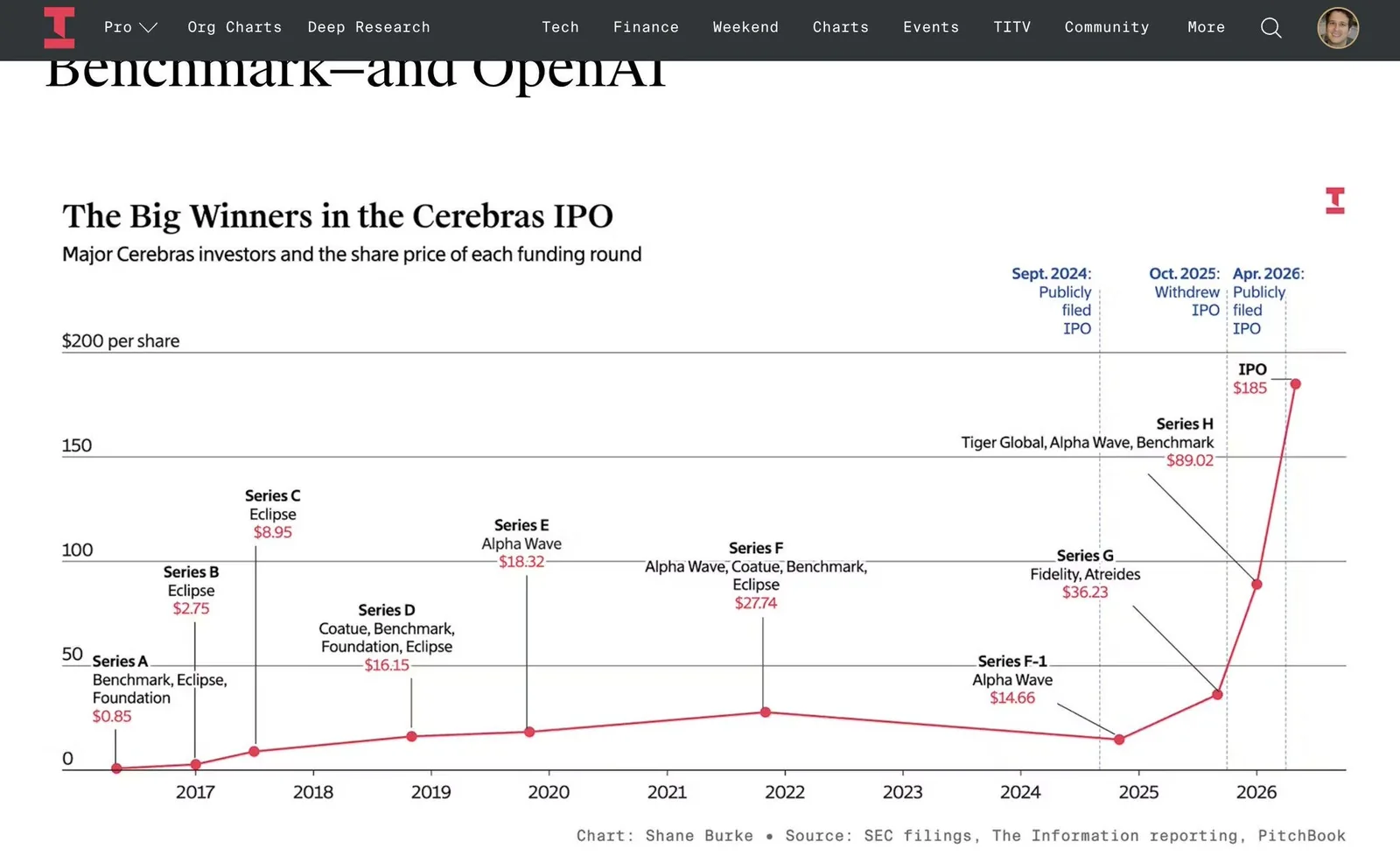
Si alguien estaba buscando el momento ideal para sacar a bolsa una empresa de chips, ser fabricante de semiconductores en mayo de 2026 es difícil de superar. Reuters reportó durante el fin de semana:
"Cerebras Systems se prepara para aumentar el tamaño y el precio de su oferta pública inicial tan pronto como el lunes, ya que la demanda por las acciones de la fabricante de chips de inteligencia artificial sigue al alza, dijeron dos personas familiarizadas con el asunto a Reuters el domingo. La compañía está considerando un nuevo rango de precio para su IPO de USD 150-160 por acción, frente a los USD 115-125 iniciales, y elevar el número de acciones colocadas de 28 a 30 millones, según las fuentes, que pidieron no ser identificadas porque la información aún no es pública."
El motor de fondo en la actual subida de las acciones de semiconductores es, por supuesto, la IA y, en particular, la constatación de que los agentes van a necesitar mucho cómputo. Pero lo que Cerebras representa va más allá: mientras la historia del cómputo para IA ha sido en gran parte sobre GPUs, particularmente las de Nvidia, el futuro va a ser cada vez más heterogéneo.
