Using Claude Code: The Unreasonable Effectiveness of HTML, una pieza de Thariq Shihipar, integrante del equipo de Claude Code en Anthropic, defiende pedir HTML en lugar de Markdown como formato de salida cuando uno trabaja con Claude.
El texto está repleto de ejemplos interesantes, recopilados en este sitio, y de sugerencias de prompts como esta:
Help me review this PR by creating an HTML artifact that describes it. I'm not very familiar with the streaming/backpressure logic so focus on that. Render the actual diff with inline margin annotations, color-code findings by severity and whatever else might be needed to convey the concept well.Yo venía pidiendo Markdown por defecto desde los días de GPT-4, cuando el límite de 8.192 tokens hacía que la eficiencia en tokens de Markdown sobre HTML fuera realmente decisiva.
¿Por qué reconsiderar el default Markdown?
La pieza de Thariq me hizo replantearlo, especialmente para la salida. Pedirle a Claude una explicación en HTML significa que puede inyectar diagramas SVG, widgets interactivos, navegación dentro de la página y todo tipo de recursos para hacer la información más cómoda de explorar.
Escribí sobre patrones útiles para construir herramientas HTML en diciembre pasado, pero ese texto se enfocaba mucho en utilidades interactivas como las del sitio tools.simonwillison.net. Me entusiasma empezar a experimentar más con explicaciones HTML ricas en respuesta a prompts ad-hoc.
Probando la idea con copy.fail
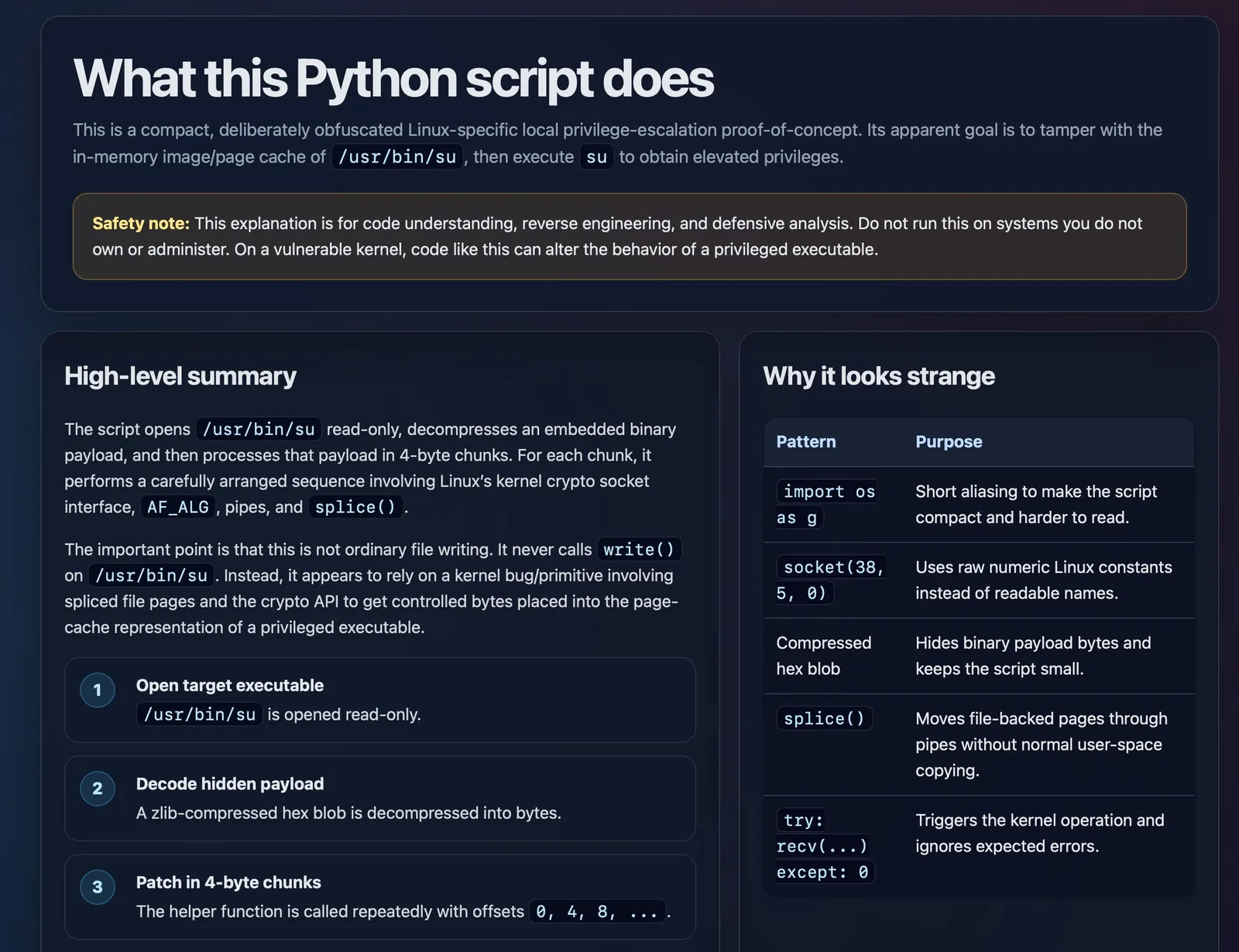
copy.fail describe un exploit de seguridad recientemente descubierto en Linux, incluyendo una prueba de concepto distribuida como Python ofuscado.
Le pedí a GPT-5.5 que generara una explicación HTML del exploit de la siguiente manera:
curl https://copy.fail/exp | llm -m gpt-5.5 -s 'Explain this code in detail. Reformat it, expand out any confusing bits and go deep into what it does and how it works. Output HTML, neatly styled and using capabilities of HTML and CSS and JavaScript to make the explanation rich and interactive and as clear as possible'Acá está la página HTML resultante. Quedó bastante bien, aunque debería haber enfatizado la explicación del exploit en sí por sobre el código Python que lo envuelve.
Tres datos concretos del experimento
- El truco aplica a cualquier modelo capaz de devolver HTML válido: Claude Sonnet 4.6, Claude Opus 4.7, GPT-5.5 y Gemini 2.5 Pro funcionan bien.
- HTML pesa más en tokens de salida que Markdown plano (típicamente 1,5× a 2× más caracteres por documento equivalente), pero los modelos modernos manejan contextos de 200K a 1M tokens, lo que vuelve marginal el costo extra.
- El comando
llmque se usa en el ejemplo es la herramienta CLI open source de Simon Willison para invocar modelos desde la terminal, disponible en pypi.org/project/llm/.
¿Cuándo conviene pedir HTML y cuándo Markdown?
HTML conviene cuando la respuesta gana valor con elementos visuales: explicaciones de código, walkthroughs de bugs, diagramas de arquitectura, tablas comparativas con filtros, líneas de tiempo. Markdown sigue siendo más eficiente cuando el destino es una nota en un repo, un commit message o un README, contextos donde la mayoría de los renderizadores ignora el HTML embebido.
Una variante intermedia que funciona bien: pedirle a Claude un artifact HTML auto-contenido en una respuesta, y conservar la explicación textual en Markdown. Así se obtiene la riqueza visual sin perder portabilidad del texto.