NVIDIA MCG: model cards automáticas con GPT-OSS-120B
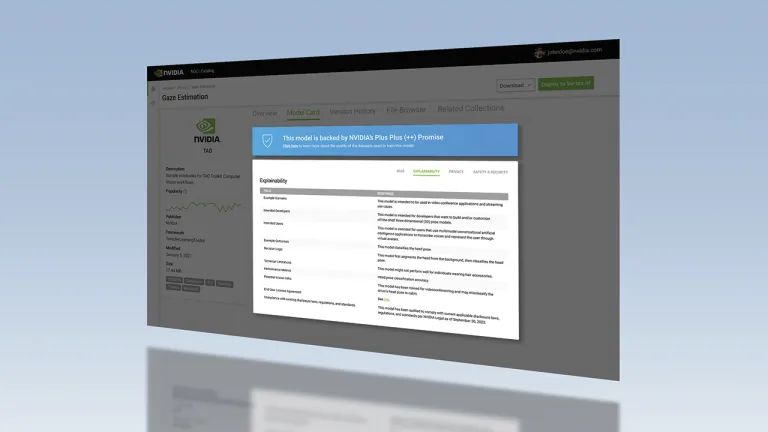
El toolkit Model Card Generator de NVIDIA construye documentación completa en formato Model Card++ a partir del código fuente, con 91% de completitud y 76% de precisión en menos de un minuto.
NVIDIA Developer