Los modelos de lenguaje grandes (LLMs) están transformando el trading financiero al habilitar análisis sofisticado de grandes volúmenes de datos no estructurados (noticias financieras, sentiment de redes sociales, reportes de utilidades, datos de mercado) para anticipar movimientos bursátiles y automatizar estrategias de inversión con una precisión sin precedentes.
El Strategic Technology Analysis Center (STAC) lleva más de 15 años desarrollando benchmarks para los workloads críticos de la industria financiera. Ahora liberó el benchmark STAC-AI, pensado para que las empresas evalúen el pipeline end-to-end de retrieval-augmented generation (RAG) e inferencia de LLMs.
Este artículo resume los resultados que NVIDIA obtuvo en el benchmark STAC-AI LANG6 sobre varias plataformas y entrega recomendaciones para que cualquier usuario reproduzca las mediciones de TensorRT LLM según las especificaciones de su propio dataset.
¿Qué mide STAC-AI LANG6?
Dentro del pipeline RAG, STAC-AI LANG6 es la pieza del benchmark enfocada en rendimiento de inferencia. Prueba el stack de hardware y software con Llama 3.1 8B Instruct y Llama 3.1 70B Instruct sobre dos datasets propios:
- EDGAR4: prompts de resumen sobre la relación de una empresa con conceptos físicos y financieros (commodities, divisas, tasas de interés, sectores inmobiliarios). Usa párrafos de un único 10-K de la base EDGAR. Modela requests de longitud media.
- EDGAR5: preguntas que cubren varios aspectos de un 10-K completo. Modela requests de contexto largo.
Ambos datasets, basados en filings de EDGAR, simulan resúmenes de informes anuales (10-K) de miles de empresas públicas de los últimos cinco años, para casos de uso de trading y asesoría de inversión.
El benchmark también prueba dos escenarios de inferencia:
- Batch (offline): todas las requests se entregan a la vez y todas las respuestas se recolectan al final. Solo se mide throughput.
- Interactivo (online): las requests llegan en tiempos pseudo-aleatorios. La tasa media de arribo λ se ajusta para simular distintos escenarios de uso. Se miden reaction time (RT, análogo al time to first token), palabras por segundo totales (WPS) y output rate por usuario (WPS/user).
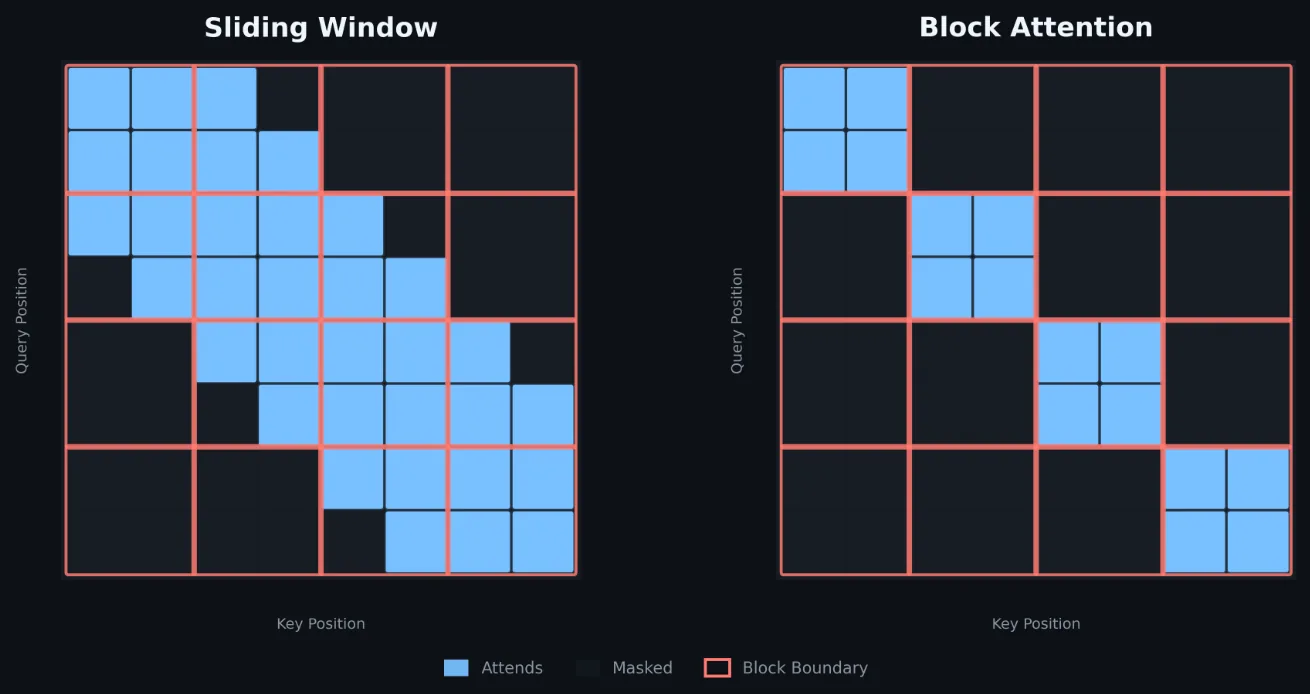
Una diferencia clave de STAC-AI vs otros benchmarks: exige aplicar templates de chat y tokenizar las requests durante la inferencia, no como preprocesamiento. Eso suma carga real al servidor, replicando deployments productivos donde el prompt del sistema se protege server-side.
