Leer un libro sobre bolos no es lo mismo que jugar bolos. Si esa idea te resuena y querés aprender más sobre modelos de lenguaje de gran escala (LLMs), vale la pena revisar el proyecto LLM From Scratch, mantenido por Angelos Papoutsakis en GitHub.
El workshop hands-on permite usar un Mac, Linux o Windows PC con Python y librerías comunes como numpy y torch para construir un LLM básico de cero. La promesa es seria y al mismo tiempo modesta: no vas a salir con un GPT-5, pero vas a entender por dentro cada componente que hace que un GPT-5 funcione.
¿Qué hay dentro del workshop?
El proyecto se inspira en nanoGPT de Andrej Karpathy, pero está escalado hacia abajo para que el entrenamiento completo tome alrededor de una hora en un computador típico. Si tenés una GPU de Apple Silicon o NVIDIA disponible, el código la aprovecha automáticamente; si no, corre sobre CPU y termina igual.
El workshop está dividido en seis partes secuenciales:
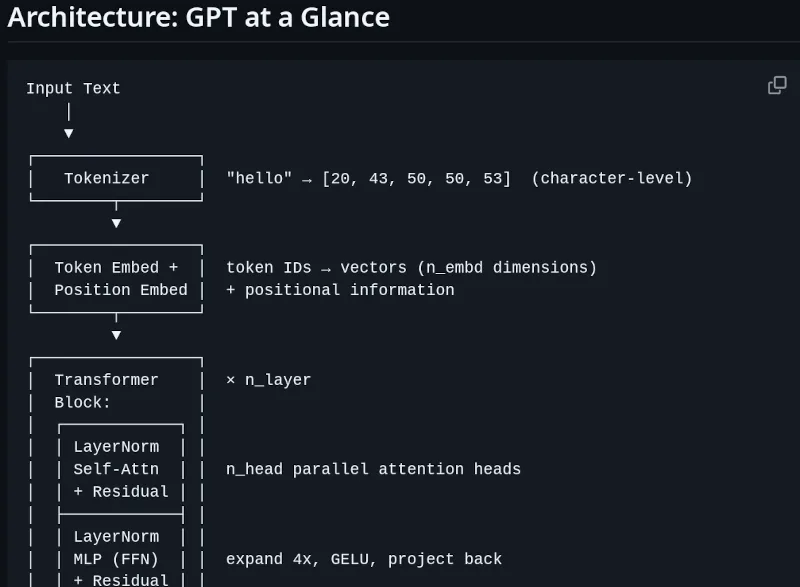
1. Tokenizer: cómo se convierte texto a tokens, qué es BPE y por qué importa el tamaño de vocabulario. 2. Transformer: la arquitectura de atención multi-head y feed-forward que define el modelo. 3. Training loop: el bucle de entrenamiento con optimizador, loss y backpropagation. 4. Text generation: cómo se hace inference, sampling con temperatura y top-k. 5. Train the model: la corrida completa que produce los pesos finales. 6. Find the best AI poet: una parte de cierre que evalúa el modelo entrenado generando poesía y comparando salidas.
La sección de referencias incluye papers clásicos sobre transformers, escalamiento y eficiencia de entrenamiento. Algunos los habrás visto antes (el original "Attention Is All You Need" entre ellos), otros pueden ser hallazgos nuevos.
¿Por qué importa este tipo de proyecto?
Hay tres razones concretas por las que vale la pena correr un workshop como este antes de aplicar LLMs en producción:
- Costo cero de error: equivocarse con un mini-LLM de juguete no quema tokens en una API de pago. Podés probar tokenizadores raros, cambiar el optimizador, romper el bucle de entrenamiento y reiniciar.
- Intuición de escala: cuando entrenás un modelo de 10 millones de parámetros en una hora, las cifras de GPT-5 (varios trillones de parámetros, miles de GPUs, semanas de entrenamiento) dejan de ser abstractas y empiezan a tener proporción.
- Debugging real: muchos errores cotidianos de prompt engineering se vuelven obvios cuando entendés cómo el tokenizer parte palabras y cómo el transformer atiende contextos cortos.
El reportaje original aparece en Hackaday, que aprovecha de recomendar otros enfoques didácticos sobre IA: un walkthrough animado de cómo funcionan los LLMs, una guía para aprender IA en una planilla de cálculo y aproximaciones desde primeros principios a otros temas de bajo nivel. Para quien aprende mejor con las manos sobre el código, este tipo de recursos es preferible a otra hora de tutoriales en YouTube.