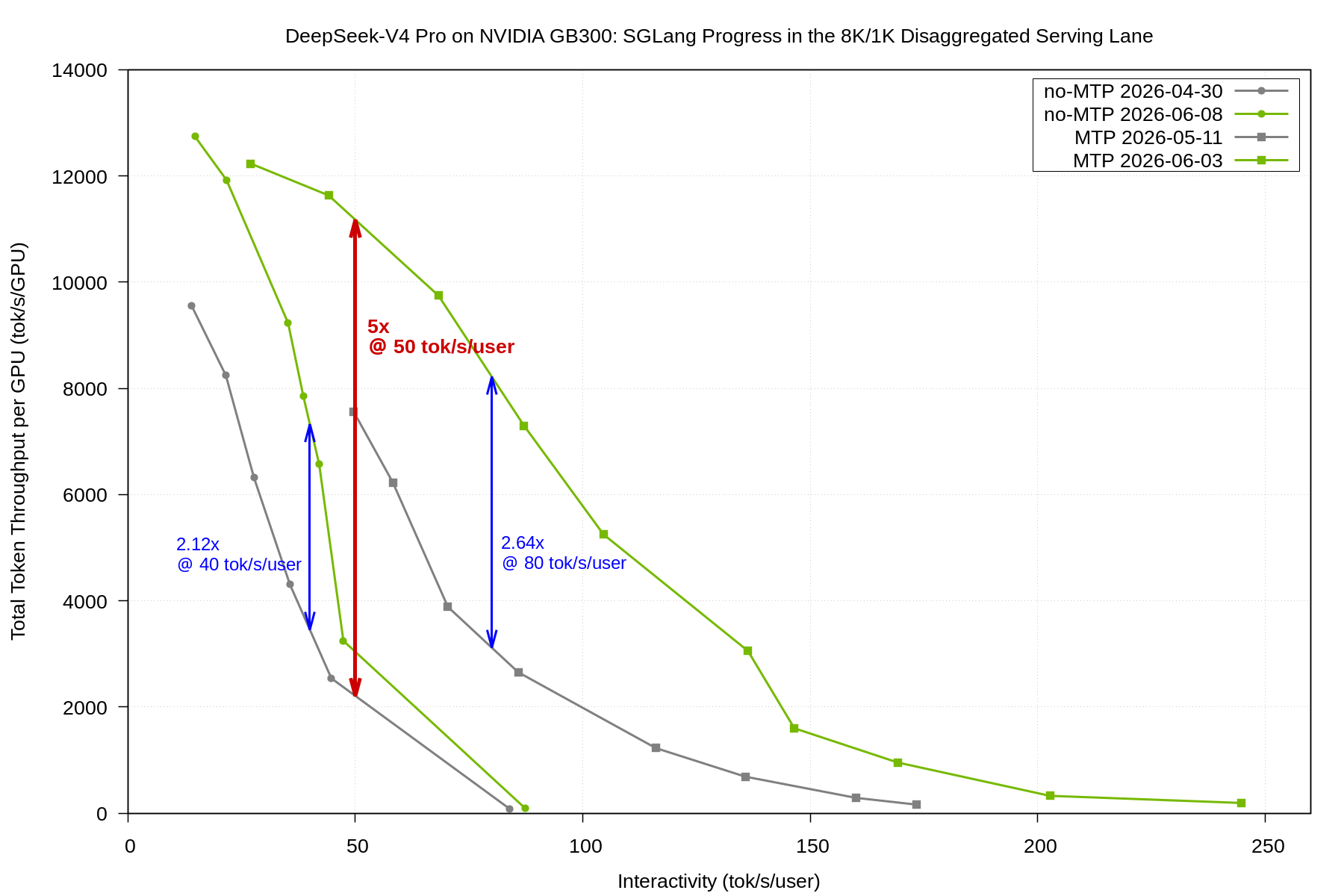
La lane disaggregated del GB300 muestra mejoras sustantivas. Dos elementos destacan. Primero, no se trata de una victoria puntual: tanto la curva sin MTP como la curva MTP se elevaron en todo el rango de interactividad. Segundo, y más importante para despliegues reales, las curvas ahora sostienen throughput mucho más profundo en la región de alta interactividad. La curva Day-0 caía abruptamente pasados los 40 tok/s/user; las curvas de junio sostienen 2,1x más throughput a 40 tok/s/user (sin MTP) y 2,6x más a 80 tok/s/user (MTP), el rango de interactividad que apuntan la mayoría de los despliegues.