¿Qué hardware probó NVIDIA?
Las plataformas auditadas fueron tres:
- HPE ProLiant Compute DL384 Gen12, on-premises, equipado con el NVIDIA GH200 Grace Hopper Superchip. Configuración de servidor único eficiente.
- NVIDIA HGX B200 en una instancia cloud de Lambda, con ocho GPUs Blackwell B200 conectadas por NVLink y NVSwitch. Cada B200 incluye 180 GB de memoria HBM3e y 8 TB/s de ancho de banda para inferencia de modelos grandes.
- Supermicro AS-5126GS-TNRT con dos GPUs NVIDIA RTX PRO 6000 Blackwell Server Edition, 96 GB de memoria por GPU. Stack desplegado sobre Red Hat OpenShift, lo que confirma que la plataforma Kubernetes containerizada no introduce overhead medible en cargas de inferencia GPU.
La cuantización post-entrenamiento, requerida por el benchmark, se hizo con NVIDIA TensorRT Model Optimizer. Los modelos quedaron en FP8 en Hopper y en NVFP4 en Blackwell, aprovechando los kernels más performantes de cada arquitectura. La ejecución se hizo con el runtime PyTorch de TensorRT LLM.
Resultados: ¿cuánto más rápido es Blackwell?
En modo batch, NVIDIA Blackwell entrega aceleraciones significativas en todos los escenarios. La métrica clave es WPS (words per second) y RPS (requests per second).

Aunque STAC-AI no mide rendimiento por GPU directamente, NVIDIA derivó esa métrica normalizando por el número de GPUs en cada sistema. El resultado: hasta 2,8x más throughput por GPU del HGX B200 frente al GH200.
En modo interactivo, el balance entre economía de tokens (que depende del throughput) y experiencia de usuario (que depende de métricas de interactividad como RT y WPS/user) es crítico. Para simplificar la visualización, NVIDIA usa el inverso de WPS/user, definido como interword latency (IWL).

El HGX B200 logra un mejor trade-off entre throughput y ambas métricas de interactividad (RT e IWL) en todos los escenarios probados. Los informes completos publicados por STAC tienen el detalle granular.
¿Cómo replicar el benchmark con tus propios datos?
NVIDIA documenta un flujo para correr TensorRT LLM contra modelos ajustados a las características de tu dataset. Los prerrequisitos:
- Una imagen Docker con TensorRT LLM release.
- Una GPU NVIDIA suficiente para servir el modelo al nivel de cuantización deseado. La matriz de soporte está en la documentación de TensorRT LLM.
- Cuenta y token de Hugging Face con acceso a Llama 3.1 8B Instruct o Llama 3.1 70B Instruct, expuesto vía la variable de entorno
HF_TOKEN.
El primer paso es levantar el contenedor en una máquina con GPUs NVIDIA. Los contenedores mantenidos por NVIDIA traen todas las dependencias preinstaladas. La guía completa de cuantización, preparación de dataset y corrida del benchmark está en el post original de NVIDIA Developer Blog.