La era GPU
La historia de cómo las Graphics Processing Units terminaron en el centro de la IA está muy contada, pero en resumen:
- Así como dibujar pixeles en una pantalla es un proceso paralelo, lo que implica que hay una relación directa entre el número de unidades de procesamiento y la velocidad gráfica, los cálculos de IA también son paralelos, lo que implica la misma relación directa entre unidades y velocidad de cálculo.
- Nvidia habilitó este doble uso al hacer programables sus procesadores gráficos y creó todo un ecosistema de software llamado CUDA para que esa programación fuera accesible.
- La gran diferencia entre gráficos e IA ha sido el tamaño del problema a resolver: los modelos son mucho más grandes que las texturas de un videojuego. Eso llevó a una expansión drástica de la memoria de alto ancho de banda (HBM) por GPU y a innovaciones drásticas en networking chip-a-chip para que varios chips trabajen como un solo sistema direccionable. Nvidia ha liderado ambos frentes.
El caso de uso número uno de las GPUs ha sido entrenamiento, que estresa especialmente el tercer punto. Aunque los cálculos dentro de cada paso del entrenamiento son masivamente paralelos, los pasos en sí son seriales: cada GPU debe compartir su resultado con todas las demás antes de que comience el siguiente paso. Por eso un modelo de un billón de parámetros necesita caber en la memoria agregada de decenas de miles de GPUs que puedan comunicarse como un solo sistema. Nvidia domina ambos problemas, primero asegurando HBM por delante del resto de la industria y luego gracias a sus inversiones en networking.
Por supuesto, entrenamiento no es la única carga de IA: la otra es inferencia. La inferencia tiene tres partes principales:
- Prefill codifica todo lo que el LLM necesita saber en un estado entendible; es altamente paralelizable y acá manda el cómputo.
- La primera parte del decode implica leer la KV cache, que almacena contexto incluyendo la salida del prefill, para hacer un cálculo de atención. Este es un paso serial donde manda el ancho de banda, pero los requerimientos de memoria son variables y cada vez mayores.
- La segunda parte del decode es la computación feed-forward sobre los pesos del modelo; también es un paso serial donde manda el ancho de banda, y los requerimientos de memoria los define el tamaño del modelo.
Los dos pasos de decode se alternan en cada capa del modelo (están entrelazados, no en secuencia), lo que equivale a decir que decode es serial y está limitado por ancho de banda de memoria. Por cada token generado deben leerse dos pools distintos de memoria: la KV cache, que almacena contexto y crece con cada token, y los pesos del modelo. Ambos deben leerse en su totalidad para producir un solo token de salida.
Las GPUs cubren las tres necesidades: alta capacidad de cómputo para prefill, abundante HBM para KV cache y pesos del modelo, y networking chip-a-chip para juntar memoria a través de múltiples chips cuando una sola GPU no alcanza. Es decir, lo que sirve para entrenar sirve para inferir. Basta mirar el acuerdo de SpaceX con Anthropic. Desde el blog de Anthropic:
"Firmamos un acuerdo con SpaceX para usar toda la capacidad de cómputo de su data center Colossus 1. Esto nos da acceso a más de 300 megawatts de nueva capacidad (más de 220.000 GPUs NVIDIA) dentro del mes. Esta capacidad adicional mejorará directamente la capacidad para suscriptores de Claude Pro y Claude Max."
SpaceX se queda con Colossus 2 (presumiblemente para entrenar modelos futuros y para inferir los actuales) y puede hacer ambas cosas en el mismo data center precisamente porque los modelos de xAI no tienen tanto uso. Más relevante para este análisis: pueden hacer ambas cosas en el mismo data center porque tanto entrenamiento como inferencia se pueden hacer en GPUs. De hecho, las GPUs que Anthropic contrata en Colossus 1 originalmente estaban destinadas a entrenamiento; que las GPUs sean tan flexibles es una ventaja enorme.
Entender a Cerebras
Cerebras hace algo completamente distinto. Aunque una oblea de silicio tiene 300 mm de diámetro, el reticle limit (la máxima área que una herramienta de litografía puede exponer en esa oblea) es de unos 26 mm × 33 mm. Ese es el límite efectivo de tamaño para un chip; ir más allá implica unir dos chips separados sobre un interposer chip-a-chip, que es exactamente lo que hizo Nvidia con la B200. Cerebras, en cambio, inventó una manera de tender cableado a través de las llamadas scribe lines (las fronteras entre exposiciones de reticle), convirtiendo la oblea entera en un solo chip sin necesidad de enlaces relativamente lentos entre chips.
El resultado neto es un chip con muchísimo cómputo y mucha SRAM accesible a velocidad descomunal. En cifras: el WSE-3 (el último chip de Cerebras) tiene 44 GB de SRAM on-chip a 21 PB/s de ancho de banda; una H100 tiene 80 GB de HBM a 3,35 TB/s. Es decir, el WSE-3 tiene poco más de la mitad de memoria que una H100, pero 6.000 veces el ancho de banda de memoria.