NVIDIA Blackwell Ultra Aggregated 8K/1K
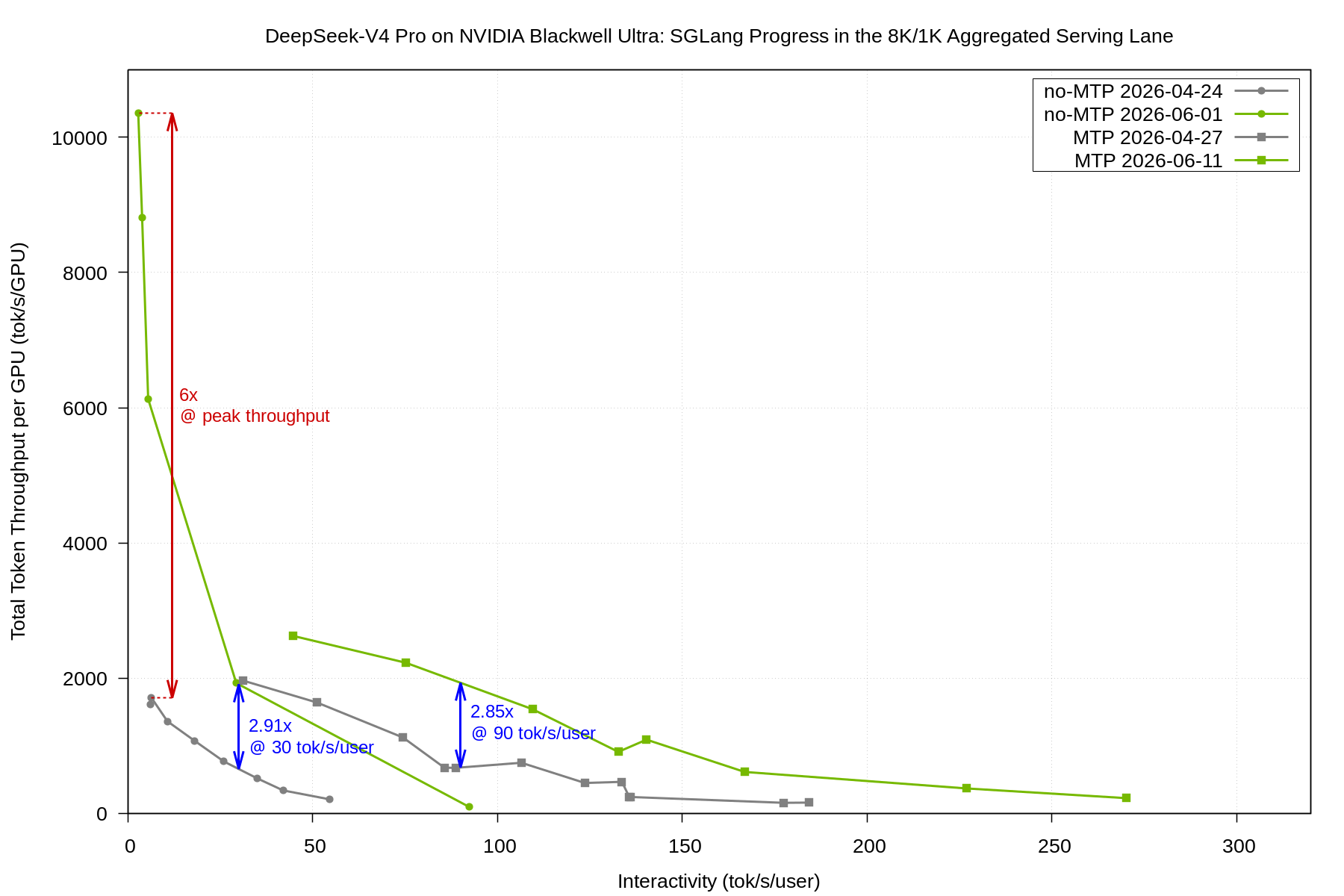
La lane aggregated del Blackwell Ultra muestra mejoras significativas gracias a las mismas optimizaciones. El throughput subió 2,91x a 30 tok/s/user (sin MTP) y 2,85x a 90 tok/s/user (MTP). Además, el peak sin MTP mejoró más de 6x comparado con la curva Day-0. Esto ocurre porque la curva anterior partía desde un recipe fallback de menor throughput con ejecución TP-only, sin DP attention, sin speculative decoding y con un espacio de búsqueda más estrecho.
¿Qué había en el Day-0 y qué se sumó después?
