Thinking Machines, el laboratorio fundado por Mira Murati tras su salida de OpenAI, presentó este lunes su primer modelo de investigación: TML-Interaction-Small, un modelo nativo de interacción en tiempo real entrenado desde cero, no a partir de un LLM al que se le inyecta voz y turnos. El anuncio aparece en su blog técnico y marca apenas la tercera publicación pública de la startup desde su fundación.
La arquitectura es un Mixture-of-Experts de 276 mil millones de parámetros totales con 12 mil millones activos por token, optimizado para procesar audio, video y texto de manera simultánea y sin separar etapas. El equipo lo describe como un cambio de tipo: la firma del sistema deja de ser texto a texto y pasa a ser audio+video+texto a audio+texto, todo continuo en el tiempo.
¿Qué hace distinto a TML-Interaction-Small?

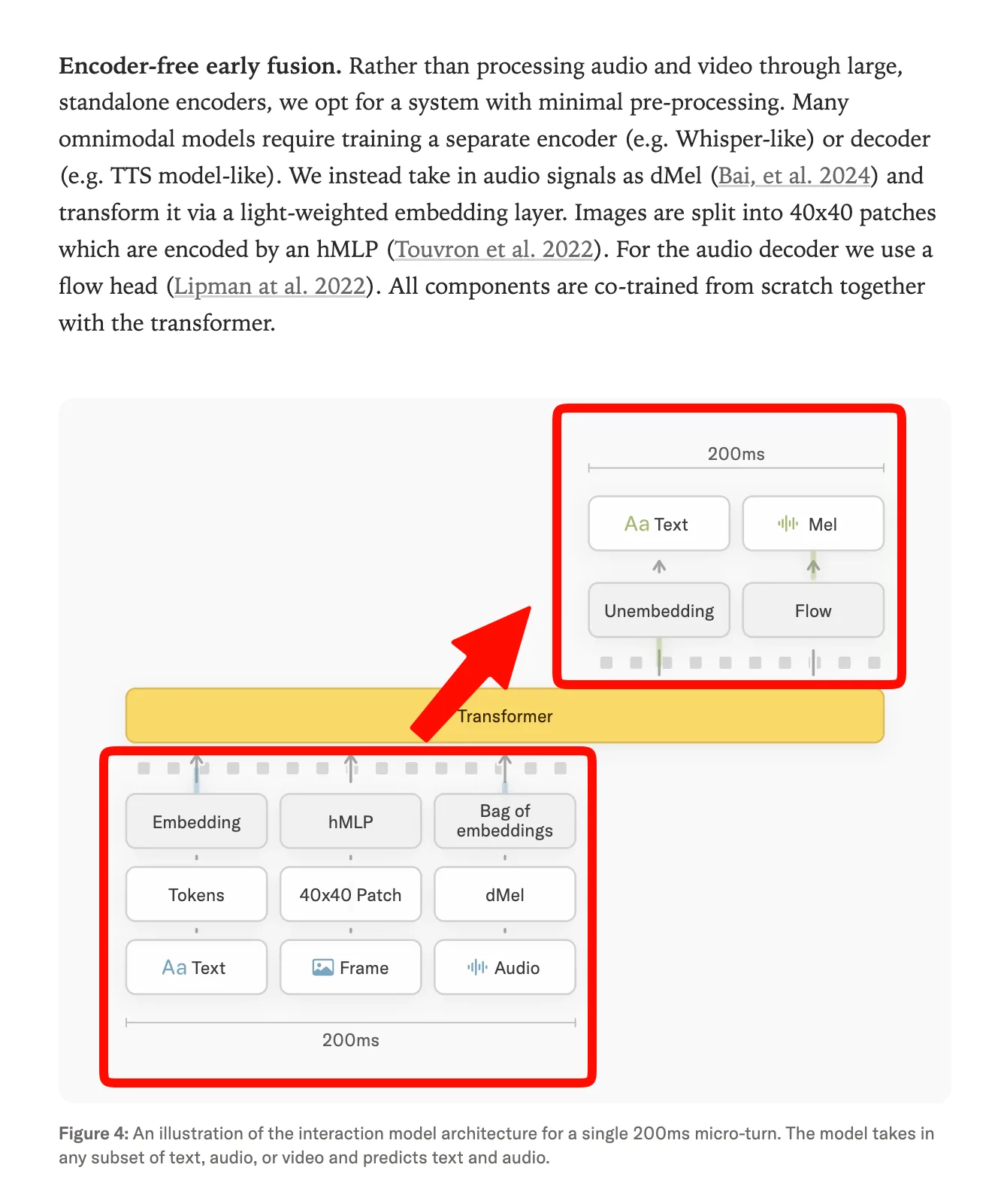
El núcleo es lo que Thinking Machines llama microturnos de 200 milisegundos alineados en el tiempo. El modelo no espera a que el usuario termine de hablar para responder, ni anuncia "ahora estoy pensando, ahora estoy buscando" como hacen los agentes actuales. Escucha, mira y responde en paralelo, con interrupciones permitidas en ambos sentidos. La fusión usa encoder-free early fusion, similar al enfoque que Meta propuso con Chameleon: imágenes y audio se procesan en menos de 200 ms.
¿Cómo se compara con GPT-Realtime-2 y Gemini 3.1-Flash?
Los benchmarks publicados por la propia compañía muestran que TML-Interaction-Small supera a GPT-Realtime-2 de OpenAI y a Gemini 3.1-Flash de Google en pruebas estándar de audio como BigBench Audio, IFEval y FD-bench. Pero como el equipo apunta a una experiencia que va más allá del benchmark clásico de voz, también construyó dos pruebas nuevas:
- TimeSpeak: el modelo debe iniciar habla en momentos específicos sin que el usuario lo invoque. Ejemplo: "recuérdame respirar cada cuatro segundos hasta que te diga basta".
- CueSpeak: el modelo debe hablar en el momento adecuado según un evento contextual. Ejemplo: "cada vez que cambie de idioma, dame la palabra correcta en el idioma original".
Además adapta tres benchmarks de visión existentes: RepCount-A para conteo continuo de repeticiones, ProactiveVideoQA para responder en el momento exacto cuando la respuesta se vuelve visible, y Charades para localización temporal de acciones.
Detalles de implementación y roadmap
Un detalle filtrado por miembros del equipo en X es que el stack de inferencia corre sobre SGLang, el motor open source que ya usa parte del ecosistema de modelos abiertos. El blog también deja entrever que el siguiente paso es emparejar estos modelos interactivos con agentes en segundo plano, lo que en la práctica significaría que un asistente puede hablar contigo mientras un agente trabaja en otra tarea sin interrumpir el diálogo.
Para el ecosistema chileno y latinoamericano la noticia tiene una lectura concreta. Hoy las experiencias estilo "asistente con voz" dependen de stacks de OpenAI o Google con latencia variable y costos altos por minuto. Si Thinking Machines libera el modelo o un API competitivo, integradores locales podrían replicar la interacción tipo "her" sobre un Jetson Orin Nano AGX o un servidor con dos GPUs H100, con audio bidireccional sin las pausas artificiales típicas del push-to-talk actual.