Perdón por empezar con un cliché del lenguaje financiero que se coló en el léxico tecnológico, pero hay que hablar de "fosos". El término lo popularizó Warren Buffett hace décadas para describir la ventaja competitiva de una empresa, y aterrizó en los pitch decks de Silicon Valley cuando un memo filtrado de Google, titulado "No tenemos foso, y OpenAI tampoco", advertía que la IA open source iba a saquear el castillo de las Big Tech.
Un par de años después, las murallas siguen en pie. Salvo un breve episodio de pánico cuando apareció DeepSeek, los modelos de IA open source no han superado masivamente a los propietarios. Aun así, ninguno de los laboratorios de frontera (OpenAI, Anthropic, Google) tiene un foso digno de ese nombre.
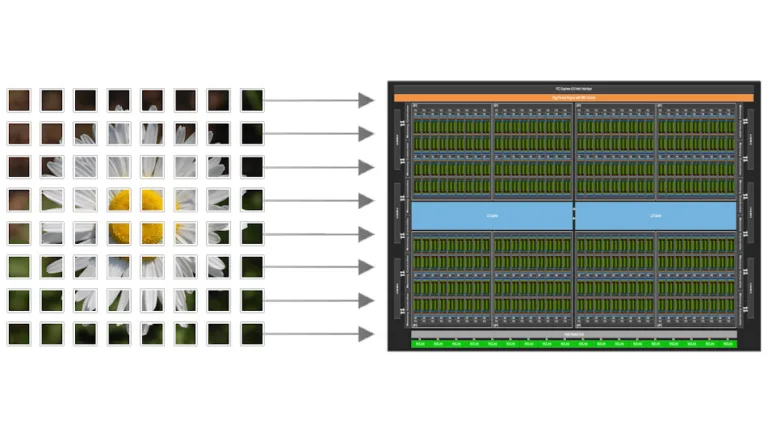
La empresa que sí lo tiene es Nvidia. Su CEO, Jensen Huang, lo describe como su "tesoro" más preciado. Y no es, como uno supondría tratándose de una compañía de chips, una pieza de hardware. Se llama CUDA. Lo que suena a compuesto químico prohibido por la FDA puede ser el único foso real de la IA.
CUDA significa técnicamente Compute Unified Device Architecture, pero igual que ocurre con laser o scuba, nadie se molesta en expandir la sigla; solo decimos "KOO-da". ¿Para qué sirve este tesoro? Si hay que responder en una palabra, paralelización.
Un ejemplo simple: la tabla de multiplicar

Supongamos que pedimos a una máquina que complete una tabla de multiplicar de 9×9. Con un computador de un solo núcleo, las 81 operaciones se ejecutan una tras otra. Pero una GPU con nueve núcleos puede asignar tareas para que cada núcleo tome una columna distinta (uno hace de 1×1 a 1×9, otro de 2×1 a 2×9, y así sucesivamente), logrando una mejora de nueve veces. Las GPUs modernas pueden ser todavía más ingeniosas. Si se les programa para reconocer la conmutatividad (7×9 = 9×7), evitan trabajo duplicado y reducen las 81 operaciones a 45, casi la mitad. Cuando un entrenamiento cuesta cien millones de dólares, cada optimización pesa.
Las GPUs de Nvidia se diseñaron originalmente para renderizar gráficos de videojuegos. A inicios de los 2000, un estudiante de doctorado de Stanford llamado Ian Buck, que se acercó a las GPUs como gamer, se dio cuenta de que su arquitectura podía servir para computación de alto rendimiento de propósito general. Creó un lenguaje de programación llamado Brook, fue contratado por Nvidia y, junto a John Nickolls, lideró el desarrollo de CUDA. Si la IA termina inaugurando la era de una clase trabajadora administrativa permanente y de armas autónomas, sepan que todo arrancó porque alguien, en algún lugar, jugando Doom, pensó que el escroto de un demonio debía rebotar a 60 cuadros por segundo.
CUDA es una "plataforma", no un lenguaje
CUDA no es un lenguaje de programación en sí mismo, sino una "plataforma". Uso esa palabra comodín porque, igual que The New York Times es un diario que también es una empresa de juegos, CUDA se transformó con los años en un paquete anidado de bibliotecas de software para IA. Cada función ahorra nanosegundos en una operación matemática puntual; sumadas, hacen que las GPUs vuelen.
Una tarjeta gráfica moderna no es solo una placa repleta de chips, memoria y ventiladores. Es un entramado elaborado de jerarquías de caché y unidades especializadas llamadas tensor cores y streaming multiprocessors. En ese sentido, lo que las empresas de chips venden es algo parecido a una cocina profesional, y más núcleos equivalen a más estaciones de parrilla. Pero ni siquiera una cocina con 30 parrillas funcionará más rápido sin un chef capaz que asigne las tareas con destreza, exactamente lo que hace CUDA con los núcleos de la GPU.