El soporte de Day-0 ya era sustancial. En la ventana de lanzamiento, SGLang tenía un path funcional de serving para DeepSeek-V4, guías de despliegue a través de la familia de recipes, y configuraciones de lanzamiento verificadas en múltiples plataformas. El stack inicial ya ejercitaba los ingredientes principales: inferencia FP4, ejecución MoE con kernels DeepGEMM MegaMoE para alto throughput y backend FlashInfer TRT-LLM MoE para baja latencia, infraestructura de atención/kernels relacionada con FlashMLA, variantes de recipes DP/EP/TP, despliegue disaggregated, soporte de speculative decoding y CUDA graph completo en el lado de decode.
Esa fundación importó. En lugar de partir desde "¿el modelo siquiera corre?", el equipo arrancó con un sistema que ya servía DeepSeek-V4 en hardware real, incluyendo los primeros submissions agregados sobre NVIDIA Blackwell Ultra y los primeros submissions disaggregated sobre NVIDIA GB300 justo después del lanzamiento. El trabajo de follow-up se trató de convertir ese stack inicial en un path de serving más rápido, más estable y con forma productiva.
Optimizaciones de kernel
El trabajo más visible del lado de kernels fue en el pipeline MHC. En el PR #24775, SGLang reescribió el path MHC de DeepSeek-V4 alrededor de una implementación fusionada más profunda: el voluminoso mhc_pre path se movió a un flujo respaldado por DeepGEMM más fuerte, el RMSNorm se fusionó dentro del path MHC en lugar de quedar como un boundary separado, y se agregó un kernel dedicado hc_head fusionado. Esto reduce el tráfico intermedio de tensores y el plumbing visible al scheduler. El PR #25976 continúa la misma línea sumando un kernel mhc_fused_post_pre que achica el número de boundaries costosos.
KV Compression V2 fue el otro salto mayor en kernels. El PR #24890 agregó los kernels V2 de compresión específicos para DeepSeek-V4, incluyendo nuevos kernels c4, c128 y online c128, además de plumbing actualizado y piezas fusionadas fused norm/rope V2.
El path FP4 MoE también mejoró materialmente. Antes del PR #25052, el path DeepGEMM MegaMoE usaba el kernel W4A8: los pesos de los expertos estaban cuantizados a MXFP4 pero el path de activaciones aún cuantizaba a MXFP8. Después del PR, SGLang permite activar el path W4A4 MegaMoE, donde las activaciones también pasan a MXFP4 sin pérdida apreciable de precisión.
Optimizaciones de runtime
El trabajo de runtime fue igual de importante. En DeepSeek-V4, la frontera de serving suele estar definida por si el runtime puede budgetear, asignar, capturar en grafo y reciclar el estado correcto bajo mezclas reales de requests. El PR #24036 corrige el dimensionamiento de la preallocation SWA en decode disaggregated, separando la contabilidad de full-length de la cola SWA que efectivamente debe permanecer residente en el pool de ventana deslizante. El PR #24857 lleva eso más lejos con budgeting más preciso de tokens full y SWA, mejor lógica de reservación entre estados waiting, running y transfer, y comportamiento de preallocation más realista para la cola SWA.
El recipe-per-concurrency dispatch fue otra mejora clave. Para la lane aggregated de Blackwell Ultra, el equipo se alejó del enfoque "una talla para todos" y pasó a una estrategia donde cada nivel de concurrencia usa un recipe ajustado. Para la lane disaggregated del GB300, introdujeron un set de recipes tunedados que generaron mejoras sustantivas.
La historia de CUDA graphs también mejoró. El PR #25195 sobre breakable-CUDA-graph para DP attention de DeepSeek-V4, junto con el follow-up de speculative-path #25795, empujó más del path de prefill bajo ejecución amigable con grafos.
Bug fixes que movieron la curva
Algunos de los mayores avances de performance vinieron en forma de bug fixes. El PR #23919 arregla el bug del buffer de metadata PD-MTP con hidden-size, y el PR #25805 corrige un double-free en SWA memory handling bajo decode disaggregated con especulación MTP.
El PR #25733 arregla un NaN de DeepSeek-V4-Pro en NVIDIA Blackwell convirtiendo el input scale de fp8_einsum a ue8m0. Aunque se presenta como un fix de correctness, tuvo un efecto práctico en el path especulativo: una vez que el FP8-einsum scaling de Blackwell dejó de corromper el path MTP de DeepSeek-V4, la longitud de aceptación se recuperó. En una corrida observada, este fix de una línea elevó la tasa de aceptación de 0,57 a 0,70. Es un buen ejemplo de un bug fix que no se presenta como "PR de performance" y aun así mueve la frontera MTP en la práctica.



