
IA
FLUX 3 de Black Forest Labs: IA multimodal y robótica
BFL presenta FLUX 3, un modelo multimodal capaz de generar video con audio, texto y controlar robots, superando a competidores como Gemini Omni y Grok Imagine.
Latent Space
11 notas publicadas

Black Forest Labs presenta un modelo multimodal que aprende de imágenes, video y audio, y que la empresa alemana ya prueba en robótica junto a Audi.

El modelo multimodal de 2,4 billones de parametros llega en version preview y busca frenar el impulso de Kimi K3 antes de que Moonshot AI salga a bolsa.
Thinking Machines Lab, la empresa de Mira Murati, presenta su primer modelo entrenado desde cero: 975.000 millones de parámetros, multimodal y con pesos abiertos de uso comercial libre.
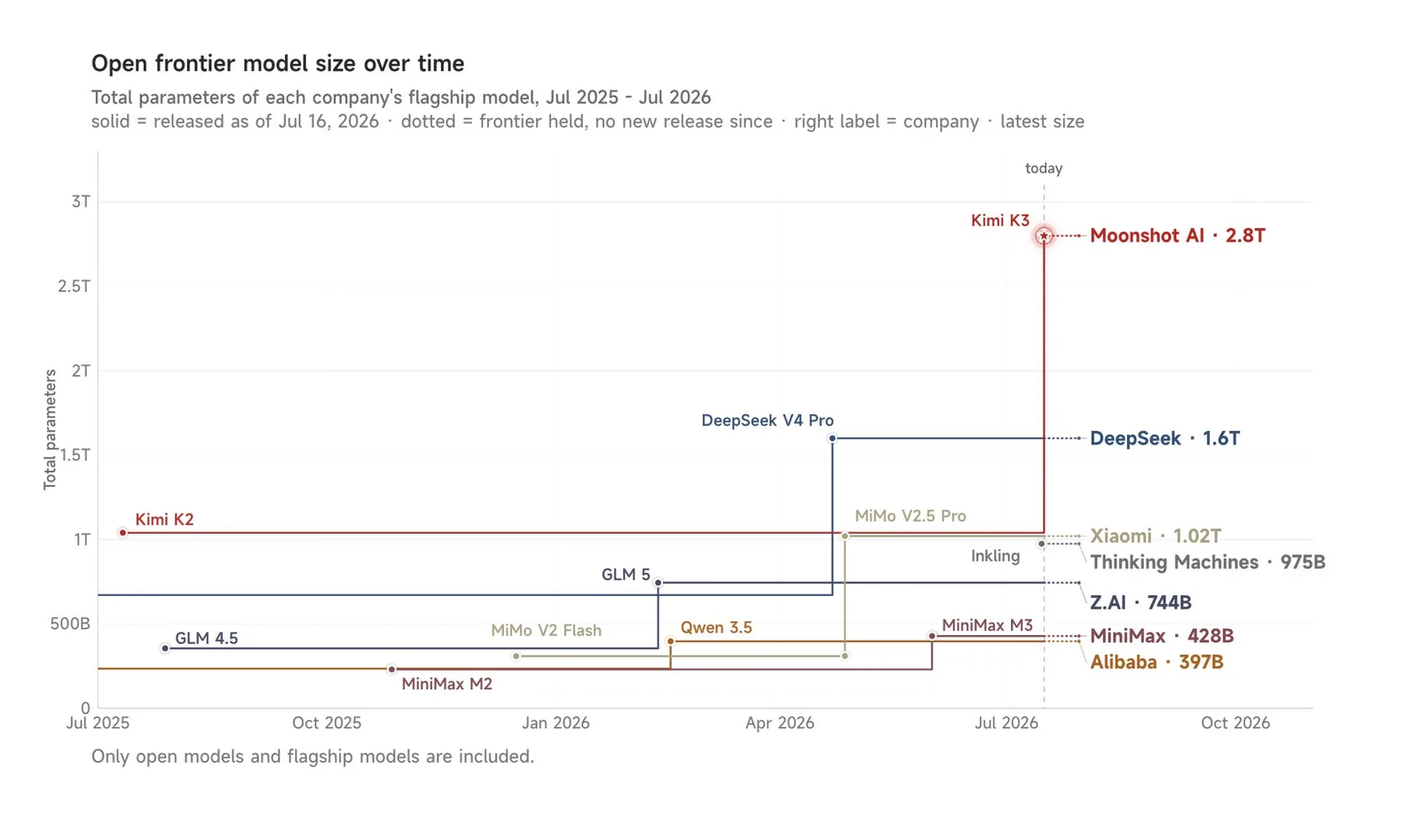
Moonshot AI presenta un modelo de 2,8 billones de parámetros con contexto de 1 millón de tokens y pesos abiertos prometidos para el 27 de julio, que ya lidera el ranking de código frontend.

Inkling es un modelo open-weight de 975.000 millones de parametros entrenado desde cero para entender texto, audio y video, y podria posicionar a la startup de Mira Murati frente a OpenAI y Anthropic.

El sistema de reconocimiento de voz tiene 2.000 millones de parámetros, se publica bajo licencia Apache 2.0 y ataca dialectos, mezcla árabe-inglés y vocabulario especializado.

Google presentó dos nuevos modelos de IA enfocados en alta velocidad, eficiencia de costos y capacidades avanzadas de edición de video y generación de imágenes.

Google DeepMind presenta Gemma 4 12B, un modelo de 12 mil millones de parámetros diseñado para ejecutar inteligencia multimodal avanzada directamente en tu laptop.

El modelo Mixture-of-Experts con 11B parámetros activos, contexto 256K y entrada multimodal nativa corre en NVIDIA NIM, TensorRT-LLM, vLLM y SGLang.

MMProLong, un modelo de 7B parámetros, supera a InternVL3-38B y Gemma3-27B en documentos de hasta 512.000 tokens entrenándose con pares pregunta-respuesta en vez de OCR puro.
Otros temas que aparecen junto a #multimodal en nuestra cobertura editorial.