Llevando la metáfora más lejos, las bibliotecas CUDA ajustadas a mano para una operación matricial específica son el equivalente a utensilios de cocina diseñados para una sola tarea (un deshuesador de cerezas, un descabezador de camarones): un capricho en una cocina casera, pero no si hay que limpiarles las tripas a 10.000 camarones. Y eso nos devuelve a DeepSeek. Sus ingenieros bajaron por debajo de esa capa de abstracción ya profunda y trabajaron directamente en PTX, una especie de ensamblador para GPUs Nvidia. Si la tarea es pelar ajo, una GPU sin optimizar diría: "Saca la cáscara con las uñas". CUDA puede instruir: "Aplasta el diente con el costado del cuchillo". PTX permite dictar cada sub-instrucción: "Levanta la hoja 2,35 pulgadas sobre la tabla, ponla paralela al ecuador del diente y golpea hacia abajo con la palma a una fuerza de 36,2 newtons".
Empieza a notarse por qué CUDA es tan valiosa para Nvidia, y tan difícil de tocar para cualquier otro. Afinar el rendimiento de una GPU es un problema feo. No se puede reclutar a un estudiante de pregrado cualquiera en Market Street, pasarle una suscripción Claude Max y esperar que hackee kernels de GPU. Escribir a ese nivel es un trabajo arduo, salvo que seas un programador de élite en DeepSeek.
Una multiplicación de matrices simple que en PyTorch (un framework popular de machine learning) me toma tres líneas, me tomó más de 50 líneas en CUDA. Exprimirle la última gota de rendimiento al hardware es un negocio admirable pero tedioso. Habiendo metido un pie en el foso, puedo confirmar que es profundo y hostil.
El efecto lock-in: por qué AMD rinde menos con más núcleos
El dominio de CUDA se sostiene no solo en la calidad de su ecosistema, sino también en un efecto de bloqueo. Como los frameworks modernos de machine learning están construidos sobre CUDA, que solo corre en chips Nvidia, los chips AMD rinden menos incluso cuando tienen más núcleos y más memoria. Comparar chips por planilla de especificaciones es como comparar autos de carrera por número de cilindros: el rendimiento real solo se mide en la pista.
La ventaja de Nvidia en software pasa, en parte, por algo inusual en una empresa de chips: contrata más ingenieros de software que de hardware. Si yo dirigiera AMD, haría lo mismo. (Aunque nadie me lo está preguntando.)
Cada año aparecen nuevos aspirantes que intentan drenar el foso de Nvidia, y se ahogan en él. OpenCL, un estándar abierto respaldado por un consorcio que incluyó a Apple, AMD y Qualcomm, fue una especie de Android frustrado frente al iOS de CUDA. Apenas pegó.
ROCm, la respuesta de AMD a CUDA, tiene un nombre todavía peor (¿se pronuncia "rock cum"?). Y ha estado tan plagado de bugs y problemas de compatibilidad que su subreddit parece un grupo de apoyo.
Tampoco hay que olvidar a Intel. Aunque es fácil descartarla como una fabricante de chips en decadencia, su historia reciente revela que también es una empresa de software en problemas. En un último intento por mantenerse relevante lanzó oneAPI, pero a 2026 sabemos con certeza que CUDA sigue reinando. Si hay algún desafiante, es Modular, liderado por Chris Lattner, el legendario diseñador de lenguajes que tiene en su currículum a Swift de Apple y a LLVM.
El cuello de botella humano: faltan ingenieros de kernel
Pero el secreto a voces es que, así como los físicos teóricos suelen no saber cambiar una llanta, la mayoría de los investigadores de IA es incapaz de escribir una sola línea de C++. Hay muy pocos buenos ingenieros de kernels de GPU vivos, y muchos están contratados por Nvidia. Mucho antes de que los investigadores de IA empezaran a transar reputación, estos ingenieros llevaban años trabajando en CUDA sin reconocimiento. Incluso los agentes de programación más confiables aún se traban en el código de kernels.
Nvidia, al final, está más cerca de Apple que de AMD o Intel. Es una gran empresa de hardware porque es una empresa de software. El foso de Apple contra Android nunca fue solo el iPhone, sino el ecosistema: iOS, la App Store y sus desarrolladores. Claro, se puede doblar un Samsung Galaxy por la mitad, pero ¿realmente quieres usar Samsung Pay? Mientras tanto, a la industria le va a tocar convivir con los precios ofensivos de Nvidia.
¿Qué significa esto para Chile y LatAm?
Para integradores chilenos y latinoamericanos que arman infraestructura de inferencia, la lección es operativa: comprar AMD MI300 o Intel Gaudi por TFLOPs nominales casi nunca rinde lo que la planilla sugiere si el stack de software arriba es PyTorch o vLLM. La práctica recomendada sigue siendo benchmarkear con cargas reales, no fiarse de las especificaciones, y reservar las GPUs no-Nvidia para cargas controladas donde el equipo pueda invertir semanas en portar kernels.