El sentido de comparar el WSE-3 con la H100 es que la H100 es el chip más usado para inferencia, y la inferencia es claramente para lo que el chip de Cerebras está mejor preparado. Se pueden usar chips Cerebras para entrenar, pero la historia de networking chip-a-chip no es muy atractiva. Lo que sí es mucho más interesante es la idea de obtener un stream de tokens a velocidad dramáticamente mayor que la de una GPU.
Conviene notar, sin embargo, que el límite que aparece en entrenamiento potencialmente aplica también en inferencia: mientras todo quepa en la memoria on-chip, la velocidad de Cerebras es una experiencia impresionante; en el momento en que se necesita más memoria (sea por un modelo más grande o, más probable, por una KV cache más grande) Cerebras deja de tener sentido, sobre todo dado el precio. La técnica de oblea-entera-como-chip implica que rendimientos altos son un desafío masivo, lo que dispara los costos.
Al mismo tiempo, sí va a haber mercado para chips estilo Cerebras: ahora mismo la compañía destaca la utilidad de la velocidad para coding. Razonar implica muchos tokens, lo que implica que escalar dramáticamente los tokens-por-segundo equivale a un pensamiento más rápido. Yo creo que es un caso de uso temporal, por razones que explicaré más abajo. Lo que sí va a importar de manera durable es cuánto tiempo espera un humano por una respuesta, y a medida que productos como los AI wearables se vuelvan más comunes, la velocidad de interacción (sobre todo para voz) tendrá un efecto tangible sobre la experiencia del usuario.
Inferencia agentic
Ya he argumentado antes, incluido en Agents Over Bubbles, que pasamos por tres puntos de inflexión en la era LLM:
- ChatGPT demostró la utilidad de la predicción de tokens.
- o1 introdujo la idea de reasoning, donde más tokens implican mejores respuestas.
- Opus 4.5 y Claude Code introdujeron los primeros agentes usables, capaces efectivamente de cumplir tareas, usando una combinación de modelos de razonamiento y un harness que utilizaba herramientas, verificaba el trabajo, etc.
Todo esto cae bajo el paraguas de la inferencia, pero creo que va a ser cada vez más evidente que hay una diferencia entre entregar una respuesta (lo que llamaré "inferencia de respuesta") y ejecutar una tarea (lo que llamaré "inferencia agentic"). El mercado objetivo de Cerebras es la inferencia de respuesta; en el largo plazo, creo que la arquitectura para inferencia agentic va a verse muy distinta, no sólo del approach de Cerebras sino también del approach GPU.
Mencioné arriba que la inferencia rápida para coding es un caso de uso temporal. Específicamente, codear con LLMs requiere un humano en el loop. Es el humano quien define qué hay que codear, revisa el trabajo, hace commit al pull request, etc. No es difícil imaginar un futuro, sin embargo, donde todo eso esté completamente manejado por máquinas. Esto va a aplicar al trabajo agentic en sentido amplio: el verdadero poder de los agentes no estará en hacer trabajo para humanos, sino en hacer trabajo sin involucrar humanos en absoluto.
Por extensión, esto implica que el mejor approach para resolver inferencia agentic va a verse muy distinto del de inferencia de respuesta. El aspecto más importante para la inferencia de respuesta es la velocidad de tokens; el aspecto más importante para la inferencia agentic, en cambio, es la memoria. Los agentes necesitan contexto, estado e historia. Parte de eso vivirá como KV cache activa; parte vivirá en memoria host o SSDs; mucho vivirá en bases de datos, logs, embeddings y object stores. El punto importante es que la inferencia agentic va a tratar menos sobre GPUs respondiendo una pregunta y más sobre la jerarquía de memoria envuelta alrededor del modelo.
Críticamente, esta articulación de una jerarquía de memoria específica para agentes implica un trade-off necesario de velocidad por capacidad. Pero acá está la clave: la velocidad más baja no es una consideración tan importante si no hay un humano en el loop. Si un agente está esperando por un job que se está corriendo durante la noche, al agente no le importa el impacto en experiencia de usuario. Lo más importante es poder cumplir la tarea, y si approaches completamente nuevos de memoria lo hacen posible, los delays están bien.
Por otro lado, si los delays están bien, entonces todo el foco en puro poder de cómputo y memoria de alto ancho de banda parece fuera de lugar. Si la latencia no es la prioridad, entonces memoria más lenta y barata (DRAM tradicional, por ejemplo) tiene mucho más sentido. Y si el sistema entero pasa la mayor parte del tiempo esperando memoria, entonces los chips tampoco tienen que estar en la frontera. Esto representa un cambio profundo en arquitecturas futuras, pero tampoco significa que las arquitecturas actuales vayan a desaparecer:
- El entrenamiento va a seguir importando, y la arquitectura actual de Nvidia (cómputo de alta velocidad, gran cantidad de memoria de alto ancho de banda y networking de alta velocidad) probablemente va a seguir dominando.
- La inferencia de respuesta será un mercado relevante, aunque relativamente pequeño, y la velocidad de chips como los de Cerebras o Groq (cómo Nvidia está desplegando las LPUs de Groq lo expliqué acá) va a resultar muy útil.
El resto del análisis sigue en el original detrás del paywall de Stratechery.